Clear Sky Science · pl
Rozmyty adaptacyjny nieliniowy sterownik MIMO dla sztywnych sprzężonych robotów wielociałowych z wykorzystaniem modelu uczenia ze wzmocnieniem
Roboty, które uczą się w pracy
Roboty wychodzą z ogrodzonych linii produkcyjnych i trafiają do szpitali, magazynów, a nawet do naszych domów. W tych nieuporządkowanych środowiskach ich ładunki się zmieniają, podłogi nie zawsze są idealnie równe, a ludzie mogą się o nie obijać. W artykule opisano nowe podejście pozwalające wielostawowym robotom — takim jak ramiona czy maszyny kroczące — zachować płynność, precyzję i stabilność ruchu nawet wtedy, gdy otoczenie jest nieprzewidywalne, a sama struktura robota zmienia się w czasie.
Dlaczego tradycyjne sterowanie robotów zawodzi
Klasyczne regulatory robotyczne są trochę jak tempomat w samochodzie, który zakłada, że droga jest zawsze sucha i równa. Opierają się na szczegółowych modelach matematycznych każdego przegubu, przekładni i sił. W praktyce zachowanie robota dryfuje, gdy podnosi różne przedmioty, gdy przeguby się nagrzewają, albo gdy napotyka nierówności i pchnięcia. Dla robotów z wieloma przegubami i silnym sprzężeniem między nimi stworzenie doskonałego modelu jest praktycznie niemożliwe. W efekcie standardowe regulatory jednopętlowe, a nawet bardziej zaawansowane schematy wielopętlowe, często marnują energię, reagują powoli lub tracą dokładność wobec zmieniających się obciążeń i zakłóceń.
„Mózg” sterujący uczący się dla robotów wielostawowych
Aby temu zaradzić, autorzy proponują w pełni bezmodelowe ramy sterowania przeznaczone dla robotów z wieloma wzajemnie oddziałującymi przegubami. Zamiast polegać na dokładnych równaniach, regulator łączy trzy idee: logikę rozmytą, która gładko przekłada nieprecyzyjne pojęcia typu „trochę za daleko” czy „porusza się za szybko” na działania sterujące; uczenie ze wzmocnieniem, które pozwala robotowi poprawiać decyzje w czasie poprzez próbę i błąd; oraz inspirowaną biologicznie metodę wyszukiwania zwaną algorytmem optymalizacji rozgwiazdy, pomagającą dobrać dobre ustawienia początkowe przed uruchomieniem robota. Dodatkowo wprowadzono specjalny termin „skończonego czasu”, dzięki któremu błędy śledzenia nie tylko stopniowo maleją, lecz są wymuszane do redukcji w zagwarantowanym krótkim przedziale czasu.
Jak działa nowe sterowanie
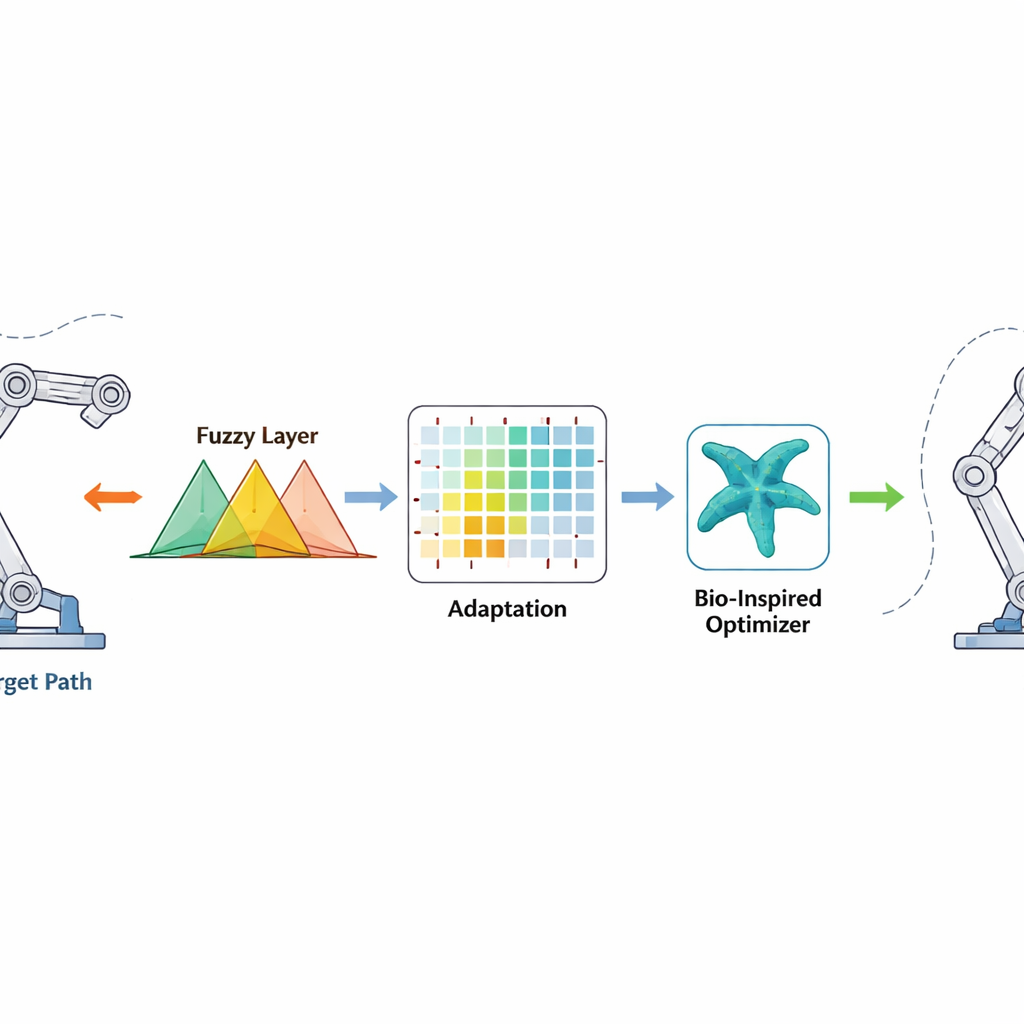
Regulator monitoruje, jak daleko każdy przegub znajduje się od żądanego kąta oraz jak szybko zmienia się ten błąd. Sygnały te przechodzą przez reguły rozmyte — zestawy nakładających się instrukcji „jeśli–to”, które potrafią radzić sobie z niepewnością i nieliniowością — aby wygenerować gładkie polecenie momentu obrotowego dla silników. Uczenie ze wzmocnieniem działa w tle i online dostosowuje parametry reguł rozmytych, nagradzając działania, które szybko zmniejszają błędy, i karząc te, które powodują przeregulowanie lub drgania. Optymalizator rozgwiazda pracuje wcześniej, w fazie offline, szukając dobrego początkowego zestawu parametrów rozmytych, naśladując sposób, w jaki rozgwiazdy eksplorują i doskonalą swoją pozycję w oceanie. Taki dobry punkt startowy przyspiesza uczenie po włączeniu robota, a termin korekcji skończonego czasu dodaje silne, nieliniowe działanie, które redukuje błędy do wartości bliskich zeru w ograniczonym czasie, nawet gdy masa robota lub warunki otoczenia zmieniają się niespodziewanie.
Testy na symulowanych ramionach i nogach
Aby przetestować pomysł, badacze użyli modeli komputerowych dwóch robotów. Pierwszy to prosty system dwustawowy często używany do naśladowania nogi kroczącej, w którym jeden przegub celowo pozbawiono bezpośredniego napędu, co reprezentuje sytuację niedoaktuowaną i trudniejszą do kontrolowania. Drugi to pięciostawowe ramię przypominające lekką kończynę humanoidalną. W obu przypadkach zadane ruchy stawów miały płynne, falowe trajektorie, a masy ogniw robota były losowo zmieniane w czasie za pomocą procesu statystycznego imitującego realistyczne, powoli zmieniające się ładunki. Dodatkowo wprowadzono zaburzenia, takie jak losowe pchnięcia i ograniczenia momentu, aby obciążyć regulator.
Co pokazują symulacje
W wielu próbach nowy regulator utrzymywał stawy robota blisko żądanych trajektorii, z końcowymi błędami kątowymi typowo w granicach około 0,02–0,04 radiana — czyli tylko kilka milimetrów na końcu ramienia. W porównaniu z klasyczną regulacją proporcjonalno-całkująco-różniczkującą (PID) i bardziej zaawansowanymi metodami adaptacyjnymi, proponowane podejście zmniejszyło całkowity błąd śledzenia aż o około 60% dla systemu dwustawowego i około 30–35% dla ramienia pięciostawowego. Dodatkowo układ szybciej wchodził w płynny ruch, często w czasie krótszym niż półtorej sekundy, oraz zużywał około 15% mniej nakładu sterowania, co przekłada się na mniejsze zużycie energii i zmniejszone zużycie silników. Nawet w ekstremalnych testach — na przykład przy podwojeniu efektywnej masy równocześnie ograniczając dostępny moment — regulator utrzymywał stabilny ruch i unikał gwałtownych oscylacji.
Co to oznacza dla codziennej robotyki
Dla odbiorców niespecjalistycznych kluczowy wniosek jest taki, że roboty nie muszą znać każdego szczegółu własnej mechaniki, aby poruszać się niezawodnie w zmieniającym się świecie. Łącząc ludzkopodobne rozumowanie „rozmyte”, uczenie przez próbę i błąd oraz sprytny krok wstępnego dostrojenia inspirowany rozgwiazdami, opisany schemat sterowania pozwala robotom wielostawowym adaptować się w locie do zmieniających się obciążeń i zakłóceń, zachowując jednocześnie gwarancję szybkiej redukcji błędów. Jeśli podejście to potwierdzi się na rzeczywistym sprzęcie, takie metody mogą uczynić roboty serwisowe, urządzenia wspomagające i zwinne ramiona przemysłowe bezpieczniejszymi i bardziej wydajnymi, nawet gdy będą musiały wykonywać nowe zadania, obsługiwać nowe narzędzia i działać w nowych środowiskach bez rozległego przeprogramowywania.
Cytowanie: Duan, C., Wang, L. & Li, S. Fuzzy adaptive nonlinear MIMO control for rigid coupled multibody robots using reinforcement learning model. Sci Rep 16, 11458 (2026). https://doi.org/10.1038/s41598-026-40982-w
Słowa kluczowe: sterowanie robotem, uczenie ze wzmocnieniem, logika rozmyta, robotyka adaptacyjna, śledzenie trajektorii