Clear Sky Science · en
Fuzzy adaptive nonlinear MIMO control for rigid coupled multibody robots using reinforcement learning model
Robots That Can Learn on the Job
Robots are moving out of fenced factory lines and into hospitals, warehouses, and even our homes. In these messy settings, their loads change, floors aren’t perfectly flat, and people can bump into them. This paper explores a new way to give multi-jointed robots—like arms and walking machines—the ability to keep their movements smooth, precise, and stable even when the world around them is unpredictable and their own bodies change over time.
Why Traditional Robot Control Falls Short
Classic robot controllers are a bit like cruise control in a car that assumes the road is always dry and flat. They rely on detailed mathematical models of every joint, gear, and force. In reality, a robot’s behavior drifts as it picks up different objects, its joints warm up, or it encounters bumps and pushes. For robots with many joints and strong coupling between them, writing a perfect model is nearly impossible. As a result, standard single-loop controllers and even more advanced multi-loop schemes often waste energy, react slowly, or lose accuracy when faced with changing loads and disturbances.
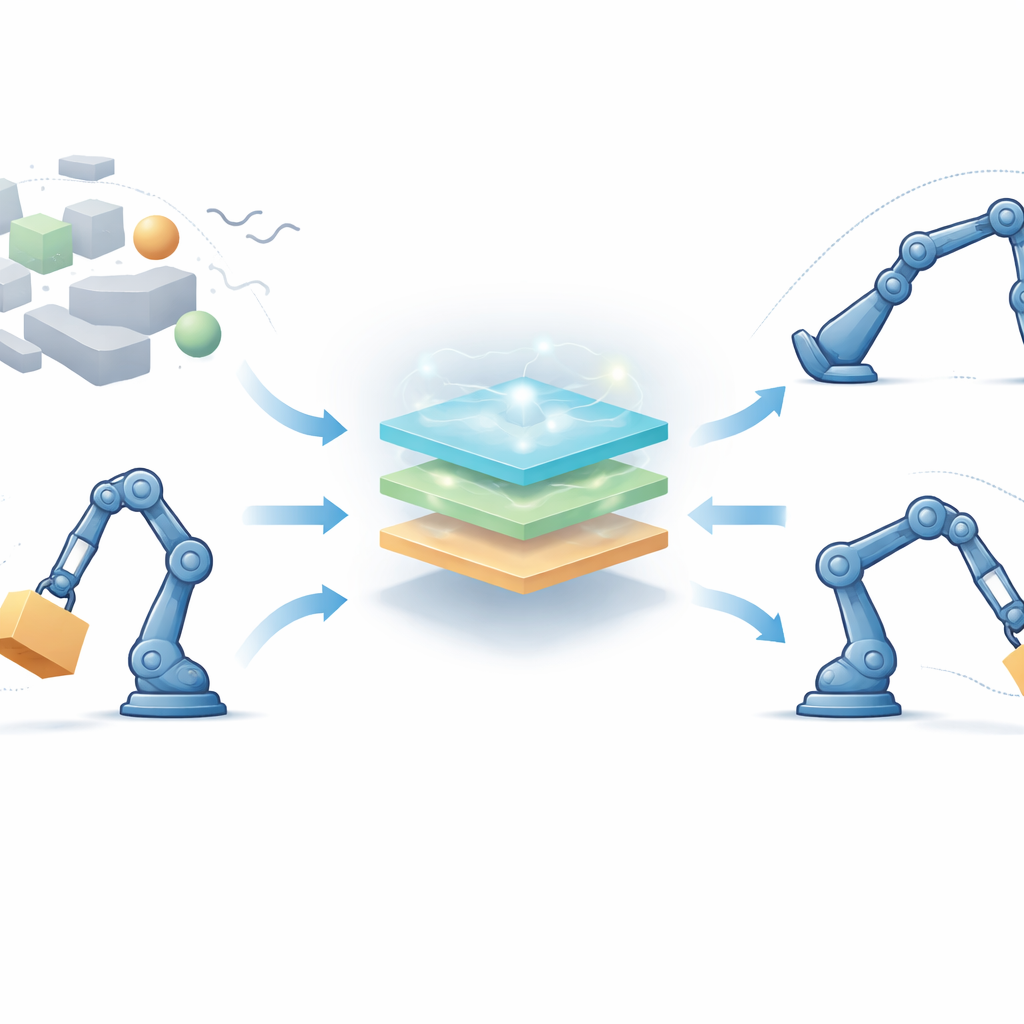
A Learning Control “Brain” for Many-Jointed Robots
To tackle this, the authors propose a fully model-free control framework designed for robots with several joints that influence each other. Instead of depending on exact equations, the controller blends three ideas: fuzzy logic, which smoothly translates vague notions like “a bit too far” or “moving too fast” into control actions; reinforcement learning, which lets the robot improve its decisions over time by trial and error; and a bio-inspired search method called the starfish optimization algorithm, which helps choose good starting settings before the robot ever moves. On top of that, a special “finite-time” term is added so that tracking errors do not just shrink eventually, but are forced down within a guaranteed short time window.
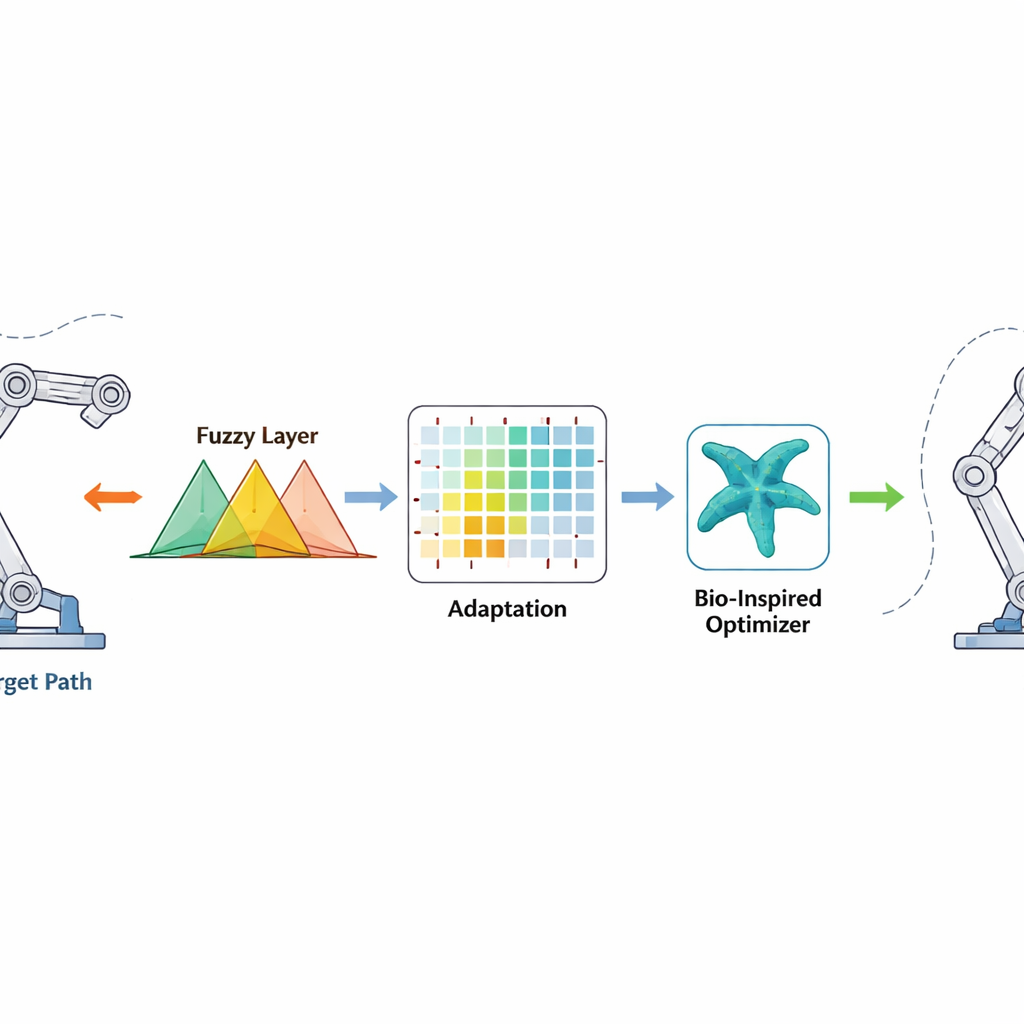
How the New Control Method Works
The controller looks at how far each joint is from its desired angle and how fast that error is changing. These signals are passed through fuzzy rules—sets of overlapping “if-then” statements that can handle uncertainty and nonlinearity—to produce a smooth torque command for the motors. Reinforcement learning sits behind the scenes and adjusts the fuzzy rule parameters online, rewarding actions that reduce errors quickly and penalizing those that cause overshoot or jitter. The starfish optimizer acts earlier, in an offline phase, searching for a good initial set of fuzzy parameters by mimicking how starfish explore and refine their position in the ocean. This good starting point speeds up learning once the robot is turned on, while the finite-time correction term adds a strong, nonlinear push that drives errors to near zero in a bounded time, even when the robot’s mass or environment changes unexpectedly.
Testing on Simulated Arms and Legs
To test the idea, the researchers used computer models of two robots. The first is a simple two-joint system often used to mimic a walking leg, where one joint is deliberately left without direct motor control to represent an underactuated, harder-to-control situation. The second is a five-joint arm similar to a lightweight humanoid limb. In both cases, the required joint motions were smooth, wave-like paths, while the robot’s link masses were randomly varied over time using a statistical process that imitates realistic, slowly changing payloads. Extra disturbances, such as random pushes and torque limits, were also added to stress the controller.
What the Simulations Show
Across many trials, the new controller kept the robot joints closely tracking their desired paths, with final angle errors typically within about two hundredths to four hundredths of a radian—only a few millimeters at the end of an arm. Compared to standard proportional–integral–derivative (PID) control and more advanced adaptive methods, the proposed approach cut overall tracking error by up to about 60 percent for the two-joint system and around 30–35 percent for the five-joint arm. It also settled into smooth motion faster, often in under one and a half seconds, and used roughly 15 percent less control effort, meaning lower energy use and reduced wear on motors. Even under extreme tests—such as doubling the effective mass while limiting the available torque—the controller maintained stable motion and avoided wild swings.
What This Means for Everyday Robotics
For non-specialists, the key message is that robots do not have to know every detail of their own mechanics to move reliably in a changing world. By combining human-like “fuzzy” reasoning, trial-and-error learning, and a clever pre-tuning step inspired by starfish, this control scheme lets multi-jointed robots adapt on the fly to shifting loads and disturbances while still guaranteeing that errors shrink quickly. If confirmed on real hardware, such methods could make service robots, assistive devices, and agile industrial arms both safer and more efficient, even when they are asked to handle new tasks, new tools, and new environments without extensive reprogramming.
Citation: Duan, C., Wang, L. & Li, S. Fuzzy adaptive nonlinear MIMO control for rigid coupled multibody robots using reinforcement learning model. Sci Rep 16, 11458 (2026). https://doi.org/10.1038/s41598-026-40982-w
Keywords: robot control, reinforcement learning, fuzzy logic, adaptive robotics, trajectory tracking