Clear Sky Science · es
Control MIMO no lineal adaptativo difuso para robots multibody rígidos acoplados usando un modelo de aprendizaje por refuerzo
Robots que pueden aprender en el trabajo
Los robots están saliendo de las líneas de producción valladas y entrando en hospitales, almacenes e incluso en nuestros hogares. En estos entornos desordenados, sus cargas cambian, los suelos no son perfectamente planos y las personas pueden empujarlos. Este artículo explora una nueva forma de dotar a robots con múltiples articulaciones —como brazos y máquinas que andan— de la capacidad de mantener sus movimientos suaves, precisos y estables incluso cuando el entorno es impredecible y sus propios cuerpos cambian con el tiempo.
Por qué el control robótico tradicional se queda corto
Los controladores clásicos de robots son algo así como el control de crucero de un coche que asume que la carretera siempre está seca y lisa. Dependen de modelos matemáticos detallados de cada articulación, engranaje y fuerza. En la práctica, el comportamiento de un robot deriva cuando levanta distintos objetos, sus articulaciones se calientan o encuentra baches y empujones. Para robots con muchas articulaciones y un fuerte acoplamiento entre ellas, escribir un modelo perfecto es casi imposible. Como resultado, los controladores estándar de bucle único e incluso esquemas más avanzados de múltiples bucles a menudo desperdician energía, reaccionan despacio o pierden precisión ante cargas variables y perturbaciones.
Un “cerebro” de control que aprende para robots con muchas articulaciones
Para abordar esto, los autores proponen un marco de control totalmente libre de modelo diseñado para robots con varias articulaciones que se influyen entre sí. En lugar de depender de ecuaciones exactas, el controlador mezcla tres ideas: lógica difusa, que traduce de forma suave nociones vagas como “un poco fuera” o “se mueve demasiado rápido” en acciones de control; aprendizaje por refuerzo, que permite al robot mejorar sus decisiones con el tiempo mediante ensayo y error; y un método de búsqueda bio-inspirado llamado algoritmo de optimización de estrellas de mar, que ayuda a escoger buenos parámetros iniciales antes de que el robot se mueva. Además, se añade un término especial de “tiempo finito” para que los errores de seguimiento no solo disminuyan con el tiempo, sino que se reduzcan dentro de una ventana de tiempo corta y garantizada.
Cómo funciona el nuevo método de control
El controlador observa cuánto se desvía cada articulación de su ángulo deseado y con qué rapidez cambia ese error. Estas señales se pasan por reglas difusas —conjuntos de sentencias “si-entonces” superpuestas que pueden manejar la incertidumbre y la no linealidad— para generar una orden de par suave para los motores. El aprendizaje por refuerzo actúa en segundo plano y ajusta los parámetros de las reglas difusas en línea, premiando las acciones que reducen los errores rápidamente y penalizando las que causan sobreimpulso o vibraciones. El optimizador de estrellas de mar actúa antes, en una fase offline, buscando un buen conjunto inicial de parámetros difusos imitando cómo las estrellas de mar exploran y refinan su posición en el océano. Ese buen punto de partida acelera el aprendizaje una vez que el robot se enciende, mientras que el término de corrección en tiempo finito añade un empuje no lineal fuerte que lleva los errores cerca de cero en un tiempo acotado, incluso cuando cambian inesperadamente la masa del robot o del entorno.
Pruebas en brazos y piernas simulados
Para probar la idea, los investigadores usaron modelos por computador de dos robots. El primero es un sistema simple de dos articulaciones, a menudo usado para imitar una pierna que camina, donde una articulación se deja deliberadamente sin control motor directo para representar una situación subactuada, más difícil de controlar. El segundo es un brazo de cinco articulaciones similar a un miembro humanoide ligero. En ambos casos, los movimientos requeridos de las articulaciones eran trayectorias suaves, ondulantes, mientras que las masas de los eslabones del robot variaron aleatoriamente en el tiempo usando un proceso estadístico que imita cargas útiles realistas que cambian lentamente. También se añadieron perturbaciones extra, como empujones aleatorios y límites de par, para someter al controlador a estrés.
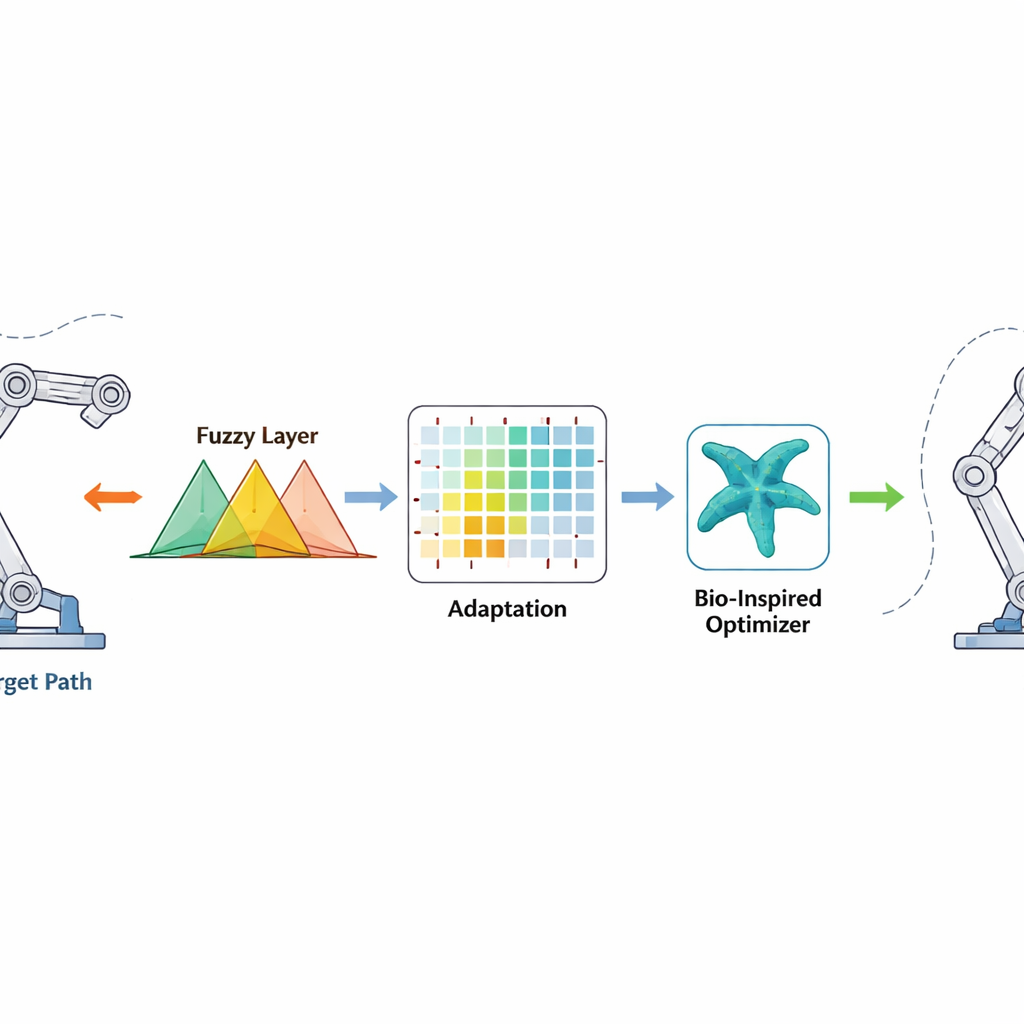
Qué muestran las simulaciones
En numerosas pruebas, el nuevo controlador mantuvo las articulaciones del robot siguiendo de cerca sus trayectorias deseadas, con errores angulares finales típicamente entre unas dos centésimas y cuatro centésimas de radian —solo unos pocos milímetros en la punta de un brazo. En comparación con el control proporcional–integral–derivativo (PID) estándar y métodos adaptativos más avanzados, el enfoque propuesto redujo el error de seguimiento global hasta en aproximadamente un 60 por ciento para el sistema de dos articulaciones y en torno al 30–35 por ciento para el brazo de cinco articulaciones. También alcanzó un movimiento suave más rápido, a menudo en menos de un segundo y medio, y utilizó aproximadamente un 15 por ciento menos esfuerzo de control, lo que implica menor consumo de energía y menor desgaste de los motores. Incluso en pruebas extremas —como doblar la masa efectiva mientras se limita el par disponible— el controlador mantuvo un movimiento estable y evitó oscilaciones descontroladas.
Qué significa esto para la robótica cotidiana
Para los no especialistas, el mensaje clave es que los robots no tienen que conocer cada detalle de su propia mecánica para moverse con fiabilidad en un mundo cambiante. Al combinar el razonamiento humanoide “difuso”, el aprendizaje por ensayo y error y un paso de preajuste ingenioso inspirado en las estrellas de mar, este esquema de control permite que robots con múltiples articulaciones se adapten al instante a cargas y perturbaciones cambiantes a la vez que garantiza que los errores disminuyan con rapidez. Si se confirma en hardware real, tales métodos podrían hacer que robots de servicio, dispositivos de asistencia y brazos industriales ágiles sean más seguros y eficientes, incluso cuando se les pida manejar nuevas tareas, nuevas herramientas y nuevos entornos sin reprogramaciones extensas.
Cita: Duan, C., Wang, L. & Li, S. Fuzzy adaptive nonlinear MIMO control for rigid coupled multibody robots using reinforcement learning model. Sci Rep 16, 11458 (2026). https://doi.org/10.1038/s41598-026-40982-w
Palabras clave: control de robots, aprendizaje por refuerzo, lógica difusa, robótica adaptativa, seguimiento de trayectoria