Clear Sky Science · pl
Zintegrowane ramy wykorzystujące techniki wykrywania i rozpoznawania tekstu scenicznego do usprawnienia ekstrakcji punktów zainteresowania z nazw na tablicach we wszystkich językach indyjskich
Inteligentne mapy dla wielojęzycznego kraju
Orientowanie się w indyjskim mieście często oznacza rozczytywanie rozmaitych szyldów sklepów, bilbordów i tablic ulicznych zapisanych w wielu różnych pismach. Ludzie robią to z łatwością, ale cyfrowe mapy i narzędzia nawigacyjne wciąż mają problemy z niezawodnym odczytem takich znaków. W artykule zaprezentowano zintegrowany system, który uczy komputery wykrywać i czytać tekst ze zdjęć rzeczywistych scen w niemal wszystkich głównych indyjskich alfabetach, a następnie przekształca te informacje w czyste, przeszukiwalne punkty zainteresowania — torując drogę do mądrzejszej nawigacji, lepszego lokalnego wyszukiwania i bardziej inkluzywnych usług cyfrowych.
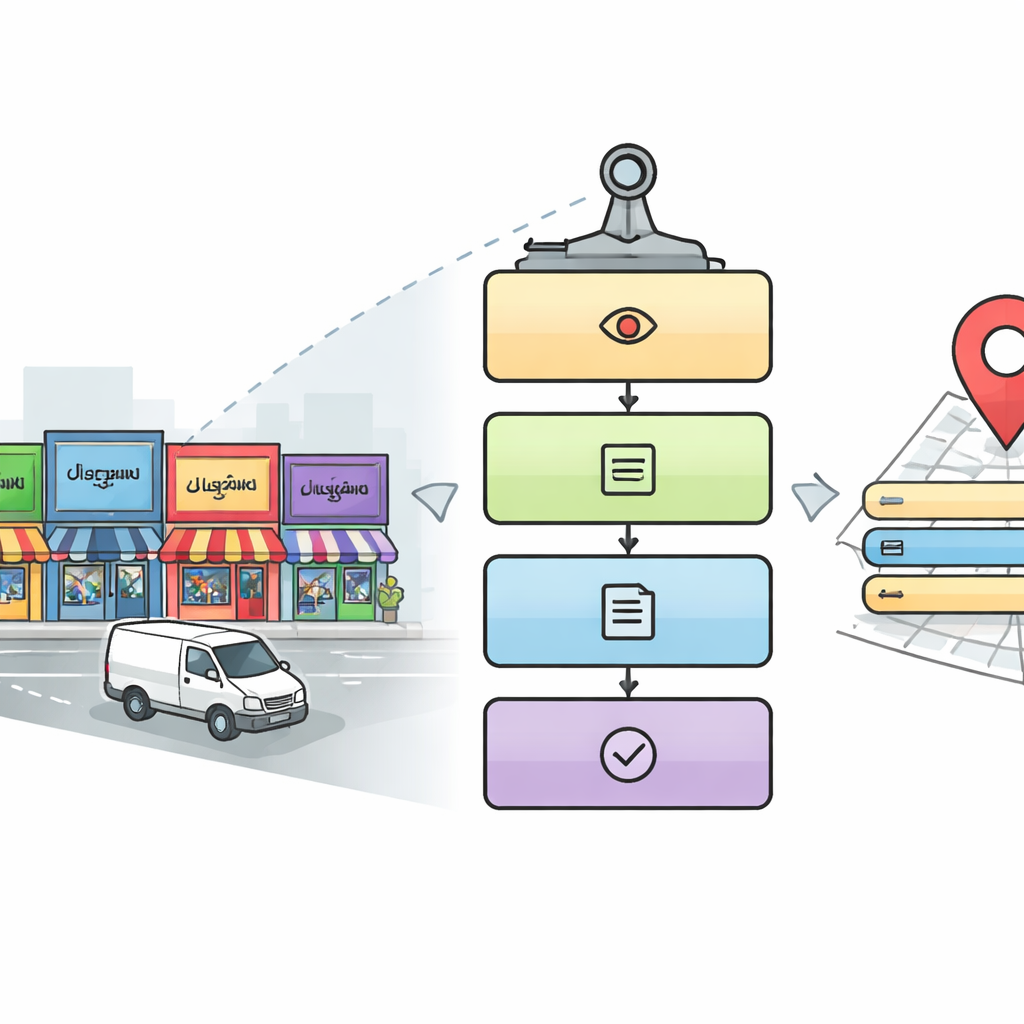
Dlaczego czytanie znaków ulicznych jest dla maszyn takie trudne
W przeciwieństwie do uporządkowanych stron drukowanych, sceny uliczne są wizualnie chaotyczne. Tekst pojawia się pod nietypowymi kątami, w różnych rozmiarach i na zaszumionym tle. W Indiach komplikacje potęguje stosowanie wielu pism — takich jak devanagari, tamilski, bengalski i innych — które z daleka mogą wyglądać podobnie, ale różnią się istotnymi szczegółami. Tradycyjne systemy OCR, skonstruowane głównie pod kątem alfabetów łacińskich i czystych dokumentów, zawodzą wobec niskorozdzielczych zdjęć z poruszających się pojazdów, nakładających się szyldów i ozdobnych fontów. Autorzy skupiają się na obrazach pozyskiwanych przez systemy mobilnego mapowania — pojazdy wyposażone w kamery skanujące ulice — by sprostać tym rzeczywistym wyzwaniom bezpośrednio.
Pięciostopniowy cyfrowy czytnik dla miejskich ulic
Naukowcy zaprojektowali pięcioetapowy proces, który naśladuje sposób, w jaki uważny człowiek mógłby odczytywać złożoną scenę uliczną. Najpierw moduł detekcji skanuje każdy obraz, szukając obszarów, które prawdopodobnie zawierają istotne szyldy i tablice nazw, wykorzystując popularne podejście do wykrywania obiektów o nazwie YOLOv5. Następnie system wycina obszary zawierające tekst. W trzecim etapie model głębokiego uczenia oparty na sieciach ResNet identyfikuje, w jakim piśmie zapisane jest każde wycięte słowo, wybierając spośród dziesięciu pism indyjskich oraz angielskiego. Gdy pismo jest znane, czwarty etap używa rozpoznawacza znaków dopasowanego do danego systemu pisma, aby przekształcić obraz słowa w tekst cyfrowy. Wreszcie piąty, równoległy etap przeszukuje obraz pod kątem kluczowych informacji — takich jak nazwa miejsca, elementy adresu, numer telefonu, kod pocztowy, ikony i numer identyfikacji podatkowej — i składa je w kompletny, czytelny dla człowieka adres oraz ustrukturyzowany rekord cyfrowy.
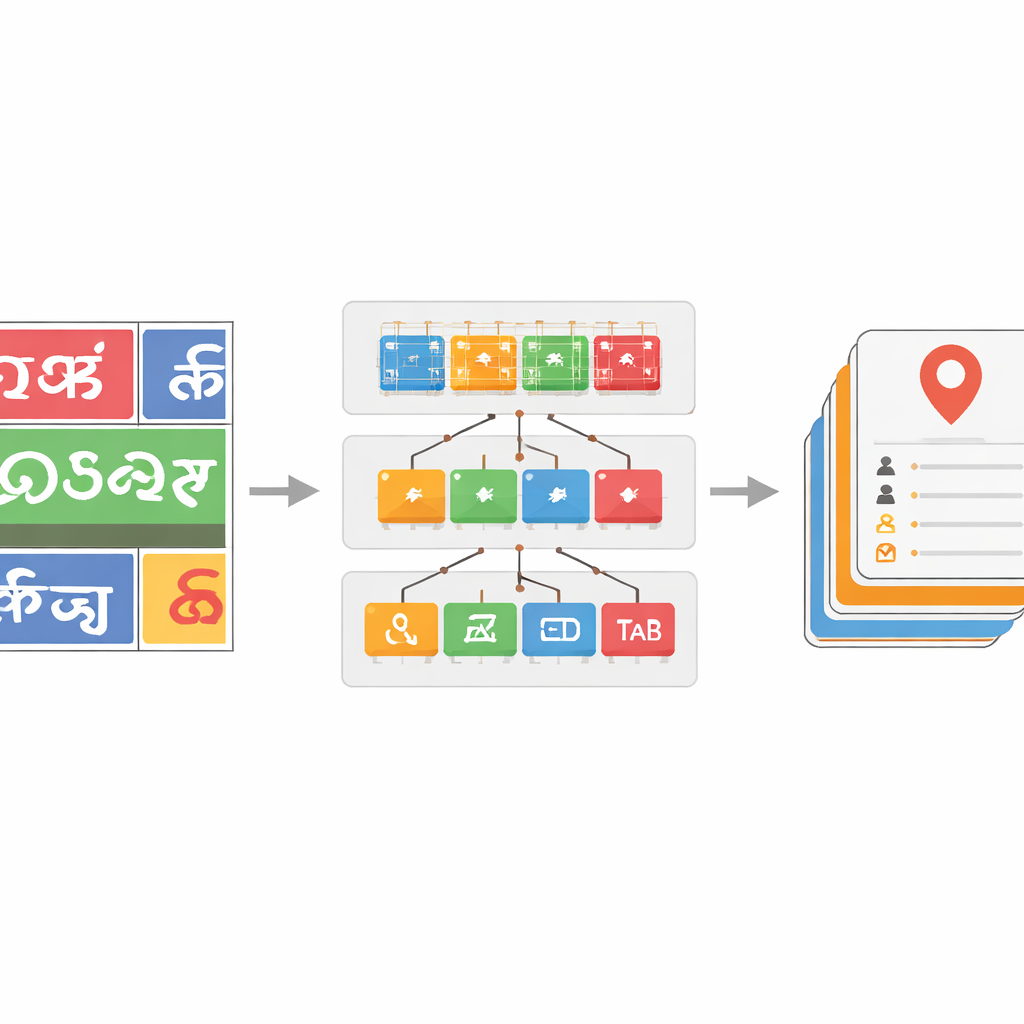
Nauka systemu radzenia sobie z wieloma pismami i zaszumionym tekstem
Aby uczynić klasyfikator pisma odpornym, zespół skompletował duży zestaw danych obrazów słów pochodzących z rzeczywistych zdjęć ulicznych, uzupełniony o publiczne zbiory danych i próbki syntetyczne. Zastosowali realistyczne zniekształcenia — takie jak rozmycie, szum i zmiany perspektywy — aby naśladować to, co kamery widzą w ruchu ulicznym. Głębsze modele ResNet okazały się szczególnie skuteczne, a najpotężniejsza wersja, ResNet-152, osiągnęła około 96 procent dokładności w rozróżnianiu pism, przewyższając wcześniejsze wyniki dla tekstu scenicznego w językach indyjskich. Dodatkowo wprowadzono krok korekcji oparty na słownikach dla rozpoznanych słów. Budując specyficzne dla języka listy słów z danych adnotowanych i porównując każde przewidziane słowo z pobliskimi wpisami ze słownika za pomocą miar odległości edycyjnej, zachłanny algorytm przeszukiwania potrafi często naprawić źle odczytane znaki. Przynosi to wzrost dokładności na poziomie słowa nawet do 17 punktów procentowych w niektórych pismach, znacznie oczyszczając zaszumione wyjścia.
Od surowych obrazów do użytecznych punktów zainteresowania
Wykrywanie dokładnej lokalizacji małych pól, takich jak numery telefonów czy identyfikatory podatkowe, na zatłoczonych tablicach pozostaje trudne, a średnia precyzja detektora obiektów wynosząca 33 procent odzwierciedla to wyzwanie. Jednak autorzy pokazują, że nawet niedoskonałe ramki ograniczające mogą być wystarczające do przekazania do kolejnych etapów rozpoznawania i korekcji, gdzie słowniki i modele świadome pisma pomagają ustalić, co rzeczywiście zawiera każdy region. Centralna warstwa programowa typu „most” koordynuje wszystkie te moduły, standaryzując formaty danych, odfiltrowując wyniki o niskim zaufaniu i stosując strategie awaryjne, gdy któraś część systemu zawodzi. W ocenach względem nowszych podejść cały potok przewyższa wcześniejsze systemy w rozpoznawaniu pisma, rozpoznawaniu słów i wykrywaniu pól punktów zainteresowania, szczególnie dla pism indyjskich o niskich zasobach, które często są niedostatecznie reprezentowane w globalnych zbiorach danych.
Co to oznacza dla codziennych użytkowników
Łącząc istniejące narzędzia głębokiego uczenia z danymi specyficznymi dla języka i inteligentną warstwą korekcyjną, autorzy zbudowali praktyczny system end-to-end, który potrafi na dużą skalę czytać i rozumieć wielojęzyczne indyjskie szyldy uliczne. Końcowe wyjście to ustrukturyzowany, maszynowo czytelny opis każdego punktu zainteresowania — wraz z nazwą, danymi kontaktowymi i innymi kluczowymi polami — który można bezpośrednio podłączyć do map cyfrowych, aplikacji nawigacyjnych i lokalnych wyszukiwarek. Dla codziennych użytkowników może to oznaczać dokładniejsze wskazówki, lepsze odnajdywanie pobliskich usług i narzędzia cyfrowe działające równie dobrze we wszystkich indyjskich pismach i językach. Praca pokazuje, że przy przemyślanym inżynierskim podejściu sztuczna inteligencja może pomagać w zachowaniu i wykorzystaniu różnorodności językowej, zamiast wymuszać wszystko na pojedynczym alfabecie.
Cytowanie: Kashyap, A.K., Upadhya, M., Panwar, V.S. et al. Integrated framework utilizing scene text detection and recognition techniques for enhancing point of interest extraction from name boards in all Indic languages. Sci Rep 16, 12907 (2026). https://doi.org/10.1038/s41598-026-40742-w
Słowa kluczowe: rozpoznawanie tekstu scenicznego, wielojęzyczne OCR, pisma indyjskie, ekstrakcja punktów zainteresowania, głębokie uczenie w wizji