Clear Sky Science · pt
Controle Fuzzy adaptativo não linear MIMO para robôs multissensoriais rígidos acoplados usando modelo de aprendizado por reforço
Robôs que Podem Aprender em Serviço
Robôs estão saindo das linhas de fábrica cercadas e entrando em hospitais, armazéns e até em nossas casas. Nesses ambientes desordenados, suas cargas mudam, os pisos nem sempre são perfeitamente planos e pessoas podem esbarrar neles. Este artigo explora uma nova forma de dotar robôs com várias articulações — como braços e máquinas que andam — da capacidade de manter seus movimentos suaves, precisos e estáveis mesmo quando o mundo ao redor é imprevisível e seus próprios corpos mudam ao longo do tempo.
Por que o Controle Robótico Tradicional Falha
Controladores clássicos de robôs são um pouco como piloto automático em um carro que assume que a estrada está sempre seca e plana. Eles dependem de modelos matemáticos detalhados de cada junta, engrenagem e força. Na prática, o comportamento de um robô deriva à medida que ele pega objetos diferentes, suas juntas aquecem ou encontra solavancos e empurrões. Para robôs com muitas juntas e forte acoplamento entre elas, escrever um modelo perfeito é quase impossível. Como resultado, controladores padrão de laço único e até esquemas multi-laço mais avançados frequentemente desperdiçam energia, reagem lentamente ou perdem precisão diante de cargas e perturbações variáveis.
Um “Cérebro” de Controle que Aprende para Robôs de Muitas Juntas
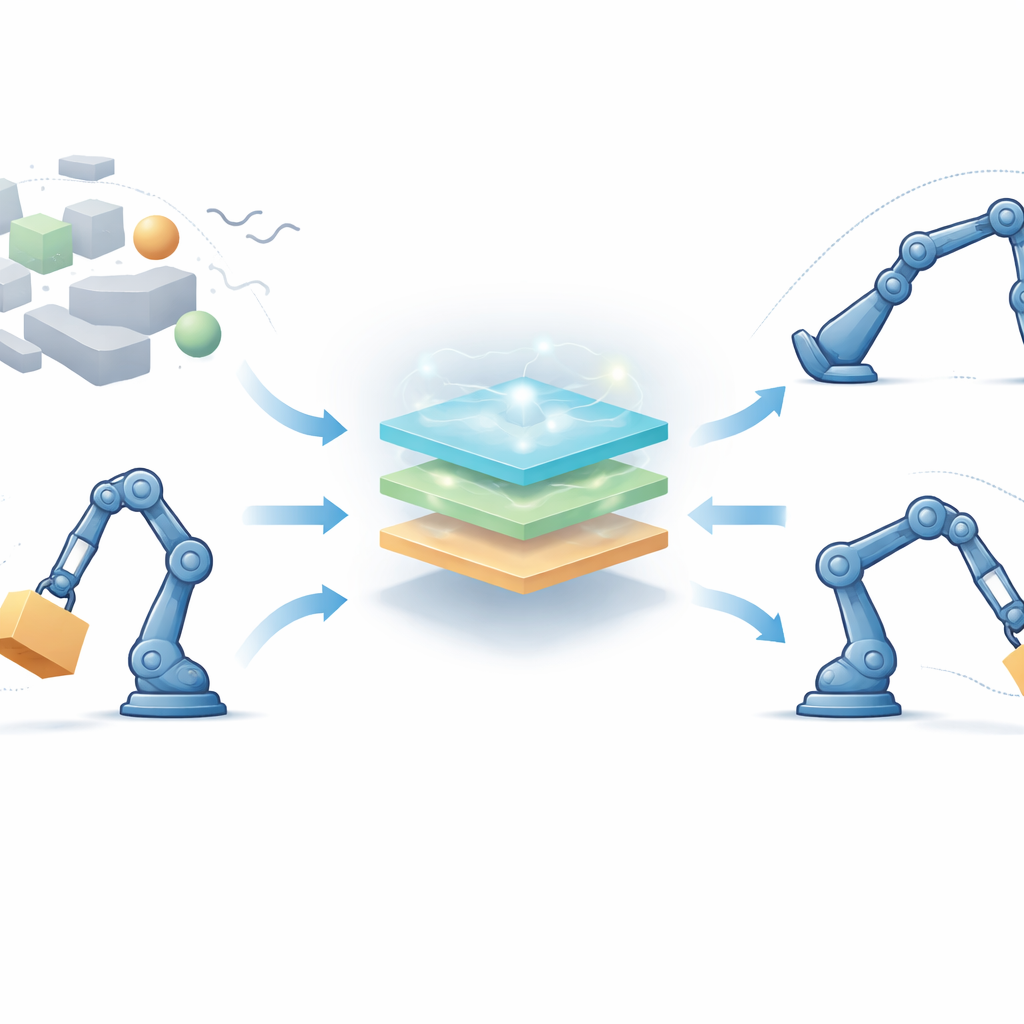
Para enfrentar isso, os autores propõem uma estrutura de controle totalmente livre de modelo projetada para robôs com várias juntas que influenciam umas às outras. Em vez de depender de equações exatas, o controlador combina três ideias: lógica fuzzy, que traduz suavemente noções vagas como “um pouco fora” ou “movendo-se rápido demais” em ações de controle; aprendizado por reforço, que permite ao robô melhorar suas decisões ao longo do tempo por tentativa e erro; e um método de busca bioinspirado chamado algoritmo de otimização de estrela-do-mar, que ajuda a escolher boas configurações iniciais antes de o robô se mover. Além disso, um termo especial de “tempo finito” é adicionado para que os erros de rastreamento não apenas diminuam eventualmente, mas sejam forçados a cair dentro de uma janela de tempo curta e garantida.
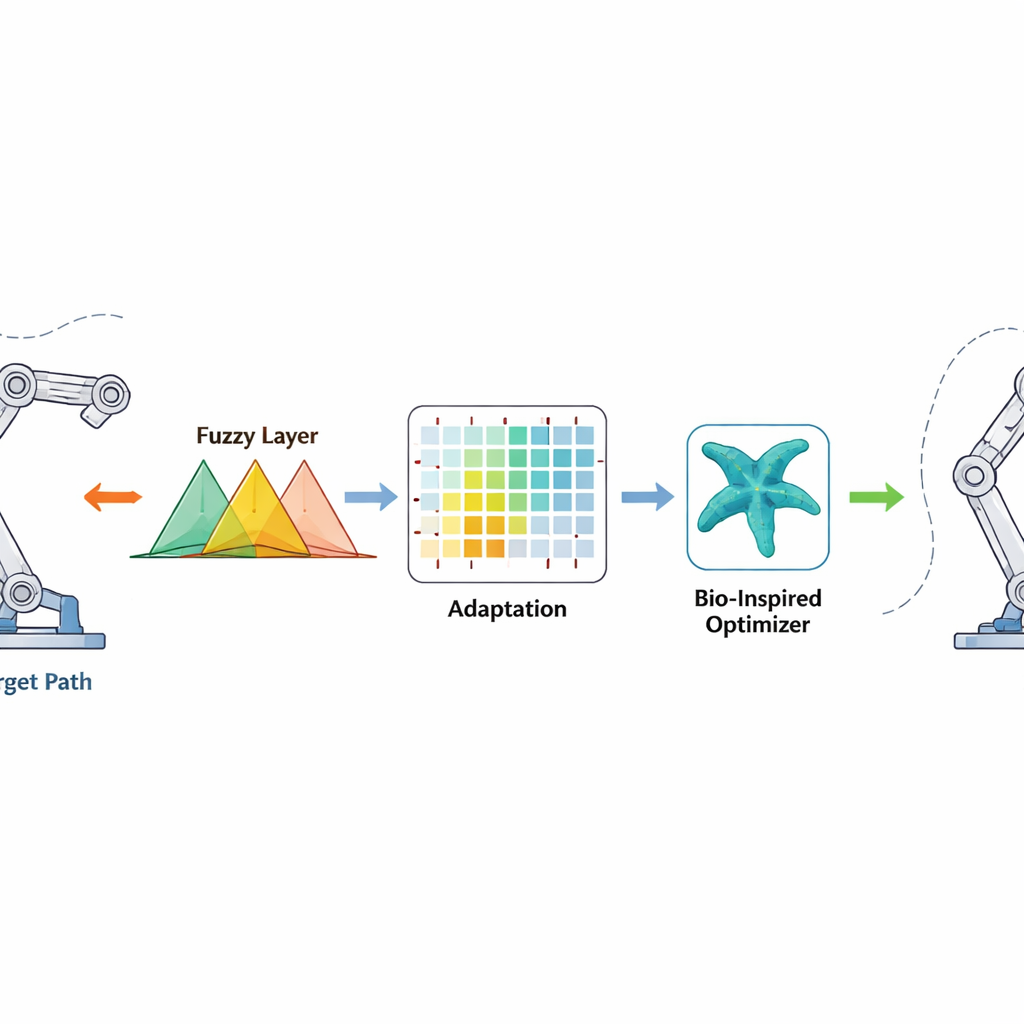
Como o Novo Método de Controle Funciona
O controlador observa quão distante cada junta está do ângulo desejado e com que velocidade esse erro está mudando. Esses sinais passam por regras fuzzy — conjuntos de declarações “se-então” sobrepostas que podem lidar com incerteza e não linearidade — para produzir um comando de torque suave para os motores. O aprendizado por reforço atua nos bastidores e ajusta os parâmetros das regras fuzzy online, recompensando ações que reduzem os erros rapidamente e penalizando as que causam ultrapassagem ou tremulação. O otimizador estrela-do-mar atua antes, em uma fase offline, buscando um bom conjunto inicial de parâmetros fuzzy ao imitar como estrelas-do-mar exploram e refinam sua posição no oceano. Esse bom ponto de partida acelera o aprendizado quando o robô é ligado, enquanto o termo de correção em tempo finito adiciona um impulso forte e não linear que leva os erros quase a zero em um tempo limitado, mesmo quando a massa do robô ou o ambiente mudam inesperadamente.
Testes em Braços e Pernas Simulados
Para testar a ideia, os pesquisadores usaram modelos computacionais de dois robôs. O primeiro é um sistema simples de duas juntas frequentemente usado para mimetizar uma perna de locomoção, onde uma junta é deliberadamente deixada sem controle motor direto para representar uma situação subatuada e mais difícil de controlar. O segundo é um braço de cinco juntas semelhante a um membro humanoide leve. Em ambos os casos, os movimentos exigidos nas juntas eram trajetórias suaves, em forma de onda, enquanto as massas dos elos do robô foram variadas aleatoriamente ao longo do tempo usando um processo estatístico que imita cargas úteis realistas e lentamente variáveis. Perturbações extras, como empurrões aleatórios e limites de torque, também foram adicionadas para estressar o controlador.
O que as Simulações Mostram
Em muitos ensaios, o novo controlador manteve as juntas do robô acompanhando de perto os trajetos desejados, com erros angulares finais tipicamente entre cerca de dois centésimos a quatro centésimos de radiano — apenas alguns milímetros na ponta de um braço. Em comparação com controle proporcional–integral–derivativo (PID) padrão e métodos adaptativos mais avançados, a abordagem proposta reduziu o erro global de rastreamento em até cerca de 60% para o sistema de duas juntas e em torno de 30–35% para o braço de cinco juntas. Também estabilizou em movimento suave mais rapidamente, frequentemente em menos de um segundo e meio, e usou aproximadamente 15% menos esforço de controle, significando menor consumo de energia e desgaste reduzido dos motores. Mesmo em testes extremos — como dobrar a massa efetiva enquanto limita o torque disponível — o controlador manteve o movimento estável e evitou oscilações violentas.
O que Isso Significa para a Robótica do Dia a Dia
Para não especialistas, a mensagem principal é que robôs não precisam conhecer cada detalhe de sua própria mecânica para se mover de forma confiável em um mundo em mudança. Ao combinar raciocínio “fuzzy” semelhante ao humano, aprendizado por tentativa e erro e uma etapa inteligente de pré-ajuste inspirada em estrelas-do-mar, esse esquema de controle permite que robôs multijuntas se adaptem em tempo real a cargas e perturbações variáveis, garantindo ainda que os erros diminuam rapidamente. Se confirmado em hardware real, tais métodos poderiam tornar robôs de serviço, dispositivos assistivos e braços industriais ágeis mais seguros e eficientes, mesmo quando solicitados a lidar com novas tarefas, novas ferramentas e novos ambientes sem extensa reprogramação.
Citação: Duan, C., Wang, L. & Li, S. Fuzzy adaptive nonlinear MIMO control for rigid coupled multibody robots using reinforcement learning model. Sci Rep 16, 11458 (2026). https://doi.org/10.1038/s41598-026-40982-w
Palavras-chave: controle de robô, aprendizado por reforço, lógica fuzzy, robótica adaptativa, rastreamento de trajetória