Clear Sky Science · tr
Tüm Hint dillerindeki tabela isimlerinden ilgi noktası çıkarımını geliştirmek için sahne metni tespiti ve tanıma tekniklerini kullanan entegre çerçeve
Çokdilli Bir Ulus İçin Akıllı Haritalar
Bir Hint şehrinde yolunuzu bulmak genellikle birçok farklı yazı sisteminde yazılmış mağaza tabelaları, reklam panoları ve sokak levhalarının bulanık görüntülerine bakmayı gerektirir. İnsanlar bunu kolayca yaparken dijital haritalar ve navigasyon araçları bu tabelaları güvenilir biçimde okumakta hâlâ zorlanıyor. Bu makale, bilgisayarlara gerçek dünya görüntülerindeki metinleri neredeyse tüm büyük Hint yazı sistemlerinde tespit etmeyi ve okumayı öğreten, ardından bu bilgiyi temiz, aranabilir ilgi noktalarına dönüştüren entegre bir sistemi sunuyor — daha akıllı navigasyon, daha iyi yerel arama ve daha kapsayıcı dijital hizmetlerin yolunu açıyor.
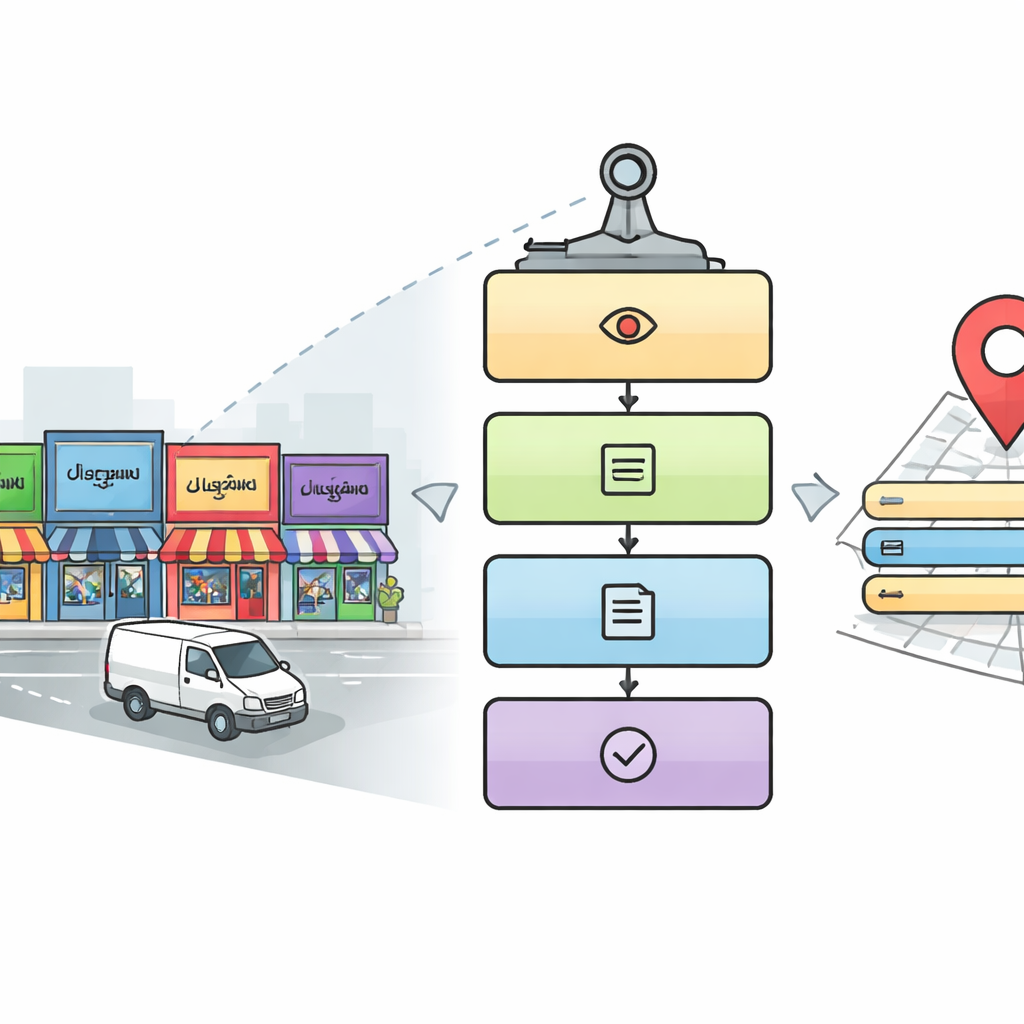
Sokak Tabelalarını Makinalar İçin Neden Okumak Zor?
Düzenli basılı sayfaların aksine sokak sahneleri görsel olarak karmaşıktır. Metinler garip açılarda, farklı boyutlarda ve kalabalık arka planlar önünde görünür. Hindistan’da durum, Devanagari, Tamil, Bengalce gibi birçok yazı sisteminin kullanımıyla daha da karmaşık hâle gelir; bunlar ilk bakışta benzer görünebilir ancak önemli ayrıntılarda farklılık gösterir. Geleneksel optik karakter tanıma çoğunlukla Latin alfabeleri ve temiz belgeler için geliştirildiğinden, hareket halindeki araçlardan alınan düşük çözünürlüklü fotoğraflar, üst üste binmiş tabelalar ve dekoratif yazı tipleriyle karşılaştığında başarısız olur. Yazarlar, bu gerçek dünya zorluklarını doğrudan ele almak için şehir sokaklarını tarayan kameralı araçlarla elde edilen Mobil Haritalama Sistemleri tarafından yakalanan görüntülere odaklanıyor.
Şehir Sokakları İçin Beş Adımlı Dijital Okuyucu
Araştırmacılar, dikkatli bir insanın karmaşık bir sokak manzarasını nasıl okuyabileceğini taklit eden beş aşamalı bir boru hattı tasarlıyor. İlk olarak, bir tespit modülü her görüntüyü olası tabela ve isim panosu içeren alanları bulmak için popüler bir nesne tespiti yaklaşımı olan YOLOv5’i kullanarak tarar. Ardından sistem, bu alanların içindeki metin bölgelerini kırpar. Üçüncü aşamada, ResNet ağlarına dayalı bir derin öğrenme modeli her kırpılmış kelimenin hangi yazı sistemiyle yazıldığını belirler; on adet Hint yazı sistemi ile İngilizce arasından seçim yapar. Yazı sistemi belirlendikten sonra dördüncü aşama, kelimenin görüntüsünü dijital metne dönüştürmek için eşleme tabanlı bir karakter tanıyıcı kullanır. Son olarak beşinci, paralel aşama görüntüde yer adları, adres öğeleri, telefon numaraları, posta kodu, simgeler ve vergi kimlik numarası gibi anahtar ayrıntıları arar ve bunları eksiksiz, insan tarafından okunabilir bir adrese ve yapılandırılmış dijital bir kayda dönüştürür.
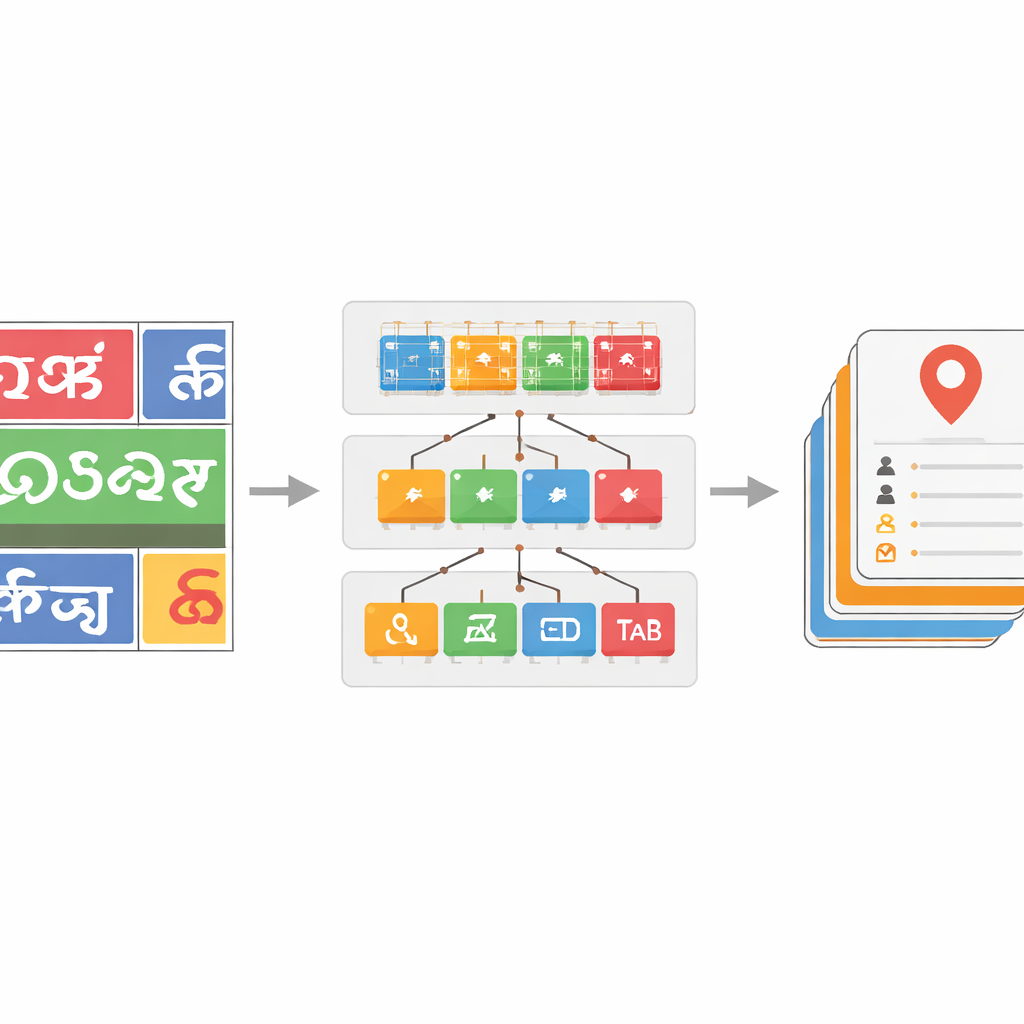
Sistemi Çoklu Yazı Sistemleri ve Gürültülü Metinle Başa Çıkmaya Öğretmek
Yazı sistemi sınıflandırıcısını sağlam kılmak için ekip, gerçek sokak görüntülerinden alınmış kelime görüntülerinin büyük bir veri setini, kamuya açık veri setleri ve sentetik örneklerle destekleyerek küratörlüğünü yapıyor. Trafikte kameraların gördüğünü taklit etmek için bulanıklık, gürültü ve perspektif değişiklikleri gibi gerçekçi bozulmalar uyguluyorlar. Daha derin ResNet modelleri özellikle etkili oluyor; en güçlü sürüm olan ResNet-152, yazı sistemlerini ayırt etmede yaklaşık yüzde 96 doğruluk elde ederek Hint sahne metni için önceki kıyas noktalarını geride bırakıyor. Bunun üzerine, tanınan kelimeler için sözlük tabanlı bir düzeltme adımı ekliyorlar. Açıklanmış verilerden dil-özel kelime listeleri oluşturarak ve her tahmin edilen kelimeyi düzenleme mesafesi (edit-distance) ölçüleriyle yakın sözlük girişleriyle karşılaştırarak, açgözlü bir arama algoritması genellikle yanlış okunan karakterleri düzeltebiliyor. Bu, bazı yazı sistemlerinde kelime düzeyinde doğrulukta 17 puana kadar artış sağlayarak gürültülü çıktıları önemli ölçüde temizliyor.
Ham Görüntülerden Kullanılabilir İlgi Noktalarına
Kalabalık panolarda telefon numaraları veya vergi kimlikleri gibi küçük alanların tam konumunu tespit etmek hâlâ zordur ve nesne algılayıcısının ortalama kesinliği yüzde 33 bu zorluğu yansıtıyor. Ancak yazarlar, mükemmel olmayan sınırlayıcı kutuların bile sonraki metin ve düzeltme aşamalarına beslenmek için yeterli olabileceğini gösteriyor; burada sözlük ve yazı sistemi farkındalıklı modeller her bölgenin gerçekte ne içerdiğini ayırt etmeye yardımcı oluyor. Tüm bu modülleri koordine eden merkezi bir yazılım "köprü" katmanı veri formatlarını standartlaştırıyor, düşük güvene sahip çıktıları filtreliyor ve sistemin bir bölümünde aksama olduğunda geri dönüş stratejileri uyguluyor. Güncel yaklaşımlarla karşılaştırıldığında, tam boru hattı yazı sistemi tanıma, kelime tanıma ve ilgi noktası alan tespitinde önceki sistemleri geride bırakıyor; özellikle küresel veri setlerinde sıklıkla yeterince temsil edilmeyen düşük kaynaklı Hint yazı sistemlerinde belirgin iyileşmeler gösteriyor.
Günlük Kullanıcılar İçin Anlamı
Mevcut derin öğrenme araçlarını dil-özel veriler ve akıllı bir düzeltme katmanıyla dikkatle birleştirerek, yazarlar çok dilli Hint sokak tabelalarını ölçekte okuyup anlayabilen pratik, uçtan uca bir sistem inşa ediyor. Nihai çıktı, her ilgi noktası için isim, iletişim bilgileri ve diğer temel alanlarla birlikte yapılandırılmış, makine tarafından okunabilir bir açıklama; bu doğrudan dijital haritalara, navigasyon uygulamalarına ve yerel arama motorlarına entegre edilebilir. Günlük kullanıcılar için bu, daha doğru yol tarifleri, yakındaki hizmetlerin daha iyi keşfi ve Hindistan’ın birçok yazı sistemi ve dili arasında eşit biçimde çalışan dijital araçlar anlamına gelebilir. Çalışma, düşünceli mühendislikle yapay zekanın her şeyi tek bir yazı sistemine zorlamak yerine dilsel çeşitliliği koruyup değerlendirmeye yardımcı olabileceğini gösteriyor.
Atıf: Kashyap, A.K., Upadhya, M., Panwar, V.S. et al. Integrated framework utilizing scene text detection and recognition techniques for enhancing point of interest extraction from name boards in all Indic languages. Sci Rep 16, 12907 (2026). https://doi.org/10.1038/s41598-026-40742-w
Anahtar kelimeler: sahne metni tanıma, çokdilli OCR, Hint yazı sistemleri, ilgi noktası çıkarımı, derin öğrenme görüsü