Clear Sky Science · es
Marco integrado que utiliza técnicas de detección y reconocimiento de texto en escena para mejorar la extracción de puntos de interés de letreros en todas las lenguas indias
Mapas inteligentes para una nación multilingüe
Encontrar el camino en una ciudad india a menudo implica escanear una mezcla confusa de rótulos de tiendas, vallas publicitarias y carteles callejeros escritos en muchos alfabetos diferentes. Los humanos lo hacen con facilidad, pero los mapas digitales y las herramientas de navegación todavía tienen dificultades para leer estos letreros de forma fiable. Este artículo presenta un sistema integrado que enseña a los ordenadores a detectar y leer texto en imágenes del mundo real en casi todas las principales escrituras indias, y a convertir esa información en puntos de interés limpios y buscables, allanando el camino para una navegación más inteligente, mejor búsqueda local y servicios digitales más inclusivos.
Por qué leer carteles callejeros es tan difícil para las máquinas
A diferencia de las páginas impresas ordenadas, las escenas callejeras son visualmente desordenadas. El texto aparece en ángulos extraños, en distintos tamaños y sobre fondos cargados. En India, esto se complica aún más por el uso de muchas escrituras—como devanagari, tamil, bengalí y otras—que pueden parecer similares a primera vista pero difieren en detalles críticos. El reconocimiento óptico de caracteres tradicional, diseñado principalmente para alfabetos latinos y documentos limpios, falla frente a fotos de baja resolución tomadas desde vehículos en movimiento, carteles solapados y tipografías decorativas. Los autores se centran en imágenes capturadas por Sistemas de Mapeo Móvil—vehículos equipados con cámaras que recorren las calles—para abordar estos retos del mundo real de forma directa.
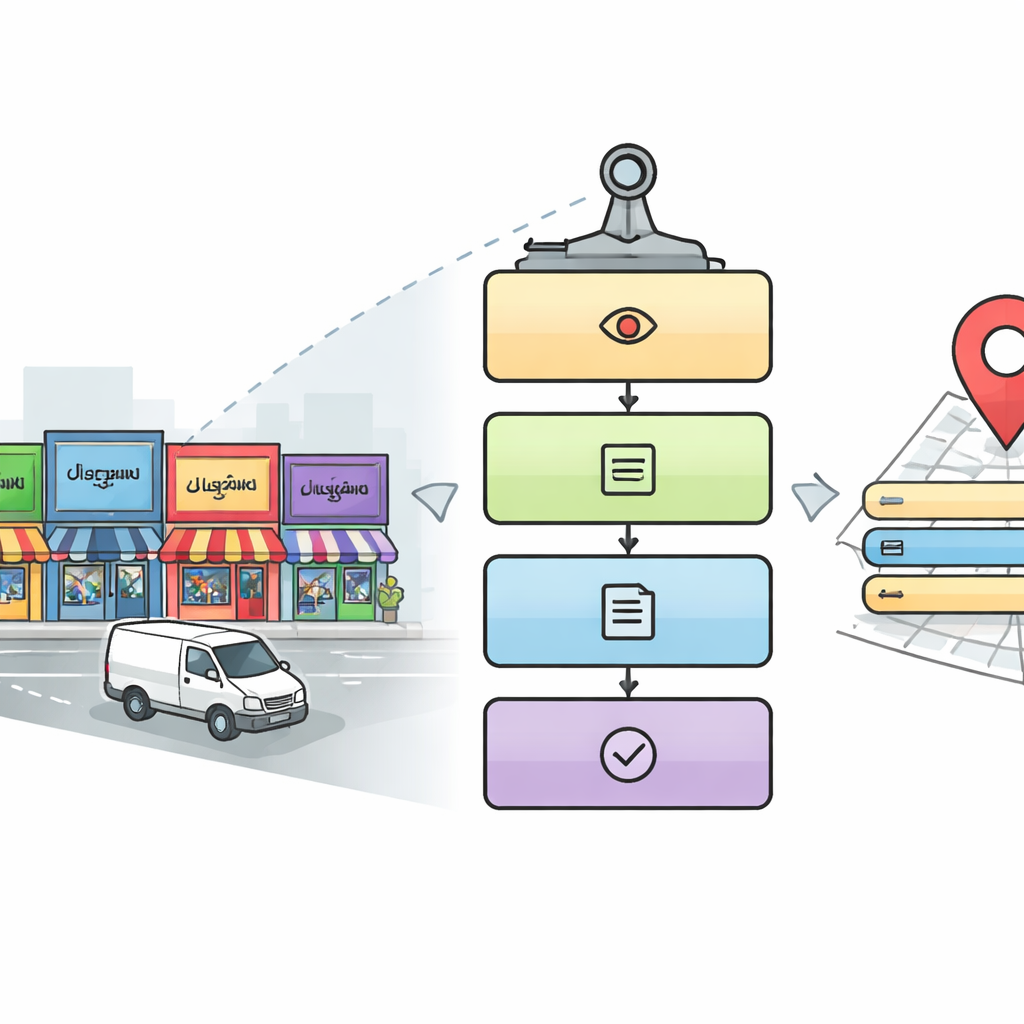
Un lector digital de cinco pasos para las calles de la ciudad
Los investigadores diseñan una canalización en cinco etapas que imita cómo un humano cuidadoso podría leer un paisaje urbano complejo. Primero, un módulo de detección escanea cada imagen para encontrar áreas que probablemente contengan rótulos y letreros, usando un enfoque popular de detección de objetos llamado YOLOv5. A continuación, el sistema recorta las regiones de texto dentro de esas áreas. En la tercera etapa, un modelo de aprendizaje profundo basado en redes ResNet identifica en qué escritura está escrito cada recorte de palabra, eligiendo entre diez escrituras índicas más inglés. Una vez conocida la escritura, una cuarta etapa emplea un reconocedor de caracteres emparejado para convertir la imagen de la palabra en texto digital. Finalmente, una quinta etapa, ejecutada en paralelo, busca en la imagen detalles clave—como nombre del lugar, elementos de la dirección, número de teléfono, código postal, iconos y número de identificación fiscal—y los ensambla en una dirección completa legible por humanos y en un registro digital estructurado.
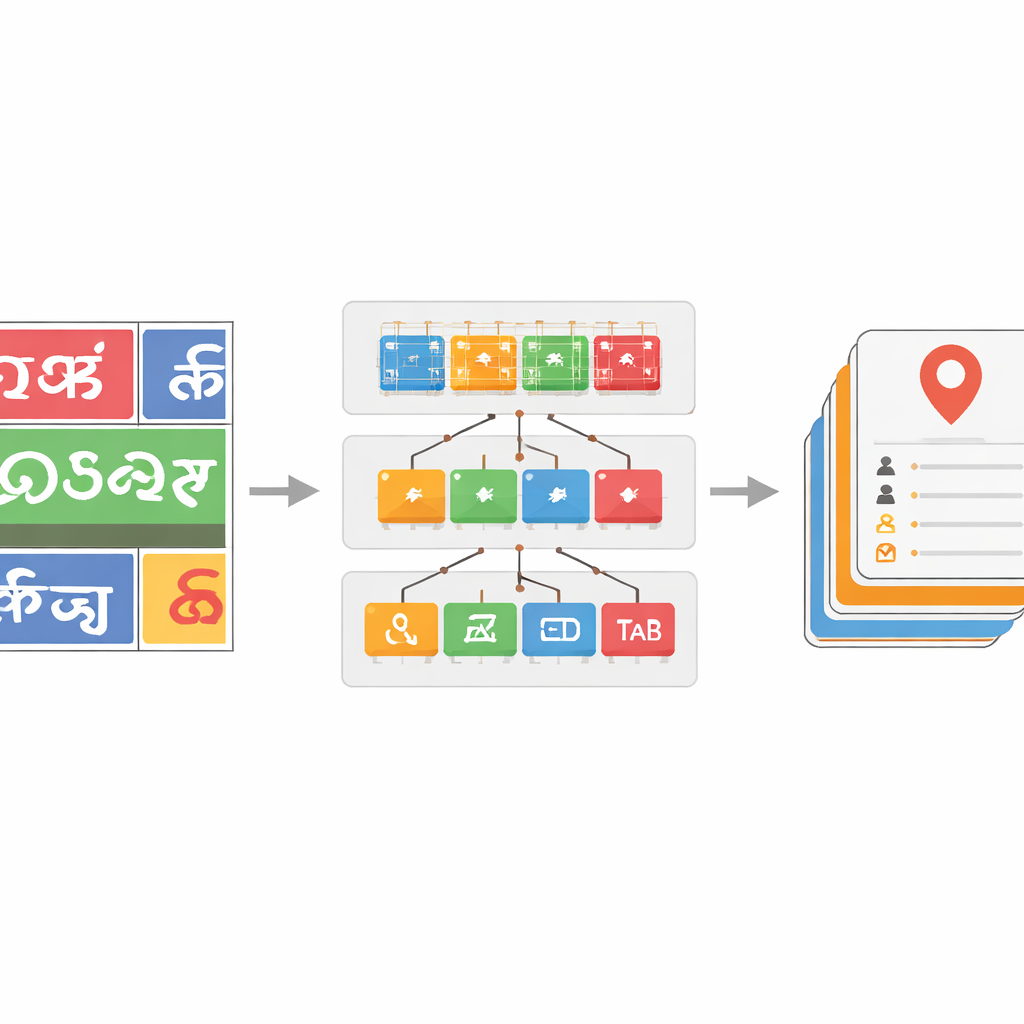
Enseñar al sistema a manejar muchas escrituras y texto ruidoso
Para hacer el clasificador de escrituras robusto, el equipo selecciona un gran conjunto de datos de imágenes de palabras extraídas de material callejero real, complementado con conjuntos públicos y muestras sintéticas. Aplican distorsiones realistas—como desenfoque, ruido y cambios de perspectiva—para imitar lo que ven las cámaras en el tráfico. Los modelos ResNet más profundos resultan especialmente efectivos, y la versión más potente, ResNet-152, alcanza aproximadamente un 96 por ciento de precisión al distinguir escrituras, mejor que referencias anteriores para texto en escena en escrituras índicas. Sobre esto, introducen un paso de corrección basado en diccionarios para las palabras reconocidas. Al construir listas de palabras específicas por idioma a partir de datos anotados y comparar cada palabra predicha con entradas cercanas del diccionario usando medidas de distancia de edición, un algoritmo de búsqueda voraz puede con frecuencia corregir caracteres mal leídos. Esto proporciona mejoras en la precisión a nivel de palabra de hasta 17 puntos porcentuales en algunas escrituras, limpiando sustancialmente las salidas ruidosas.
De imágenes crudas a puntos de interés utilizables
Detectar la ubicación exacta de campos pequeños como números de teléfono o identificaciones fiscales en carteles abarrotados sigue siendo difícil, y la precisión media del detector de objetos, del 33 por ciento, refleja este desafío. Sin embargo, los autores demuestran que incluso cajas delimitadoras imperfectas pueden ser suficientes para alimentar las etapas posteriores de reconocimiento y corrección, donde el diccionario y los modelos conscientes de la escritura ayudan a determinar qué contiene realmente cada región. Una capa central de software en forma de "puente" coordina todos estos módulos, estandarizando formatos de datos, filtrando salidas de baja confianza y aplicando estrategias de respaldo cuando una parte del sistema falla. Al evaluarse frente a enfoques recientes, la canalización completa supera a sistemas anteriores en reconocimiento de escritura, reconocimiento de palabras y detección de campos de puntos de interés, especialmente para escrituras índicas con pocos recursos que suelen estar infrarrepresentadas en conjuntos de datos globales.
Qué significa esto para los usuarios cotidianos
Al combinar cuidadosamente herramientas de aprendizaje profundo existentes con datos específicos por idioma y una inteligente capa de corrección, los autores construyen un sistema práctico de extremo a extremo que puede leer y entender los rótulos callejeros multilingües de la India a escala. La salida final es una descripción estructurada y legible por máquina de cada punto de interés—completa con nombre, datos de contacto y otros campos clave—que puede integrarse directamente en mapas digitales, aplicaciones de navegación y motores de búsqueda locales. Para los usuarios cotidianos, esto podría traducirse en direcciones más precisas, mejor descubrimiento de servicios cercanos y herramientas digitales que funcionen por igual a través de las muchas escrituras y lenguas de la India. El trabajo demuestra que, con ingeniería cuidadosa, la inteligencia artificial puede ayudar a preservar y aprovechar la diversidad lingüística en lugar de forzar todo a un único alfabeto.
Cita: Kashyap, A.K., Upadhya, M., Panwar, V.S. et al. Integrated framework utilizing scene text detection and recognition techniques for enhancing point of interest extraction from name boards in all Indic languages. Sci Rep 16, 12907 (2026). https://doi.org/10.1038/s41598-026-40742-w
Palabras clave: reconocimiento de texto en escena, OCR multilingüe, escrituras índicas, extracción de puntos de interés, visión profunda (deep learning)