Clear Sky Science · he
בקרת MIMO לא-ליניארית אדפטיבית מטושטשת לרובוטים מרובי-גופים קשיחים עם למידת חיזוק
רובוטים שיכולים ללמוד בזמן העבודה
רובוטים יוצאים מקווי ייצור מגודרים ונעים אל בתי חולים, מחסנים ואפילו לבתינו. בסביבות מהסוג הבלתי מסודר הזה, העמסת המטענים משתנה, הרצפה אינה תמיד שטוחה, ואנשים עלולים להתנגש בהם. מאמר זה חוקר גישה חדשה להענקת יכולת לשמירה על תנועה חלקה, מדויקת ויציבה לרובוטים מרובי מפרקים—כמו זרועות ומכונות הליכה—גם כאשר העולם סביבם לא צפוי וגופם משתנה לאורך הזמן.
מדוע בקרת רובוט קלאסית אינה מספיקה
בקרי רובוט מסורתיים הם קצת כמו בקרת שיוט ברכב שמניחה שהכביש תמיד יבש וישר. הם נשענים על מודלים מתמטיים מפורטים של כל מפרק, גלגל שיניים וכוח. במציאות, התנהגות הרובוט נוטה להשתנות כשיאסוף חפצים שונים, מפרקיו יתחממו, או נתקל בבימות ודחיפות. עבור רובוטים עם מפרקים רבים וקישוריות חזקה ביניהם, כתיבת מודל מושלם כמעט בלתי אפשרית. כתוצאה מכך, בקרים חד-לולאתיים רגילים ואפילו סכמות מתקדמות מרובת לולאות לעתים מבזבזים אנרגיה, פועלים לאט או מאבדים דיוק מול עומסים ומשינויים חיצוניים.
"מוח" מבקר לומד לרובוטים מרובי מפרקים
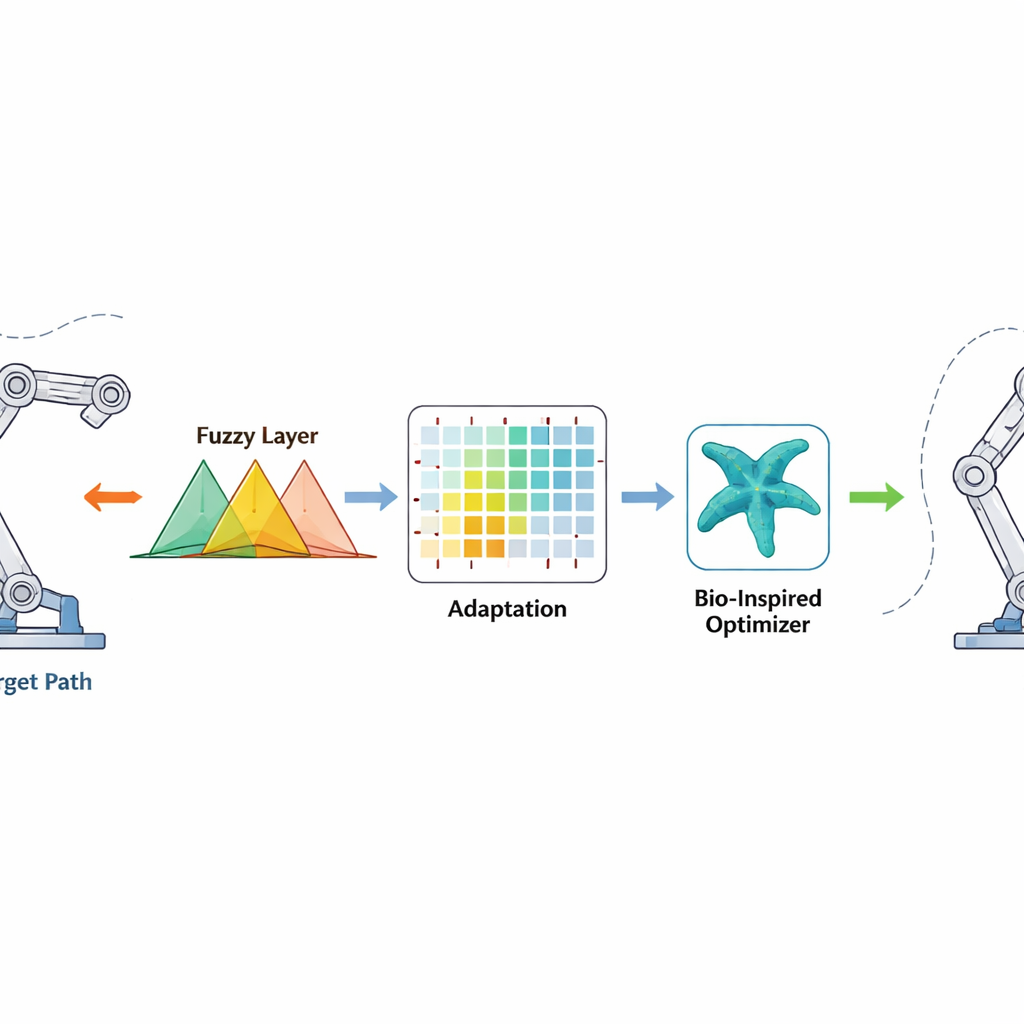
כדי להתמודד עם הבעיה, המחברים מציעים מסגרת בקרה חסרת-מודל לחלוטין שמיועדת לרובוטים עם מספר מפרקים המשפיעים זה על זה. במקום להסתמך על משוואות מדויקות, הבקר משלב שלוש רעיונות: לוגיקה מטושטשת, שמתורגמת בצורה חלקה מושגים מעורפלים כמו "קצת רחוק מדי" או "זז מהר מדי" לפעולות בקרה; למידת חיזוק, שמאפשרת לרובוט לשפר את החלטותיו באמצעות ניסוי וטעייה; ושיטת חיפוש ביוהשראתית בשם אלגוריתם האופטימיזציה של כוכבית הים, שעוזרת לבחור הגדרות התחלתיות טובות לפני שהרובוט מתחיל לזוז. בנוסף, נוסף ביטוי "זמן סופי" מיוחד כך ששגיאות המעקב לא רק יתכווצו בסופו של דבר, אלא יוכרחו לרדת בתוך חלון זמן קצר מובטח.
כיצד השיטה החדשה עובדת
הבקר בוחן כמה כל מפרק רחוק מהזווית הרצויה וכמה מהר משתנה שגיאה זו. אותות אלה מועברים דרך חוקים מטושטשים—קבוצות של הצהרות "אם-אז" החופפות שיכולות להתמודד עם חוסר וודאות ולא-ליניאריות—כדי לייצר פקודת מומנט חלקה למנועים. למידת החיזוק פועלת ברקע ומתאמת את פרמטרי חוקי המטושטשת בזמן אמת, מצדדת בפעולות שמקטינות שגיאות במהירות ומענישה אותן שגורמות לחריגה או ריצוד. המנסות החיפוש של כוכבית הים פועלת בשלבים מוקדמים, באופן לא מקוון, ומחפשת סט התחלתי טוב של פרמטרים מטושטשים על ידי חיקוי האופן שבו כוכבי ים חוקרים ומשפרים את מיקומם בים. נקודת התחלה טובה זו מאיצה את הלמידה כאשר הרובוט מופעל, בעוד שביטוי התיקון בזמן סופי מוסיף דחיפה לא-ליניארית חזקה שמניעה את השגיאות לכמעט אפס בפרק זמן גבולי, גם כאשר מסה או הסביבה של הרובוט משתנים באופן בלתי צפוי.
מבחנים על זרועות ורגליים מדומות
כדי לבחון את הרעיון, החוקרים השתמשו במודלים ממוחשבים של שני רובוטים. הראשון הוא מערכת פשוטה של שני מפרקים שלעיתים משמשת לחיקוי רגל מהלכת, כאשר מפרק אחד נשאר במכוון ללא בקרה ממונעת ישירה כדי לייצג מצב תחת-מופעל שקשה לשלוט בו. השני הוא זרוע בעלת חמישה מפרקים הדומה לגפה אנושית קלת משקל. בשני המקרים, תנועות המפרקים הנדרשות היו מסלולים חלקים בדומה לגל, בעוד שמסת הקישורים של הרובוט השתנתה אקראית לאורך הזמן באמצעות תהליך סטטיסטי המדמה מטענים מציאותיים המשתנים בהדרגה. נוספו גם הפרעות נוספות, כגון דחיפות אקראיות ומגבלות מומנט, כדי למתוח את הבקר.
מה מראים הסימולציות
במהלך ניסויים רבים, הבקר החדש שמר על עקיבת מפרקי הרובוט קרובה למסלולים הרצויים, עם שגיאות זווית סופיות שבדרך כלל נעו בסביבות שניים עד ארבעה מאיות רדיאן—רק כמה מילימטרים בקצה זרוע. בהשוואה לבקר PID סטנדרטי ושיטות אדפטיביות מתקדמות יותר, הגישה המוצעת קיצצה את השגיאה הכוללת במעקב בכ־60% עבור מערכת דו-מפרקית ובכ־30–35% עבור הזרוע חמישית המפרקים. היא גם התייצבה לתנועה חלקה מהר יותר, לעתים בפחות משנייה וחצי, והשתמשה בכ־15% פחות מאמץ בקרה, כלומר צריכת אנרגיה נמוכה יותר ופחות בלאי על המנועים. גם במבחנים קיצוניים—כגון כפל המסה היעילה תוך הגבלת מומנט זמין—הבקר שמר על תנועה יציבה והימנע מתנודות פרועות.
מה המשמעות לרובוטיקה יומיומית
ללא-מומחים, המסר המרכזי הוא שרובוטים אינם חייבים לדעת כל פרט במכניקה שלהם כדי לנוע באמינות בעולם שמשתנה. על ידי שילוב חשיבה "מטושטשת" בדומה לאדם, למידה על ידי ניסוי וטעייה ושלב כוונון חכם בהשראת כוכבי ים, סכימת הבקרה הזו מאפשרת לרובוטים מרובי מפרקים להסתגל בזמן אמת לעומסים והפרעות משתנים תוך שמירה על הבטחה כי השגיאות יורדות במהירות. אם יאוישו את השיטות בחומרה אמיתית, הן עשויות להפוך רובוטי שירות, מכשירי סיוע וזרועות תעשייתיות זריזות לבטוחים ויעילים יותר, גם כאשר יידרשו להתמודד עם משימות חדשות, כלים חדשים וסביבות שונות מבלי תכנות נרחב מחדש.
ציטוט: Duan, C., Wang, L. & Li, S. Fuzzy adaptive nonlinear MIMO control for rigid coupled multibody robots using reinforcement learning model. Sci Rep 16, 11458 (2026). https://doi.org/10.1038/s41598-026-40982-w
מילות מפתח: בקרת רובוט, למידת חיזוק, לוגיקה מטושטשת, רובוטיקה אדפטיבית, מעקב מסלולים