Clear Sky Science · it
Quadro integrato che utilizza tecniche di rilevamento e riconoscimento del testo di scena per migliorare l’estrazione dei punti di interesse dalle insegne in tutte le lingue indiane
Mappe intelligenti per una nazione multilingue
Trovare la strada in una città indiana spesso significa decifrare un miscuglio di insegne di negozi, cartelloni e targhe stradali scritti in molti alfabeti diversi. Gli esseri umani lo fanno con facilità, ma le mappe digitali e gli strumenti di navigazione faticano ancora a leggere questi segnali in modo affidabile. Questo articolo presenta un sistema integrato che insegna ai computer a individuare e leggere il testo da immagini del mondo reale in quasi tutte le principali scritture indiane, per poi trasformare quelle informazioni in punti di interesse puliti e ricercabili—aprendo la strada a una navigazione più intelligente, a una ricerca locale migliore e a servizi digitali più inclusivi.
Perché leggere le insegne è così difficile per le macchine
A differenza delle pagine stampate ordinate, le scene stradali sono visivamente caotiche. Il testo appare ad angolazioni strane, in dimensioni diverse e su sfondi affollati. In India, la situazione è ulteriormente complicata dall’uso di molte scritture—come Devanagari, Tamil, Bengali e altre—che a prima vista possono sembrare simili ma differiscono in dettagli decisivi. Il riconoscimento ottico tradizionale, pensato principalmente per alfabeti latini e documenti puliti, vacilla di fronte a foto a bassa risoluzione scattate da veicoli in movimento, insegne sovrapposte e caratteri decorativi. Gli autori si concentrano su immagini catturate da Mobile Mapping System—veicoli dotati di telecamere che sorvegliano le strade cittadine—per affrontare direttamente queste sfide reali.
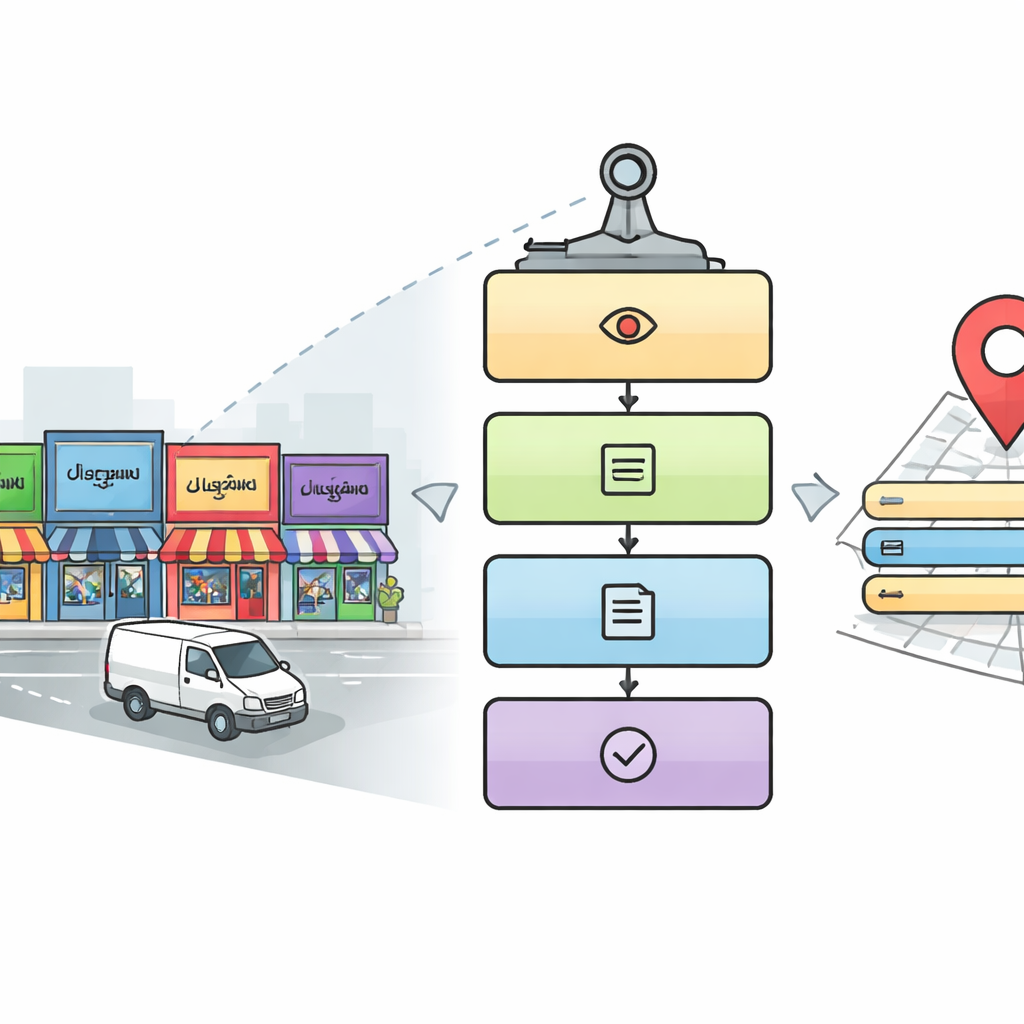
Un lettore digitale in cinque passaggi per le strade cittadine
I ricercatori progettano una pipeline in cinque fasi che imita come una persona attenta potrebbe leggere un paesaggio urbano complesso. Prima, un modulo di rilevamento analizza ogni immagine per trovare aree che potrebbero contenere insegne e targhe, usando un noto approccio di object-detection chiamato YOLOv5. Poi il sistema ritaglia le regioni di testo all’interno di quelle aree. Nella terza fase, un modello di deep learning basato su reti ResNet identifica in quale scrittura è scritto ciascun termine ritagliato, scegliendo tra dieci scritture indiane più l’inglese. Una volta noto l’alfabeto, la quarta fase utilizza un riconoscitore di caratteri corrispondente per convertire l’immagine della parola in testo digitale. Infine, una quinta fase parallela cerca nell’immagine dettagli chiave—come nome del luogo, elementi di indirizzo, numero di telefono, codice postale, icone e partita IVA—and li assemblano in un indirizzo completo leggibile dall’uomo e in un record digitale strutturato.
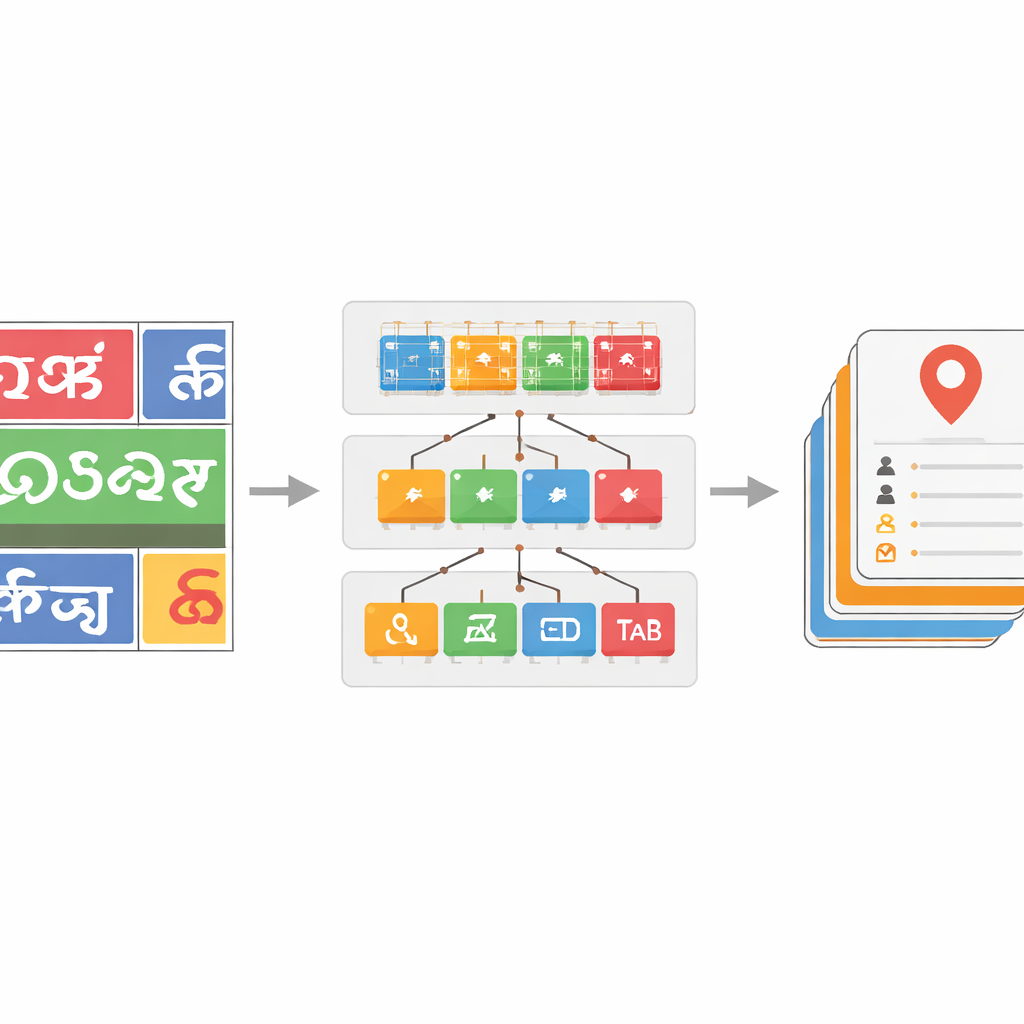
Addestrare il sistema a gestire molte scritture e testo rumoroso
Per rendere il classificatore di scrittura robusto, il team cura un grande set di dati di immagini di parole tratte da immagini stradali reali, integrato con dataset pubblici e campioni sintetici. Applicano distorsioni realistiche—come sfocatura, rumore e cambi di prospettiva—per imitare ciò che le telecamere vedono nel traffico. Le versioni più profonde delle ResNet si dimostrano particolarmente efficaci: la più potente, ResNet-152, raggiunge circa il 96 percento di accuratezza nel distinguere le scritture, meglio dei benchmark precedenti per il testo di scena in lingue indiane. Inoltre, introducono un passaggio di correzione basato su dizionari per le parole riconosciute. Costruendo liste di parole specifiche per lingua a partire dai dati annotati e confrontando ogni parola prevista con voci di dizionario vicine mediante misure di distanza di edit (edit distance), un algoritmo greedy può spesso correggere caratteri letti male. Questo produce guadagni di accuratezza a livello di parola fino a 17 punti percentuali in alcune scritture, pulendo notevolmente le uscite rumorose.
Dalle immagini grezze a punti di interesse utilizzabili
Rilevare la posizione esatta di campi piccoli come numeri di telefono o partite IVA su bacheche affollate resta difficile, e la precisione media dell’object detector del 33 percento riflette questa sfida. Tuttavia, gli autori mostrano che anche box imperfetti possono essere sufficienti per alimentare le fasi successive di riconoscimento e correzione, dove il dizionario e i modelli consapevoli della scrittura aiutano a chiarire cosa contiene realmente ogni regione. Uno strato software centrale a «ponte» coordina tutti questi moduli, standardizzando i formati dei dati, filtrando le uscite a bassa confidenza e applicando strategie di fallback quando una parte del sistema fallisce. Valutata rispetto ad approcci recenti, l’intera pipeline supera i sistemi precedenti nel riconoscimento della scrittura, nel riconoscimento delle parole e nella rilevazione dei campi dei punti di interesse, in particolare per le scritture indiane a bassa risorsa spesso sottorappresentate nei dataset globali.
Cosa significa questo per gli utenti di tutti i giorni
Combinando con cura strumenti di deep learning esistenti con dati specifici per lingua e uno strato di correzione intelligente, gli autori costruiscono un sistema pratico end-to-end in grado di leggere e comprendere su larga scala le insegne stradali multilingue indiane. L’output finale è una descrizione strutturata e leggibile da macchina di ciascun punto di interesse—completa di nome, contatti e altri campi chiave—che può essere integrata direttamente nelle mappe digitali, nelle app di navigazione e nei motori di ricerca locali. Per gli utenti quotidiani, ciò può tradursi in indicazioni più accurate, una migliore scoperta di servizi nelle vicinanze e strumenti digitali che funzionano altrettanto bene attraverso le molte scritture e lingue dell’India. Il lavoro dimostra che con un’ingegneria attenta, l’intelligenza artificiale può aiutare a preservare e sfruttare la diversità linguistica invece di imporre tutto in un’unica scrittura.
Citazione: Kashyap, A.K., Upadhya, M., Panwar, V.S. et al. Integrated framework utilizing scene text detection and recognition techniques for enhancing point of interest extraction from name boards in all Indic languages. Sci Rep 16, 12907 (2026). https://doi.org/10.1038/s41598-026-40742-w
Parole chiave: riconoscimento del testo di scena, OCR multilingue, scritture indiane, estrazione di punti di interesse, visione profonda (deep learning)