Clear Sky Science · sv
Integrerat ramverk som använder scentextdetektion och igenkänning för att förbättra extraktion av intressespunkter från namnskyltar på alla indiska språk
Smartkartor för en flerspråkig nation
Att hitta rätt i en indisk stad innebär ofta att man skannar en soppa av butiksskyltar, reklamskyltar och gatubaserade skyltar skrivna i många olika skriftsystem. Människor klarar detta lätt, men digitala kartor och navigationsverktyg har fortfarande svårt att läsa dessa skyltar pålitligt. Denna artikel presenterar ett integrerat system som lär datorer att upptäcka och läsa text i verkliga bilder på nästan alla större indiska skriftsystem, och sedan omvandla den informationen till rena, sökbara intressespunkter — vilket banar väg för smartare navigation, bättre lokal sökning och mer inkluderande digitala tjänster.
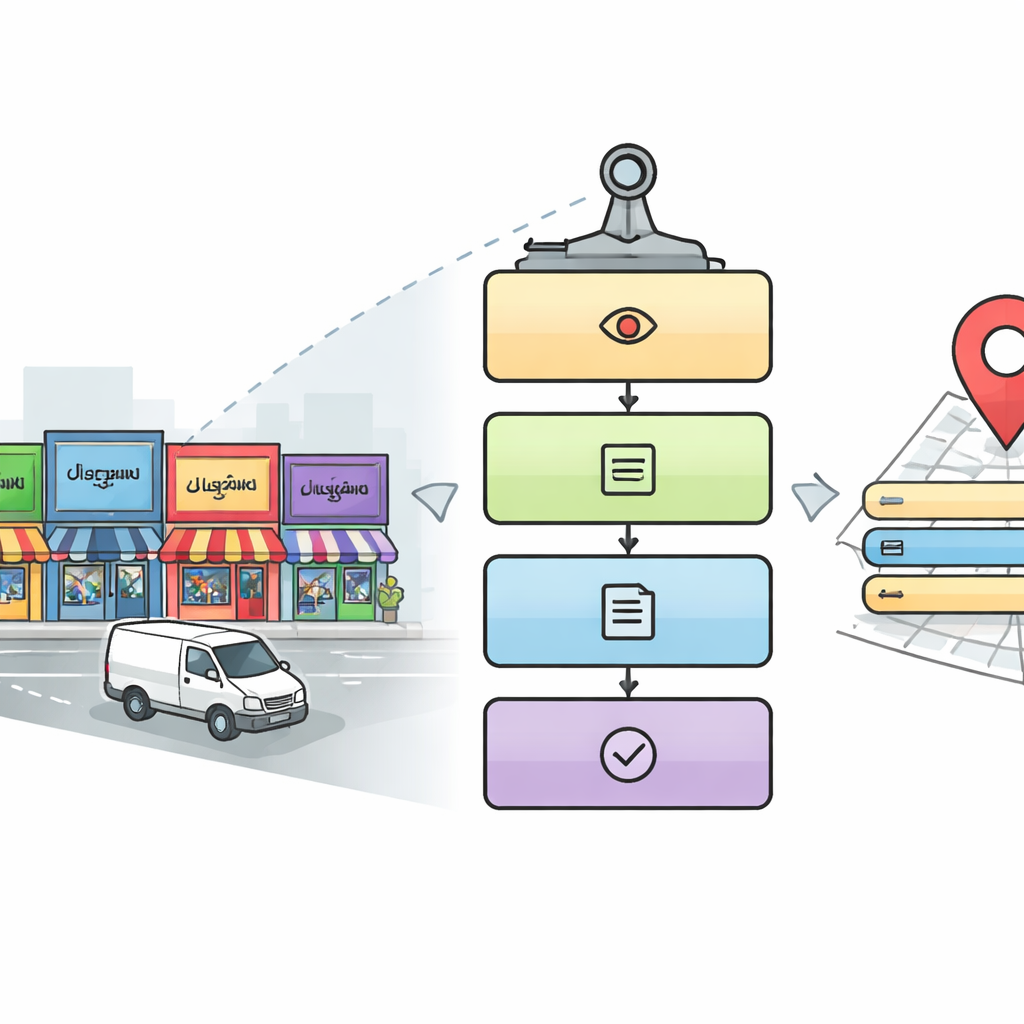
Varför det är så svårt för maskiner att läsa gatubilder
Till skillnad från prydliga tryckta sidor är gatubilder visuellt röriga. Text förekommer i konstiga vinklar, i olika storlekar och mot stökiga bakgrunder. I Indien försvåras detta ytterligare av användningen av många skriftsystem — såsom Devanagari, Tamil, Bengali och andra — som vid en snabb blick kan se lika ut men skiljer sig i avgörande detaljer. Traditionell optisk teckenigenkänning, byggd främst för latinska alfabet och rena dokument, brister när den ställs inför lågupplösta foton från rörliga fordon, överlappande skyltar och dekorativa typsnitt. Författarna fokuserar på bilder fångade av Mobile Mapping Systems — fordon utrustade med kameror som kartlägger gator — för att angripa dessa verkliga utmaningar direkt.
En femstegs digital läsare för stadsgator
Forskarna utformar en femstegs pipeline som efterliknar hur en noggrann människa skulle läsa en komplex gatubild. Först skannar en detektionsmodul varje bild för att hitta områden som sannolikt innehåller relevanta skyltar och namntavlor, med hjälp av en populär objektigenkänningsmetod kallad YOLOv5. Därefter beskär systemet textregionerna inuti dessa områden. I tredje steget identifierar en djupinlärningsmodell baserad på ResNet-nätverk vilket skriftsystem varje beskuret ord är skrivet i, med val mellan tio indiska skriftsystem plus engelska. När skriftsystemet är känt använder ett fjärde steg en matchande teckenigenkännare för att omvandla ordets bild till digital text. Slutligen söker ett femte, parallellt steg i bilden efter nyckeldetaljer — såsom platsnamn, adresselement, telefonnummer, postnummer, ikoner och skatteidentifikationsnummer — och sätter ihop dem till en komplett, lättläst adress och en strukturerad digital post.
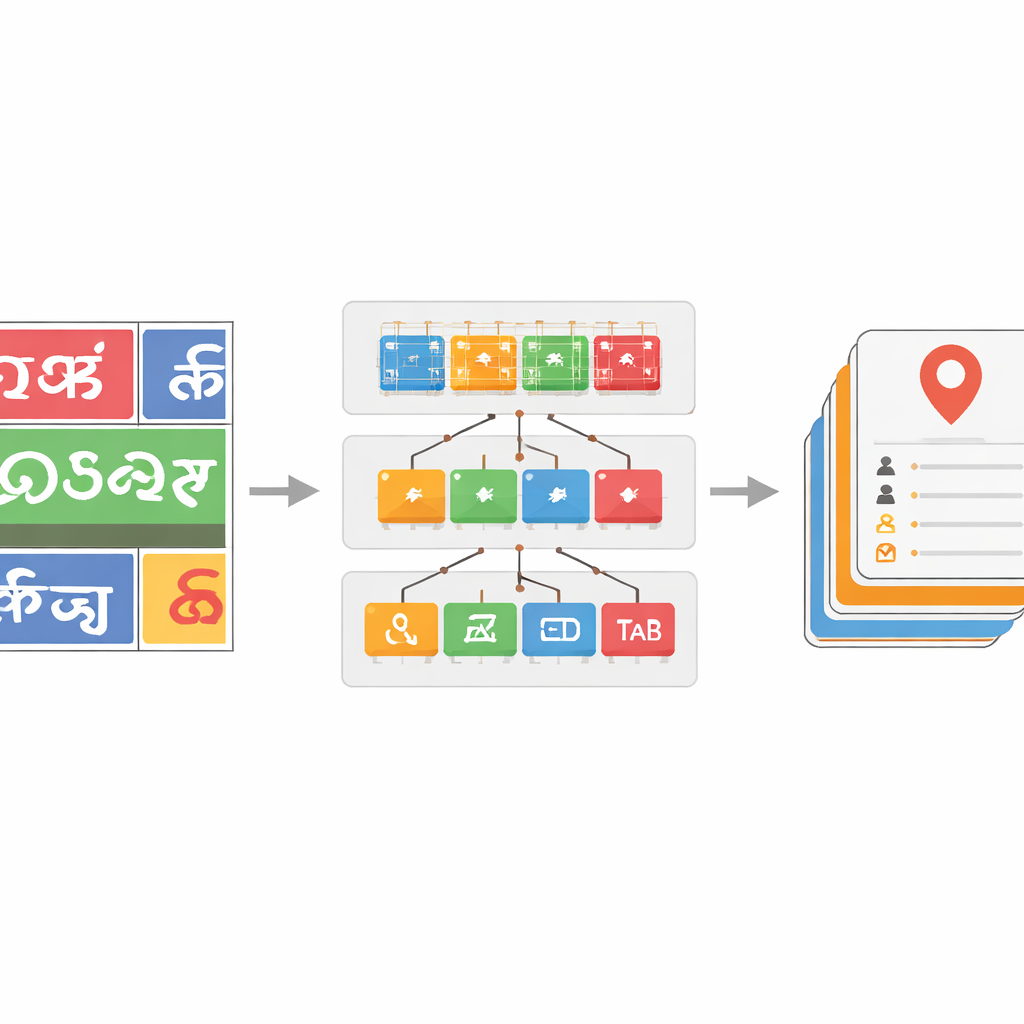
Träna systemet att hantera många skriftsystem och brusig text
För att göra skriftsklassificeraren robust kuraterar teamet ett stort dataset av ordbilder hämtade från verkliga gatufoton, kompletterat med offentliga dataset och syntetiska prover. De applicerar realistiska störningar — såsom oskärpa, brus och perspektivförändringar — för att efterlikna vad kameror ser i trafiken. Djupare ResNet-modeller visar sig särskilt effektiva, där den mest kraftfulla versionen, ResNet-152, uppnår cirka 96 procent noggrannhet i att skilja skriftsystem åt, bättre än tidigare riktmärken för indisk scentext. Utöver detta introducerar de ett ordboksbaserat korrigeringsteg för de igenkända orden. Genom att bygga språksspecifika ordlistor från annoterade data och jämföra varje förutsagt ord med närliggande ord i ordlistan med hjälp av edit-avstånd, kan en girig sökalgoritm ofta åtgärda felaktigt lästa tecken. Detta ger förbättringar i ordnivånoggrannhet på upp till 17 procentenheter i vissa skriftsystem och städar avsevärt upp brusiga utdata.
Från råa bilder till användbara intressespunkter
Att upptäcka den exakta placeringen av små fält som telefonnummer eller skatte-ID på trånga skyltar förblir svårt, och objektdetektorns genomsnittliga precision på 33 procent speglar denna utmaning. Författarna visar dock att även ofullkomliga begränsande rutor kan vara tillräckligt bra för att matas in i senare text- och korrigeringsteg, där ordlistan och skriftsmedvetna modeller hjälper till att reda ut vad varje region faktiskt innehåller. Ett centralt mjukvarulager fungerar som en ”bro” som koordinerar alla dessa moduler, standardiserar dataformat, filtrerar bort output med låg tilltro och tillämpar fallback-strategier när en del av systemet sviktar. När systemet utvärderas mot nyare metoder presterar hela pipelinen bättre än tidigare system för skriftsigenkänning, ordigenkänning och fältdetektion för intressespunkter, särskilt för resurssvaga indiska skriftsystem som ofta är underrepresenterade i globala dataset.
Vad detta betyder för dagliga användare
Genom att omsorgsfullt kombinera befintliga djuplärande verktyg med språksspecifika data och ett smart korrigeringslager bygger författarna ett praktiskt, ända-till-ända-system som kan läsa och förstå flerspråkiga indiska gatustycken i stor skala. Slutresultatet är en strukturerad, maskinläsbar beskrivning av varje intressespunkt — komplett med namn, kontaktuppgifter och andra nyckelfält — som kan anslutas direkt till digitala kartor, navigationsappar och lokala sökmotorer. För vardagsanvändare kan detta innebära mer precisa vägbeskrivningar, bättre upptäckt av närliggande tjänster och digitala verktyg som fungerar lika väl över Indiens många skriftsystem och språk. Arbetet visar att med genomtänkt ingenjörskonst kan artificiell intelligens bidra till att bevara och utnyttja språklig mångfald snarare än att tvinga allt in i ett enda skriftsystem.
Citering: Kashyap, A.K., Upadhya, M., Panwar, V.S. et al. Integrated framework utilizing scene text detection and recognition techniques for enhancing point of interest extraction from name boards in all Indic languages. Sci Rep 16, 12907 (2026). https://doi.org/10.1038/s41598-026-40742-w
Nyckelord: scentextigenkänning, multilingual OCR, indiska skriftsystem, extraktion av intressespunkter, djuplärande för syn