Clear Sky Science · fr
Contrôle MIMO non linéaire adaptatif flou pour robots multibody rigides couplés utilisant un modèle d’apprentissage par renforcement
Des robots qui apprennent sur le tas
Les robots sortent des lignes d’usine clôturées pour entrer dans les hôpitaux, les entrepôts et même nos foyers. Dans ces environnements désordonnés, leurs charges varient, les sols ne sont pas parfaitement plats et des personnes peuvent les heurter. Cet article explore une nouvelle façon de doter des robots à multiples articulations — comme des bras et des machines marchantes — de la capacité à maintenir des mouvements fluides, précis et stables même lorsque le monde qui les entoure est imprévisible et que leur propre structure évolue dans le temps.
Pourquoi les commandes classiques montrent leurs limites
Les régulateurs classiques pour robots ressemblent un peu au régulateur de vitesse d’une voiture qui supposerait que la route est toujours sèche et plane. Ils s’appuient sur des modèles mathématiques détaillés de chaque articulation, engrenage et force. En réalité, le comportement d’un robot dérive lorsqu’il saisit des objets différents, que ses articulations chauffent ou qu’il rencontre des bosses et des chocs. Pour les robots à nombreuses articulations et fortement couplées, écrire un modèle parfait est presque impossible. En conséquence, les régulateurs à boucle unique standard et même des architectures multi-boucles plus sophistiquées gaspillent souvent de l’énergie, réagissent lentement ou perdent en précision face à des charges changeantes et des perturbations.
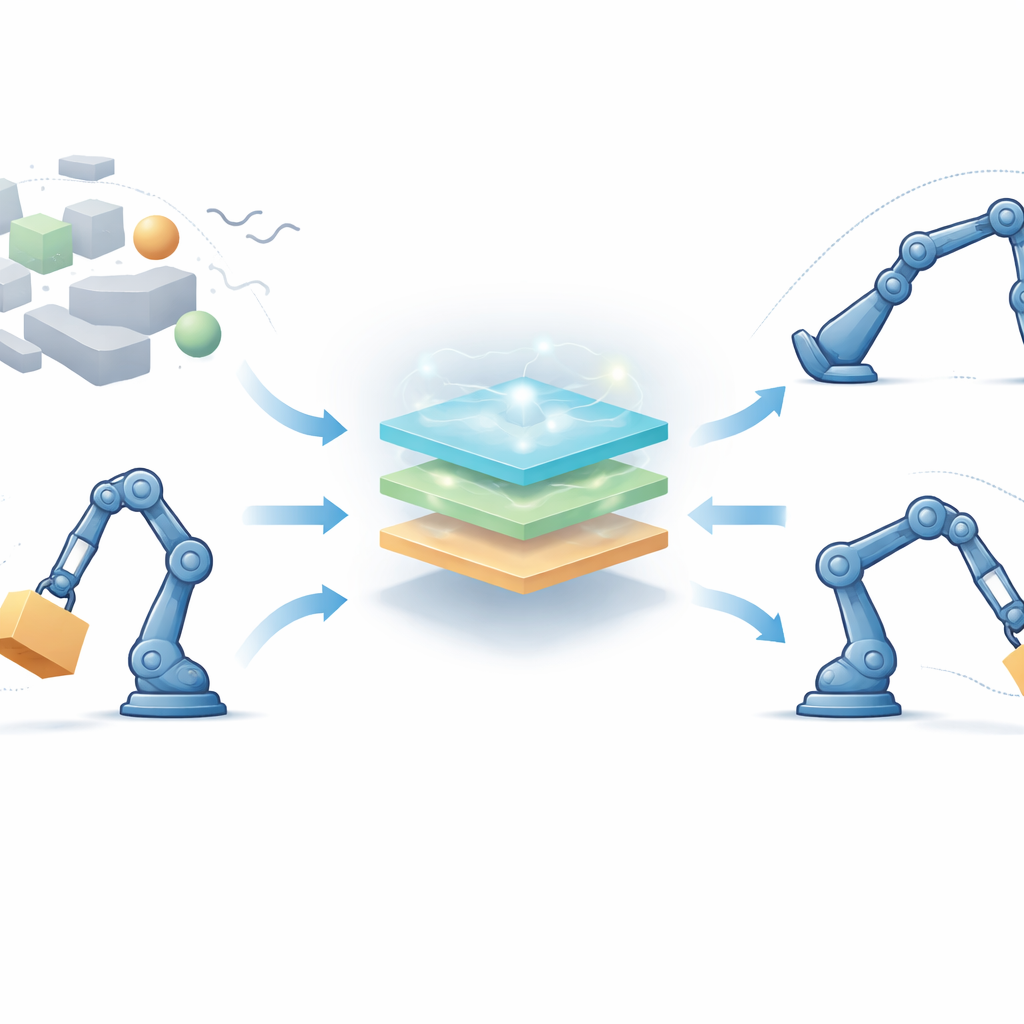
Un « cerveau » de commande apprenant pour robots multi-articulés
Pour répondre à ce défi, les auteurs proposent un cadre de commande entièrement sans modèle, conçu pour des robots dont plusieurs articulations s’influencent mutuellement. Plutôt que de dépendre d’équations exactes, le contrôleur combine trois idées : la logique floue, qui traduit en douceur des notions vagues comme « un peu trop loin » ou « bouge trop vite » en actions de commande ; l’apprentissage par renforcement, qui permet au robot d’améliorer ses décisions au fil du temps par essai-erreur ; et une méthode de recherche bio-inspirée appelée algorithme d’optimisation étoile de mer, qui aide à choisir de bons réglages initiaux avant même que le robot ne bouge. De plus, un terme particulier de « temps fini » est ajouté afin que les erreurs de suivi ne se réduisent pas seulement éventuellement, mais soient forcées à diminuer dans une fenêtre temporelle garantie et courte.
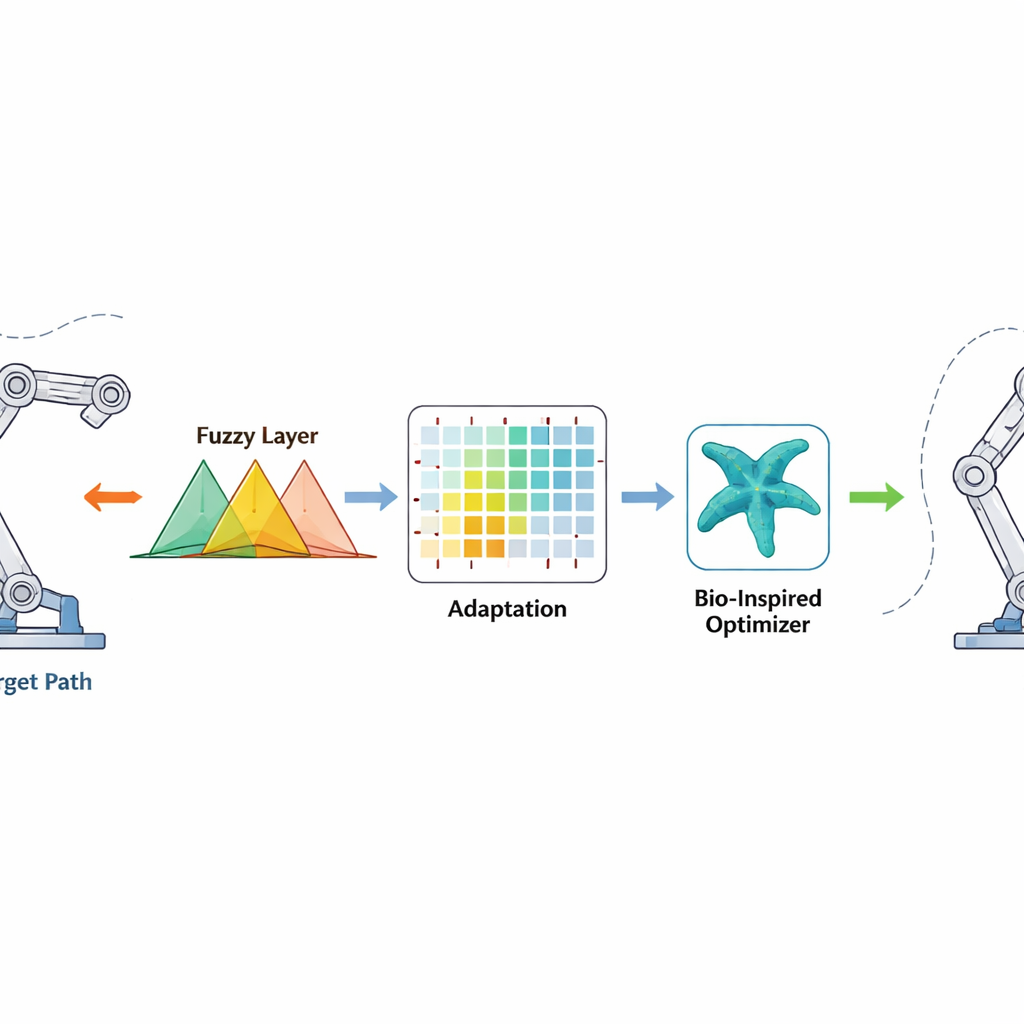
Comment fonctionne la nouvelle méthode de commande
Le contrôleur examine l’écart de chaque articulation par rapport à l’angle désiré et la vitesse de variation de cette erreur. Ces signaux sont passés à travers des règles floues — des ensembles de déclarations « si-alors » qui se chevauchent et peuvent gérer l’incertitude et la non-linéarité — pour produire une consigne de couple lisse pour les moteurs. L’apprentissage par renforcement agit en coulisse et ajuste en ligne les paramètres des règles floues, récompensant les actions qui réduisent rapidement les erreurs et pénalisant celles qui provoquent des dépassements ou des oscillations. L’optimiseur étoile de mer intervient en amont, dans une phase hors ligne, en recherchant un bon jeu initial de paramètres flous en imitant la manière dont les étoiles de mer explorent et affinent leur position dans l’océan. Ce bon point de départ accélère l’apprentissage une fois le robot mis en marche, tandis que le terme de correction en temps fini ajoute une poussée non linéaire forte qui ramène les erreurs proches de zéro dans un temps borné, même lorsque la masse du robot ou l’environnement changent de façon inattendue.
Tests sur bras et jambes simulés
Pour évaluer l’idée, les chercheurs ont utilisé des modèles informatiques de deux robots. Le premier est un système simple à deux articulations souvent utilisé pour imiter une jambe marchante, où une articulation est délibérément laissée sans commande directe pour représenter une situation sous-actionnée, plus difficile à contrôler. Le second est un bras à cinq articulations similaire à un membre humanoïde léger. Dans les deux cas, les mouvements requis étaient des trajectoires lisses et ondulantes, tandis que les masses des éléments du robot variaient aléatoirement dans le temps selon un processus statistique imitant des charges utiles réalistes changeant lentement. Des perturbations supplémentaires, telles que des poussées aléatoires et des limites de couple, ont également été ajoutées pour mettre le contrôleur à l’épreuve.
Ce que montrent les simulations
Sur de nombreux essais, le nouveau contrôleur a maintenu les articulations du robot en suivi rapproché de leurs trajectoires désirées, avec des erreurs angulaires finales typiquement de l’ordre de deux à quatre centièmes de radian — soit seulement quelques millimètres à l’extrémité d’un bras. Par rapport au contrôle proportionnel–intégral–dérivé (PID) standard et à des méthodes adaptatives plus avancées, l’approche proposée a réduit l’erreur globale de suivi jusqu’à environ 60 % pour le système à deux articulations et d’environ 30–35 % pour le bras à cinq articulations. Elle a aussi atteint un mouvement fluide plus rapidement, souvent en moins d’une seconde et demie, et a utilisé environ 15 % d’effort de commande en moins, ce qui signifie une consommation d’énergie moindre et moins d’usure des moteurs. Même lors de tests extrêmes — par exemple en doublant la masse effective tout en limitant le couple disponible — le contrôleur a maintenu un mouvement stable et évité des oscillations violentes.
Ce que cela signifie pour la robotique quotidienne
Pour les non-spécialistes, le message clé est que les robots n’ont pas besoin de connaître chaque détail de leur mécanique pour se déplacer de manière fiable dans un monde changeant. En combinant un raisonnement « flou » proche de l’humain, l’apprentissage par essai-erreur et une étape astucieuse de pré-réglage inspirée des étoiles de mer, ce schéma de commande permet aux robots multi-articulés de s’adapter en temps réel aux variations de charge et aux perturbations tout en garantissant une réduction rapide des erreurs. Si cela se confirme sur du matériel réel, de telles méthodes pourraient rendre les robots de service, les dispositifs d’assistance et les bras industriels agiles à la fois plus sûrs et plus efficaces, même lorsqu’on leur demande d’exécuter de nouvelles tâches, d’utiliser de nouveaux outils ou d’opérer dans de nouveaux environnements sans reprogrammation approfondie.
Citation: Duan, C., Wang, L. & Li, S. Fuzzy adaptive nonlinear MIMO control for rigid coupled multibody robots using reinforcement learning model. Sci Rep 16, 11458 (2026). https://doi.org/10.1038/s41598-026-40982-w
Mots-clés: commande robotique, apprentissage par renforcement, logique floue, robotique adaptative, suivi de trajectoire