Clear Sky Science · ja
強連結多体ロボットのための強化学習モデルを用いたファジー適応非線形多入力多出力制御
現場で学習するロボット
ロボットは工場の柵で囲まれたラインを離れ、病院や倉庫、さらには私たちの家庭へと進出しています。こうした雑然とした環境では、荷重が変わり、床が完全に平坦でないこともあり、人がぶつかることもあります。本論文は、関節を多数持つロボット(腕や歩行機構など)に対し、周囲が予測不能で自身の状態が変化しても動作を滑らかで精密かつ安定に保つ能力を与える新しい手法を探ります。
従来のロボット制御が限界を迎える理由
従来のロボット制御は、常に舗装された乾いた道路を前提としたクルーズコントロールのようなものです。各関節やギア、力の詳細な数学モデルに依存します。しかし実際には、ロボットが異なる物体を持ち上げると挙動が変わったり、関節が温まり特性が変わったり、衝撃や外乱に遭遇することで挙動がずれていきます。多関節で強く相互に結合しているロボットでは、完全なモデルを作ることはほぼ不可能です。その結果、標準的な単一ループ制御やより高度な多ループ方式でさえ、荷重変化や外乱に直面するとエネルギーを無駄にしたり、反応が遅くなったり、精度を失ったりします。
多関節ロボットのための学習型制御“ブレイン”
これに対処するため、本研究では関節間相互作用があるロボット向けの完全モデルフリー制御フレームワークを提案します。正確な方程式に依存する代わりに、制御器は三つの考え方を融合します。まずファジィ論理は「少し届いていない」や「速すぎる」といった曖昧な感覚を滑らかに制御動作へ変換します。次に強化学習は試行錯誤で意思決定を改善します。そして、海星の探索行動に着想を得た星状最適化アルゴリズム(スターフィッシュ最適化)が、ロボットが動き始める前に良好な初期設定を選ぶのを助けます。さらに、誤差が単にいずれ収束するだけでなく、保証された短時間内に低下するようにする特別な「有限時間」項が加えられます。
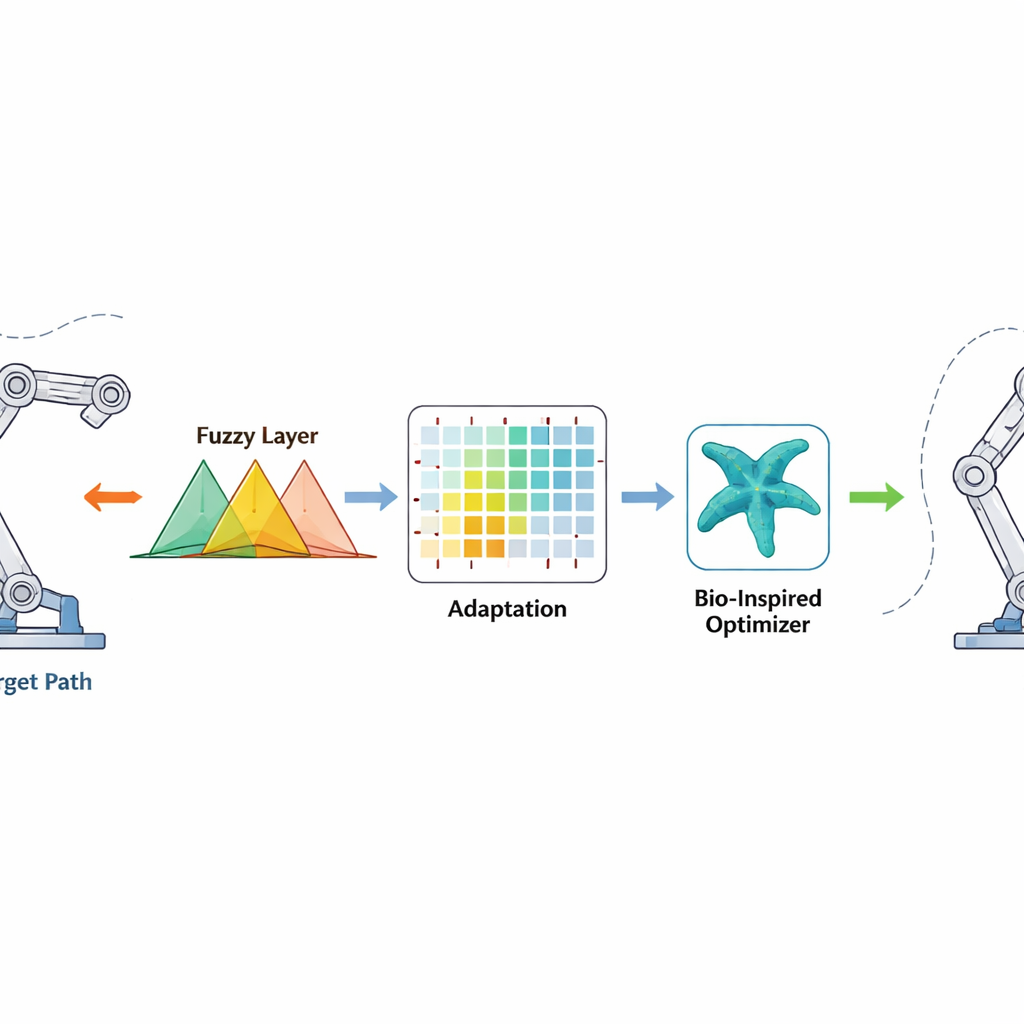
新しい制御法の仕組み
制御器は各関節が目標角度からどれだけずれているかと、その誤差がどれだけ速く変化しているかを観測します。これらの信号はファジィルール―重なり合う「もし〜ならば」の集合で、不確実性や非線形性を扱いながら滑らかなトルク指令を生成します。強化学習は背景でファジィルールのパラメータをオンラインで調整し、誤差を速く減らす行動を報酬し、オーバーシュートや振動を引き起こす行動を罰します。スターフィッシュ最適化はオフライン段階で先に働き、海星が海中で位置を探索・洗練する様子を模して初期の良いファジィパラメータを探索します。この良い出発点によりロボット起動後の学習が速まり、有限時間補正項は質量や環境が予期せず変化しても誤差を有界な時間内にほぼゼロへ押し下げる強い非線形的な駆動を付加します。
腕・脚のシミュレーションでの検証
検証のため、研究者たちは二種類のロボットをコンピュータモデルで評価しました。第一は歩行脚を模すことが多い単純な二関節系で、一つの関節が意図的に直接駆動されない未駆動(アンダーアクチュエーテッド)設定になっています。第二は軽量ヒューマノイドの四肢に似た五関節の腕です。いずれの場合も要求される関節運動は滑らかな波状経路で、ロボットのリンク質量は現実的でゆっくり変化するペイロードを模した統計過程によりランダムに変動させました。さらにランダムな押しやトルク制限といった外乱も追加して制御器に負荷をかけました。
シミュレーションの結果
多数の試行において、新しい制御器は関節を目標軌道に密接に追従させ、最終的な角度誤差は通常約0.02〜0.04ラジアン(腕の先端で数ミリメートル程度)に収まりました。従来の比例・積分・微分(PID)制御やより高度な適応手法と比較して、提案手法は二関節系で全体の追従誤差を最大約60%削減し、五関節腕でも約30〜35%削減しました。また動作の定常化が速く、しばしば1.5秒未満で滑らかな運動に落ち着き、制御努力も約15%少なくて済みました。これはエネルギー消費の低減とモータ摩耗の抑制を意味します。質量を倍加させて利用可能トルクを制限するような極端な試験下でも、制御器は安定した動作を維持し、暴れ動作を回避しました。
日常ロボティクスへの示唆
専門外の方への要点は、ロボットが変化する世界で確実に動くために自分自身の機構のすべての詳細を知る必要はない、ということです。人間らしい「ファジィ」な推論、試行錯誤による学習、そして海星に着想を得た巧妙な事前調整ステップを組み合わせることで、この制御方式は多関節ロボットが荷重変動や外乱に現場で適応しつつ、誤差が迅速に縮小することを保証します。実機で確認されれば、サービスロボット、支援機器、機敏な産業用アームなどが、新たな作業や道具、環境に対して大規模な再プログラミングなしにより安全で効率的に動作できるようになる可能性があります。
引用: Duan, C., Wang, L. & Li, S. Fuzzy adaptive nonlinear MIMO control for rigid coupled multibody robots using reinforcement learning model. Sci Rep 16, 11458 (2026). https://doi.org/10.1038/s41598-026-40982-w
キーワード: ロボット制御, 強化学習, ファジィ論理, 適応ロボティクス, 軌道追従