Clear Sky Science · ar
إطار متكامل يستخدم تقنيات كشف النص في المشاهد والتعرّف عليه لتعزيز استخراج نقاط الاهتمام من لوحات الأسماء بجميع اللغات الإندية
خرائط ذكية لأمة متعددة اللغات
العثور على طريقك في مدينة هندية غالبًا ما يتطلب مسحًا لدوامة من لافتات المحلات والإعلانات ولوحات الشوارع المكتوبة بعدة خطوط مختلفة. البشر يفعلون ذلك بسهولة، لكن خرائط وخدمات الملاحة الرقمية ما تزال تكافح لقراءة هذه اللافتات بشكل موثوق. تعرض هذه الورقة نظامًا متكاملًا يعلّم الحواسيب اكتشاف وقراءة النصوص في صور من العالم الحقيقي في معظم الخطوط الهندية الرئيسية، ثم تحويل تلك المعلومات إلى نقاط اهتمام نظيفة وقابلة للبحث — ممهِّدًا الطريق لملاحة أذكى، وبحث محلي أفضل، وخدمات رقمية أكثر شمولاً.
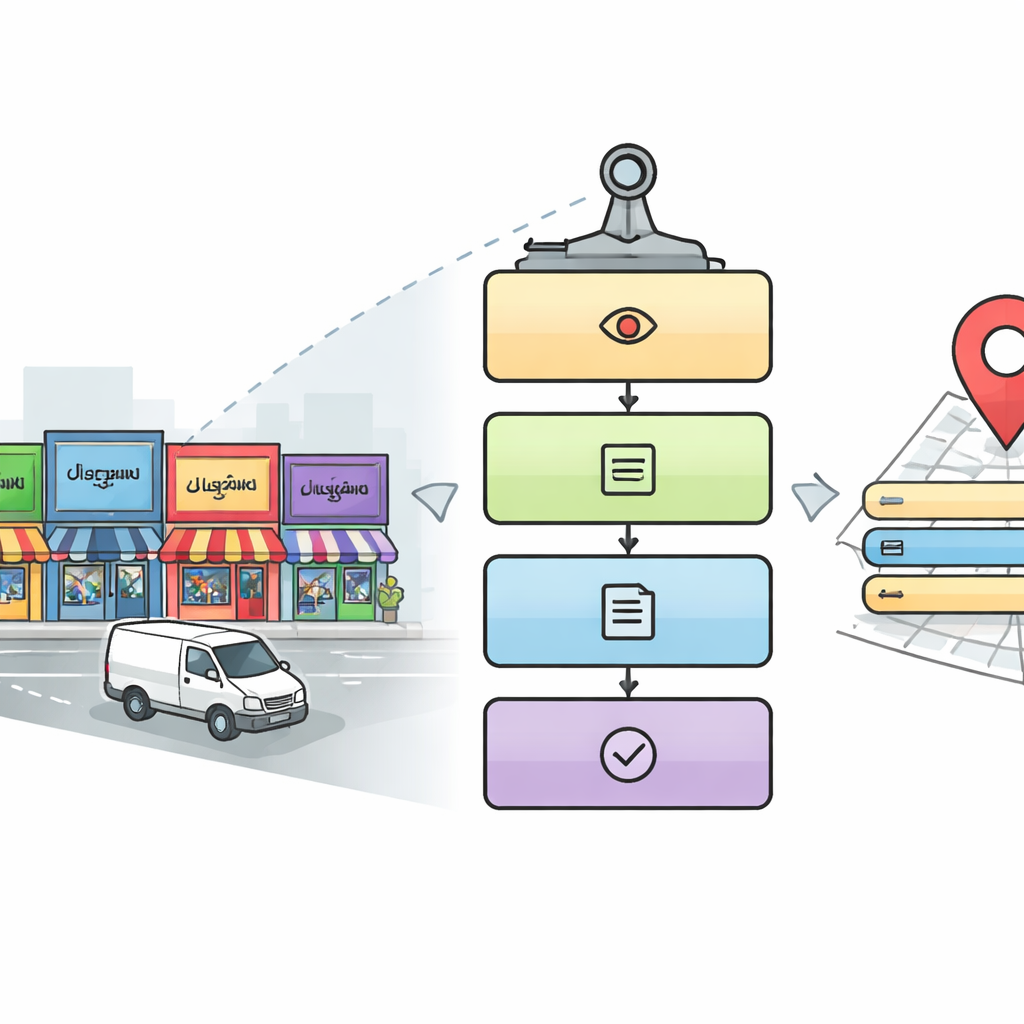
لماذا قراءة لافتات الشوارع صعبة على الآلات
على خلاف الصفحات المطبوعة المرتبة، مشاهد الشوارع فوضوية بصريًا. يظهر النص بزوايا غريبة، بأحجام متفاوتة، وعلى خلفيات مزدحمة. وفي الهند يزداد التعقيد باستخدام العديد من الخطوط—مثل الديفاناغاري والتاميلية والبنغالية وغيرها—والتي قد تبدو متشابهة من لمحة سريعة لكن تختلف في تفاصيل حاسمة. التعرف الضوئي التقليدي للحروف، المصمم أساسًا للأبجديات اللاتينية والوثائق النظيفة، يفشل أمام صور منخفضة الدقة مأخوذة من مركبات متحركة، ولافتات متداخلة، وخطوط زخرفية. يركز المؤلفون على الصور الملتقطة بواسطة أنظمة التصوير المتنقلة (Mobile Mapping Systems)—مركبات مزوَّدة بكاميرات تجوب شوارع المدينة—لمواجهة هذه التحديات الواقعية مباشرة.
قارئ رقمي من خمس مراحل لشوارع المدينة
صمّم الباحثون خط أنابيب مكوّن من خمس مراحل يحاكي كيف قد يقرأ إنسان دقيق مشهد شارع معقد. أولًا، يقوم مُكوّن الكشف بمسح كل صورة لإيجاد المناطق التي يحتمل احتواؤها على لافتات ولوحات أسماء ذات صلة، باستخدام نهج شائع للكشف عن الأشياء يسمى YOLOv5. بعد ذلك، يقوم النظام بقص مناطق النص داخل تلك الأطر. في المرحلة الثالثة، يحدد نموذج تعلم عميق مبني على شبكات ResNet أي خط كُتبَت به كل كلمة مقطوعة، مخيِّرًا بين عشرة خطوط إندية بالإضافة إلى الإنجليزية. بعد معرفة الخط، تستخدم المرحلة الرابعة مُعرِّف أحرف مطابقة لتحويل صورة الكلمة إلى نص رقمي. أخيرًا، في المرحلة الخامسة الموازية، يبحث النظام في الصورة عن عناصر مفصلية—مثل اسم المكان، عناصر العنوان، رقم الهاتف، الرمز البريدي، الأيقونات، ورقم التعريف الضريبي—ويجمعها في عنوان كامل مقروء للبشر وسجل رقمي منظم.
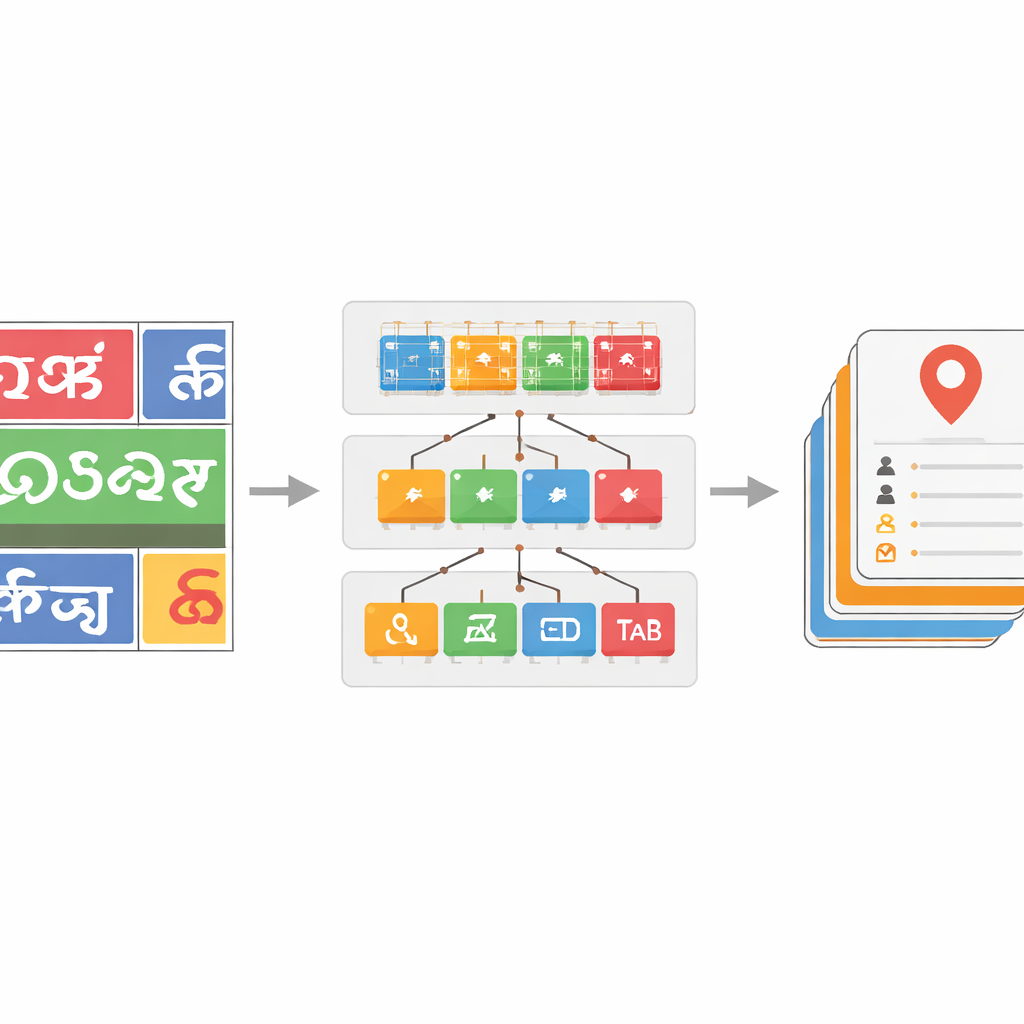
تعليم النظام التعامل مع العديد من الخطوط والنصوص المشوشة
لجعل مُصنِّف الخطوط متينًا، يجمع الفريق مجموعة بيانات كبيرة من صور الكلمات المأخوذة من صور الشوارع الحقيقية، مكمّلة بمجموعات بيانات عامة وعينات اصطناعية. يطبقون تشويهات واقعية—مثل الضبابية، والضوضاء، وتغيُّرات المنظور—لتقليد ما تلتقطه الكاميرات في حركة المرور. أثبتت نماذج ResNet الأعمق فعاليتها بشكل خاص، حيث حقق الإصدار الأقوى، ResNet-152، دقة تقارب 96 بالمئة في تمييز الخطوط، متفوقًا على المعايير السابقة لنص المشاهد بالخطوط الإندية. بالإضافة إلى ذلك، يقدمون خطوة تصحيح تعتمد على القواميس للكلمات المعترف بها. ببناء قوائم كلمات خاصة بكل لغة من البيانات المشروحة ومقارنة كل كلمة متوقعة بمدخلات القاموس القريبة باستخدام مقاييس مسافة التحرير، يمكن لخوارزمية بحث جشعة تصحيح الحروف المقروءة خطأ في كثير من الأحيان. هذا يُفضي إلى مكاسب في دقة مستوى الكلمات تصل إلى 17 نقطة مئوية في بعض الخطوط، مما ينظف النتائج المشوشة بشكل ملموس.
من الصور الخام إلى نقاط اهتمام قابلة للاستخدام
ما يزال اكتشاف الموقع الدقيق لحقول صغيرة مثل أرقام الهواتف أو أرقام الضرائب على اللوحات المزدحمة صعبًا، وتعكس متوسط دقة كاشف الأشياء البالغ 33 بالمئة هذا التحدي. مع ذلك، يبيّن المؤلفون أن المربعات المحيطة غير المثالية قد تكون كافية لإدخالها في خطوات التعرف اللاحقة وخطوات التصحيح، حيث تساعد القواميس والنماذج المتحسّسة للخط في تبيان ما يحتويه كل نطاق بالفعل. تقوم طبقة برمجية "جسر" مركزية بتنسيق كل هذه الوحدات، وتوحيد صيغ البيانات، وتصفيّة المخرجات منخفضة الثقة، وتطبيق استراتيجيات احتياطية عندما يتعثر جزء من النظام. عند التقييم مقارنة بالنهج الحديثة، يتفوّق خط الأنابيب الكامل على الأنظمة السابقة في التعرف على الخطوط، والتعرّف على الكلمات، واكتشاف حقول نقاط الاهتمام، لا سيما بالنسبة للخطوط الإندية قليلة الموارد التي غالبًا ما تكون ممثلة تمثيلًا ناقصًا في مجموعات البيانات العالمية.
ما يعنيه هذا للمستخدمين اليوميين
بدمج أدوات التعلم العميق الحالية بعناية مع بيانات خاصة بكل لغة وطبقة تصحيح ذكية، يبني المؤلفون نظامًا عمليًا شاملًا قادرًا على قراءة وفهم لافتات الشوارع الهندية متعددة اللغات على نطاق واسع. الناتج النهائي هو وصف منظم قابل للقراءة آليًا لكل نقطة اهتمام—مكتملًا بالاسم وبيانات الاتصال وغيرها من الحقول الرئيسية—يمكن توصيله مباشرة بخرائط رقمية وتطبيقات ملاحة ومحركات بحث محلية. بالنسبة للمستخدمين اليوميين، قد يعني هذا توجيهات أكثر دقة، واكتشافًا محسّنًا للخدمات القريبة، وأدوات رقمية تعمل على نحو متساوٍ عبر الخطوط واللغات المتعددة في الهند. تُظهر هذه الدراسة أنه مع هندسة مدروسة، يمكن للذكاء الاصطناعي أن يساعد في الحفاظ على التنوع اللغوي والاستفادة منه بدلًا من إجبار كل شيء على خط واحد.
الاستشهاد: Kashyap, A.K., Upadhya, M., Panwar, V.S. et al. Integrated framework utilizing scene text detection and recognition techniques for enhancing point of interest extraction from name boards in all Indic languages. Sci Rep 16, 12907 (2026). https://doi.org/10.1038/s41598-026-40742-w
الكلمات المفتاحية: التعرّف على نصوص المشاهد, التعرّف الضوئي المتعدد اللغات, الخطوط الإندية, استخراج نقاط الاهتمام, الرؤية العميقة