Clear Sky Science · it
Controllo MIMO non lineare adattivo fuzzy per robot multibody rigidi accoppiati usando un modello di apprendimento per rinforzo
Robot che imparano sul campo
I robot stanno uscendo dalle linee di produzione recintate e entrando in ospedali, magazzini e persino nelle nostre case. In questi ambienti disordinati i carichi cambiano, i pavimenti non sono perfettamente piani e le persone possono urtarli. Questo articolo esplora un nuovo modo per dotare robot con più giunti — come braccia e macchine ambulanti — della capacità di mantenere movimenti fluidi, precisi e stabili anche quando il mondo intorno a loro è imprevedibile e il loro corpo cambia nel tempo.
Perché il controllo tradizionale dei robot non basta
I controller classici per robot sono un po’ come il controllo di velocità di un’auto che presume che la strada sia sempre asciutta e in piano. Si basano su modelli matematici dettagliati di ogni giunto, ingranaggio e forza. Nella realtà il comportamento di un robot deriva quando raccoglie oggetti diversi, i giunti si scaldano o incontra urti e spinte. Per robot con molti giunti e forte accoppiamento tra di essi, scrivere un modello perfetto è quasi impossibile. Di conseguenza, i controller standard a singolo anello e persino schemi multilivello più avanzati spesso sprecano energia, reagiscono lentamente o perdono accuratezza di fronte a carichi variabili e disturbi.
Un “cervello” di controllo che impara per robot multiarticolari
Per affrontare il problema, gli autori propongono un framework di controllo completamente privo di modello progettato per robot con diversi giunti che si influenzano a vicenda. Invece di dipendere da equazioni esatte, il controller fonde tre idee: la logica fuzzy, che traduce in modo graduale nozioni vaghe come “un po’ troppo lontano” o “si muove troppo velocemente” in azioni di controllo; l’apprendimento per rinforzo, che permette al robot di migliorare le decisioni nel tempo per tentativi ed errori; e un metodo di ricerca ispirato alla biologia chiamato algoritmo di ottimizzazione a stella marina, che aiuta a scegliere buone impostazioni iniziali prima che il robot si muova. Inoltre, è aggiunto un termine speciale a tempo finito in modo che gli errori di inseguimento non si riducano solo eventualmente, ma siano forzati a diminuire entro una finestra temporale breve e garantita.
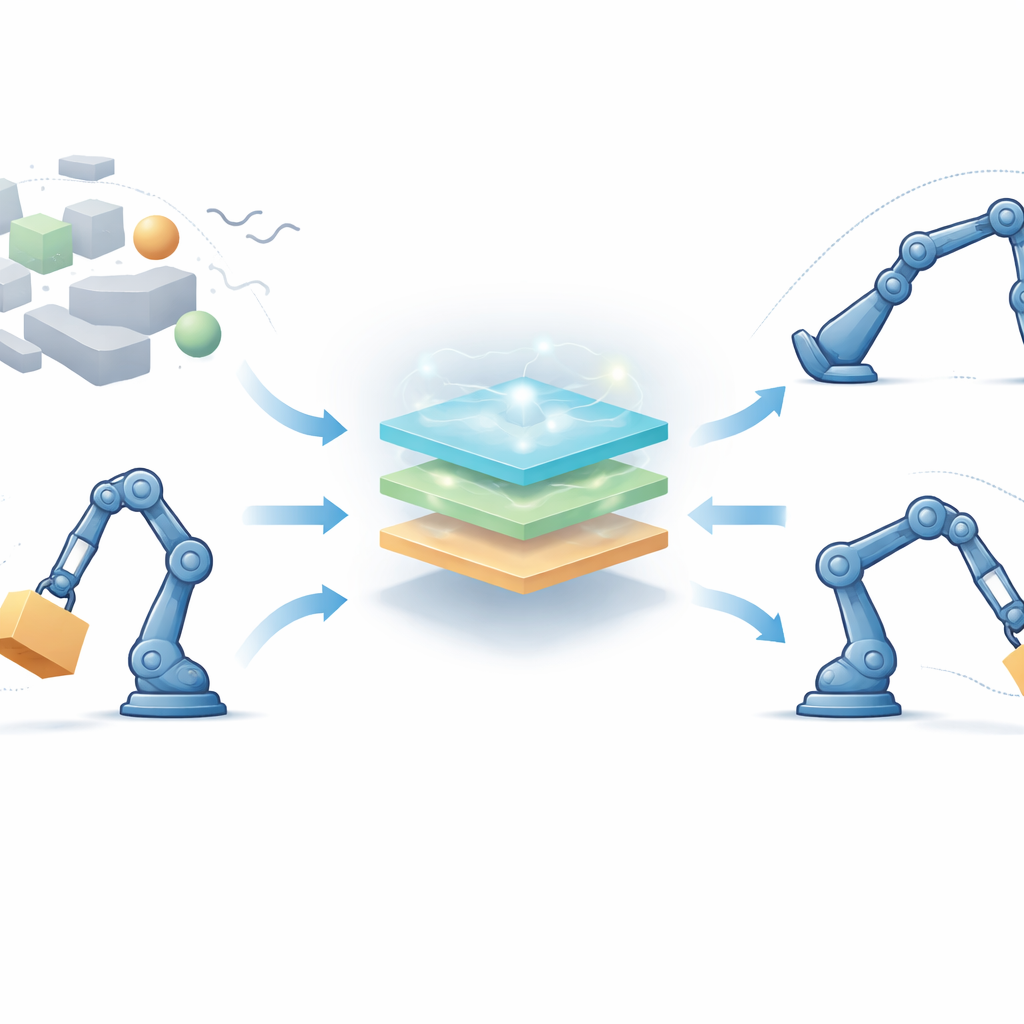
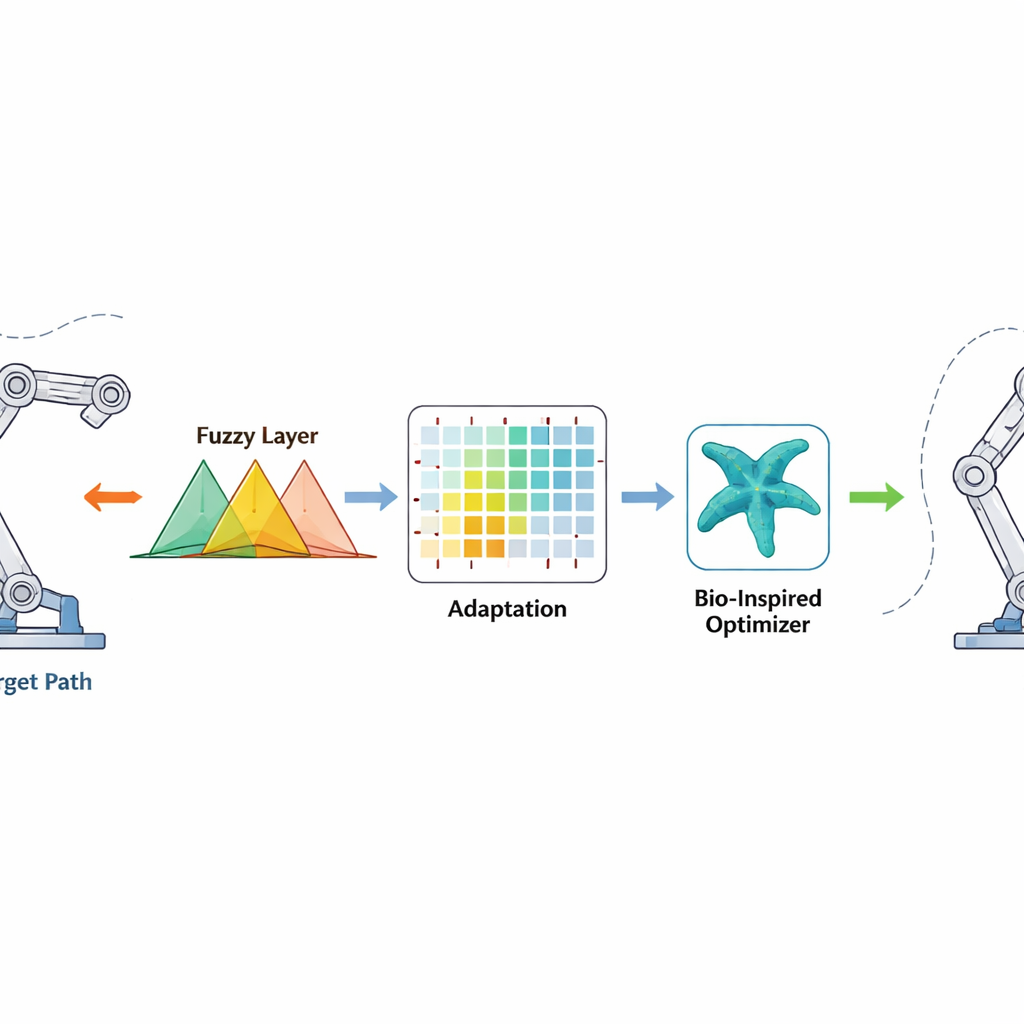
Come funziona il nuovo metodo di controllo
Il controller osserva quanto ogni giunto è distante dall’angolo desiderato e quanto rapidamente quell’errore sta cambiando. Questi segnali vengono passati attraverso regole fuzzy — insiemi di dichiarazioni “se-allora” sovrapposte in grado di gestire incertezza e non linearità — per produrre un comando di coppia fluido per i motori. L’apprendimento per rinforzo opera in background e aggiusta online i parametri delle regole fuzzy, premiando azioni che riducono gli errori rapidamente e penalizzando quelle che causano sovraelongazione o instabilità. L’ottimizzatore a stella marina agisce in una fase offline, cercando un buon insieme iniziale di parametri fuzzy imitando il modo in cui le stelle marine esplorano e rafforzano la loro posizione nell’oceano. Questo buon punto di partenza accelera l’apprendimento una volta che il robot è acceso, mentre il termine di correzione a tempo finito aggiunge una spinta non lineare forte che porta gli errori vicino allo zero in un tempo limitato, anche quando la massa del robot o l’ambiente cambiano inaspettatamente.
Test su braccia e gambe simulate
Per testare l’idea, i ricercatori hanno usato modelli al computer di due robot. Il primo è un semplice sistema a due giunti spesso impiegato per imitare una gamba in cammino, dove un giunto è deliberatamente lasciato senza controllo motore diretto per rappresentare una situazione sottoattuata e più difficile da controllare. Il secondo è un braccio a cinque giunti simile a un arto umanoide leggero. In entrambi i casi i movimenti richiesti ai giunti erano traiettorie morbide a onde, mentre le masse dei link del robot venivano variate casualmente nel tempo usando un processo statistico che imita carichi utili realistici e lentamente variabili. Sono anche stati aggiunti disturbi extra, come spinte casuali e limiti di coppia, per stressare il controller.
Cosa mostrano le simulazioni
In molte prove, il nuovo controller ha mantenuto i giunti del robot vicini alle traiettorie desiderate, con errori angolari finali tipicamente nell’ordine di circa duecentesimi fino a quattrocentesimi di radiante — solo pochi millimetri all’estremità di un braccio. Rispetto al controllo proporzionale–integrale–derivativo (PID) standard e a metodi adattivi più avanzati, l’approccio proposto ha ridotto l’errore complessivo di inseguimento fino a circa il 60% per il sistema a due giunti e intorno al 30–35% per il braccio a cinque giunti. Si è anche stabilizzato in un moto fluido più rapidamente, spesso in meno di un secondo e mezzo, e ha usato circa il 15% in meno di sforzo di controllo, il che significa minore consumo energetico e minore usura dei motori. Anche in test estremi — come raddoppiare la massa effettiva limitando la coppia disponibile — il controller ha mantenuto un movimento stabile ed evitato oscillazioni selvagge.
Cosa significa questo per la robotica di tutti i giorni
Per i non specialisti, il messaggio chiave è che i robot non devono conoscere ogni dettaglio della propria meccanica per muoversi in modo affidabile in un mondo che cambia. Combinando il ragionamento “fuzzy” simile a quello umano, l’apprendimento per tentativi e un intelligente passaggio di pre-taratura ispirato alle stelle marine, questo schema di controllo permette ai robot multiarticolari di adattarsi al volo a carichi e disturbi variabili garantendo comunque che gli errori si riducano rapidamente. Se confermato su hardware reale, tali metodi potrebbero rendere i robot di servizio, i dispositivi di assistenza e le braccia industriali agili sia più sicuri sia più efficienti, anche quando sono chiamati a gestire nuovi compiti, nuovi strumenti e nuovi ambienti senza ampie riprogrammazioni.
Citazione: Duan, C., Wang, L. & Li, S. Fuzzy adaptive nonlinear MIMO control for rigid coupled multibody robots using reinforcement learning model. Sci Rep 16, 11458 (2026). https://doi.org/10.1038/s41598-026-40982-w
Parole chiave: controllo robot, apprendimento per rinforzo, logica fuzzy, robotica adattiva, inseguimento di traiettoria