Clear Sky Science · de
Integriertes Framework unter Verwendung von Szenentexterkennungs- und -erkennungstechniken zur Verbesserung der Extraktion von Points of Interest von Namensschildern in allen indischen Sprachen
Intelligente Karten für ein mehrsprachiges Land
Sich in einer indischen Stadt zurechtzufinden bedeutet oft, ein Durcheinander aus Ladenbeschilderungen, Werbetafeln und Straßenschildern in vielen verschiedenen Schriften zu überfliegen. Menschen tun das mühelos, doch digitale Karten und Navigationswerkzeuge haben weiterhin Schwierigkeiten, diese Schilder zuverlässig zu lesen. Dieses Papier stellt ein integriertes System vor, das Computern beibringt, Text in realen Bildern in nahezu allen wichtigen indischen Schriften zu erkennen und zu lesen und diese Informationen dann in saubere, durchsuchbare Points of Interest umzuwandeln — ein Schritt hin zu intelligenterer Navigation, besserer lokaler Suche und inklusiveren digitalen Diensten.
Warum das Lesen von Straßenschildern für Maschinen so schwierig ist
Im Gegensatz zu ordentlichen Druckseiten sind Straßenszenen visuell unordentlich. Text erscheint in schrägen Winkeln, in verschiedenen Größen und vor überladenen Hintergründen. In Indien wird dies zusätzlich durch die Verwendung vieler Schriften — wie Devanagari, Tamil, Bengali und andere — verkompliziert, die auf den ersten Blick ähnlich wirken können, sich aber in entscheidenden Details unterscheiden. Traditionelle optische Zeichenerkennung, die hauptsächlich für lateinische Alphabete und saubere Dokumente entwickelt wurde, versagt bei niedrig aufgelösten Fotos von fahrenden Fahrzeugen, überlappenden Schildern und dekorativen Schriftarten. Die Autoren konzentrieren sich auf Bilder, die von Mobile-Mapping-Systemen aufgenommen wurden — Fahrzeugen mit Kameras, die Stadtstraßen vermessen — um diese realen Herausforderungen direkt anzugehen.
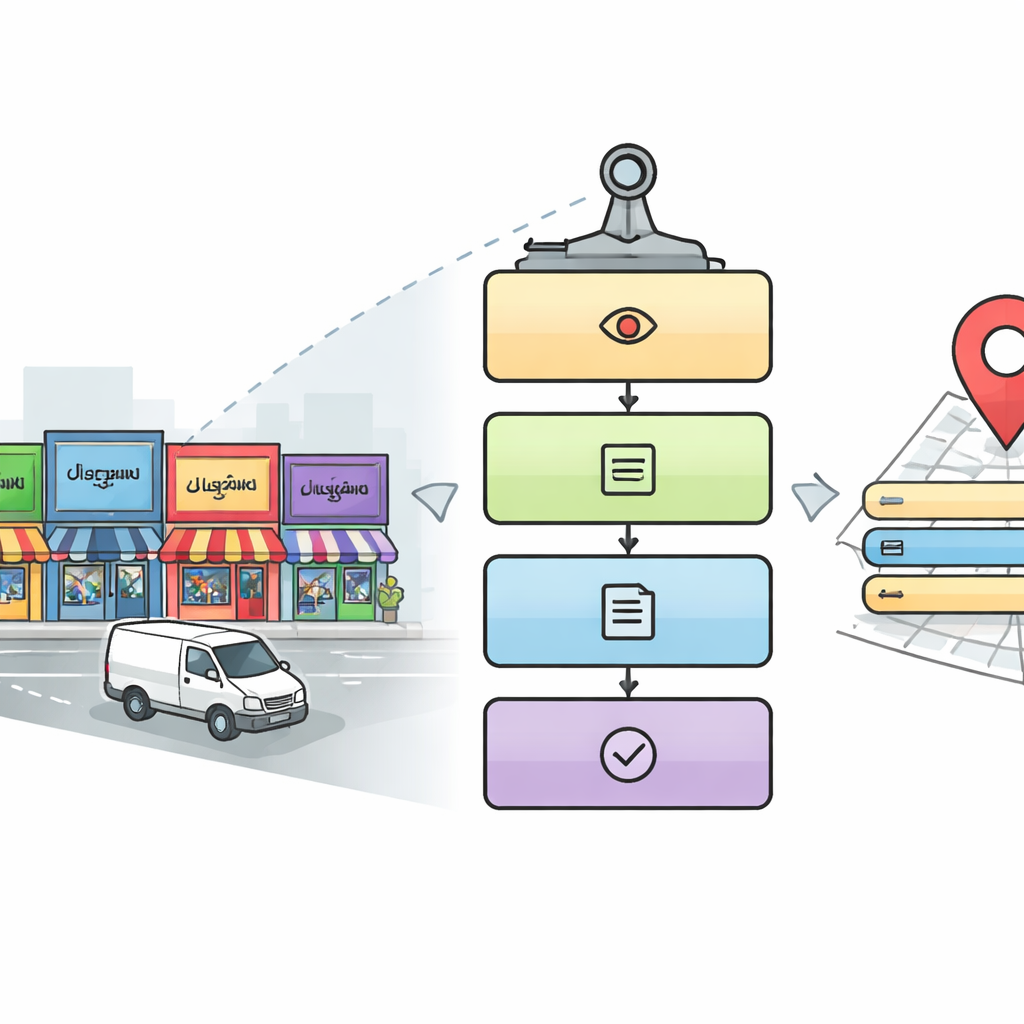
Ein fünfstufiger digitaler Leser für Stadtstraßen
Die Forschenden entwerfen eine fünfstufige Pipeline, die nachahmt, wie ein sorgfältiger Mensch eine komplexe Straßenszenerie lesen würde. Zuerst durchsucht ein Detektionsmodul jedes Bild nach Bereichen, die wahrscheinlich relevante Schilder und Namensschilder enthalten, und verwendet dafür einen verbreiteten Objekterkennungsansatz namens YOLOv5. Anschließend schneidet das System die Textregionen innerhalb dieser Bereiche aus. Im dritten Schritt identifiziert ein Deep-Learning-Modell auf Basis von ResNet-Netzwerken, in welcher Schrift jedes ausgeschnittene Wort geschrieben ist, wobei zwischen zehn indischen Schriften sowie Englisch unterschieden wird. Ist die Schrift bekannt, nutzt die vierte Stufe einen passenden Zeichenerkenner, um das Wortbild in digitalen Text zu konvertieren. Schließlich durchsucht eine fünfte, parallele Stufe das Bild nach wichtigen Details — wie Ortsnamen, Adresselementen, Telefonnummer, Postleitzahl, Icons und Steuernummer — und fügt diese zu einer vollständigen, für Menschen lesbaren Adresse und einem strukturierten digitalen Datensatz zusammen.
Dem System beibringen, viele Schriften und verrauschte Texte zu verarbeiten
Um den Schriftklassifikator robust zu machen, kuratiert das Team einen großen Datensatz von Wortbildern aus realen Straßenszenen, ergänzt durch öffentliche Datensätze und synthetische Beispiele. Sie wenden realistische Verzerrungen — wie Unschärfe, Rauschen und Perspektivänderungen — an, um zu simulieren, was Kameras im Verkehr sehen. Tiefere ResNet-Modelle erweisen sich als besonders wirksam; die leistungsstärkste Version, ResNet-152, erreicht etwa 96 Prozent Genauigkeit bei der Unterscheidung der Schriften und übertrifft damit frühere Benchmarks für Szenentext in indischen Schriften. Darüber hinaus führen sie einen wörterbuchbasierten Korrekturschritt für erkannte Wörter ein. Durch den Aufbau sprachspezifischer Wortlisten aus annotierten Daten und den Vergleich jedes vorhergesagten Wortes mit benachbarten Wörterbucheinträgen mittels Edit-Distanz kann ein gieriger Suchalgorithmus häufig falsch gelesene Zeichen korrigieren. Dies führt in einigen Schriften zu Wortgenauigkeitsgewinnen von bis zu 17 Prozentpunkten und bereinigt damit verrauschte Ausgaben erheblich.
Von Rohbildern zu verwertbaren Points of Interest
Die genaue Lokalisierung kleiner Felder wie Telefonnummern oder Steuernummern auf überfüllten Schildern bleibt schwierig, und die durchschnittliche Präzision des Objektdetektors von 33 Prozent spiegelt diese Herausforderung wider. Die Autoren zeigen jedoch, dass selbst unvollkommene Begrenzungsrahmen oft ausreichend sind, um in spätere Texterkennungs- und Korrekturschritte eingespeist zu werden, wo Wörterbuch- und schrifterkennungsbewusste Modelle helfen, zu klären, welchen Inhalt jede Region tatsächlich enthält. Eine zentrale Software-„Brücken“-Schicht koordiniert all diese Module, standardisiert Datenformate, filtert Ausgaben mit geringer Zuverlässigkeit und wendet Fallback-Strategien an, wenn ein Systemteil ausfällt. Bei der Evaluation gegen neuere Ansätze übertrifft die komplette Pipeline frühere Systeme in Schrifts-, Wort- und Point-of-Interest-Felderkennung, insbesondere für ressourcenarme indische Schriften, die in globalen Datensätzen oft unterrepräsentiert sind.
Was das für tägliche Nutzer bedeutet
Durch die sorgfältige Kombination bestehender Deep-Learning-Werkzeuge mit sprachspezifischen Daten und einer intelligenten Korrekturschicht bauen die Autoren ein praktisches End-to-End-System, das mehrsprachige indische Straßenschilder in großem Umfang lesen und verstehen kann. Die Endausgabe ist eine strukturierte, maschinenlesbare Beschreibung jedes Point of Interest — vollständig mit Name, Kontaktdaten und anderen wichtigen Feldern —, die direkt in digitale Karten, Navigations-Apps und lokale Suchmaschinen eingespeist werden kann. Für Alltagsnutzer könnte das genauere Wegbeschreibungen, bessere Entdeckung lokaler Dienste und digitale Werkzeuge bedeuten, die über Indiens vielfältige Schriften und Sprachen hinweg gleichermaßen funktionieren. Die Arbeit zeigt, dass durch durchdachte Ingenieurskunst die künstliche Intelligenz helfen kann, sprachliche Vielfalt zu bewahren und zu nutzen, anstatt alles auf eine einzige Schrift zu zwängen.
Zitation: Kashyap, A.K., Upadhya, M., Panwar, V.S. et al. Integrated framework utilizing scene text detection and recognition techniques for enhancing point of interest extraction from name boards in all Indic languages. Sci Rep 16, 12907 (2026). https://doi.org/10.1038/s41598-026-40742-w
Schlüsselwörter: Szenentexterkennung, mehrsprachige OCR, indische Schriftsysteme, Extraktion von Points of Interest, Deep-Learning-Computer-Vision