Clear Sky Science · ru
Интегрированная система с использованием методов обнаружения и распознавания текста на изображениях для улучшения извлечения точек интереса с вывесок во всех индийских языках
Умные карты для многоязычной нации
Ориентироваться в индийском городе часто значит просматривать поток вывесок магазинов, билбордов и уличных табличек, написанных на множестве разных письменностей. Людям это дается легко, но цифровые карты и навигационные инструменты по-прежнему испытывают трудности с надежным чтением таких знаков. В статье представлена интегрированная система, которая учит компьютеры находить и читать текст на реальных изображениях практически во всех основных индийских письменностях, а затем превращать эту информацию в аккуратные, по-настоящему ищемые точки интереса — прокладывая путь к более умной навигации, лучшему локальному поиску и более инклюзивным цифровым сервисам.
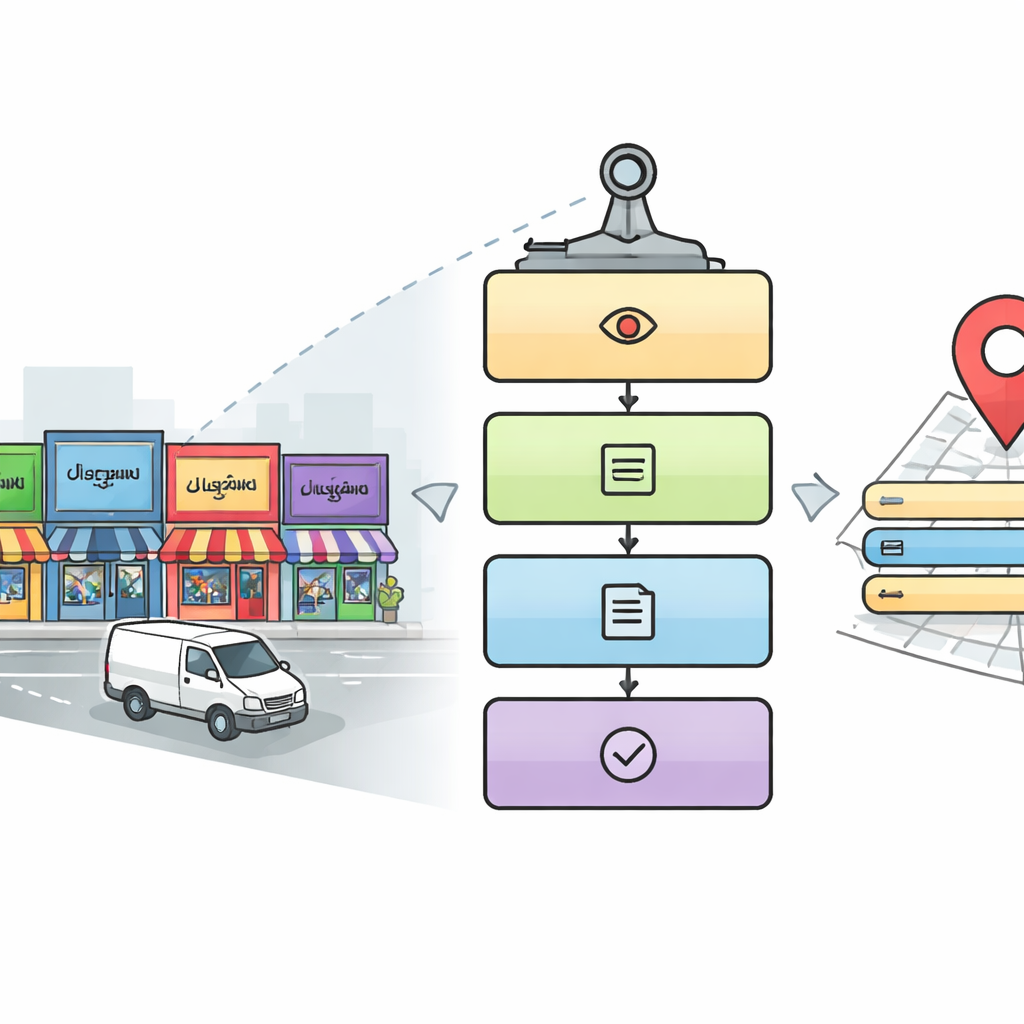
Почему чтение уличных вывесок для машин так сложно
В отличие от аккуратных напечатанных страниц, уличные сцены визуально беспорядочны. Текст встречается под странными углами, разного размера и на загроможденных фонах. В Индии это усложняется использованием множества письменностей — таких как деванагари, тамильская, бенгальская и других — которые на первый взгляд могут выглядеть похоже, но различаются по важным деталям. Традиционные системы оптического распознавания, созданные в основном для латинских алфавитов и чистых документов, дают сбои при обработке низкокачественных фотографий с движущихся транспортных средств, перекрывающихся вывесок и декоративных шрифтов. Авторы сосредотачиваются на изображениях, полученных с мобильных картографических систем — автомобилей с камерами, обследующими городские улицы — чтобы напрямую решать эти реальные задачи.
Пятиэтапный цифровой «чтец» для городских улиц
Исследователи разработали конвейер из пяти этапов, имитирующий то, как внимательный человек может читать сложную уличную панораму. Сначала модуль обнаружения сканирует каждое изображение в поисках областей, в которых вероятно находятся релевантные вывески и таблички, используя популярный подход к обнаружению объектов под названием YOLOv5. Затем система вырезает текстовые регионы внутри найденных областей. На третьем этапе глубокая модель на базе сетей ResNet определяет, какой письменностью написано каждое обрезанное слово, выбирая между десятью индийскими письменностями и английским. После выявления письменности на четвертом этапе применяется соответствующий распознаватель символов, который превращает изображение слова в цифровой текст. Наконец, на пятом, параллельном этапе система ищет в изображении ключевые детали — такие как название места, элементы адреса, номер телефона, почтовый индекс, иконки и налоговый идентификатор — и собирает их в полноценный, удобочитаемый адрес и структурированную цифровую запись.
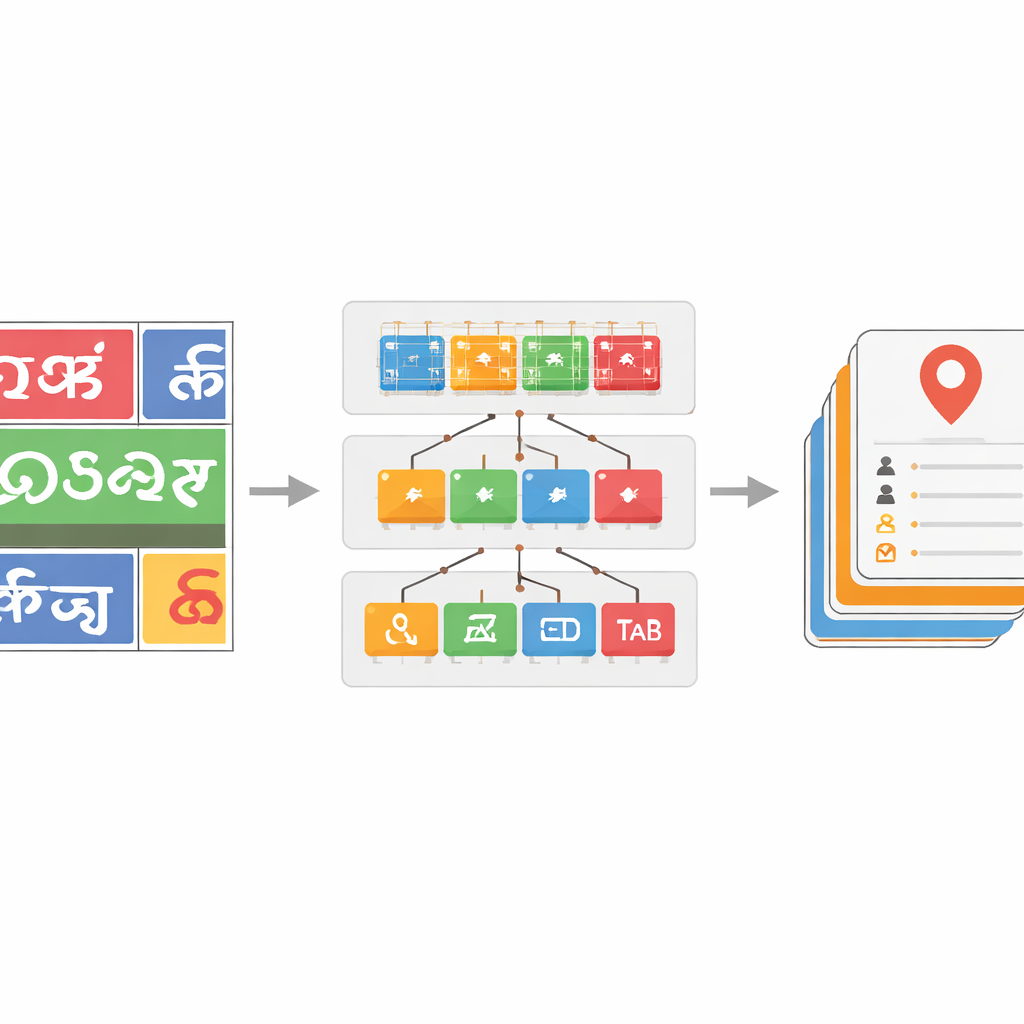
Обучение системы работать со множеством письменностей и шумным текстом
Чтобы сделать классификатор письменностей устойчивым, команда сформировала большой набор данных изображений слов, взятых из реальных уличных снимков, дополненный общедоступными датасетами и синтетическими образцами. Они применяли реалистичные искажения — такие как размытие, шум и искажения перспективы — чтобы имитировать то, что камеры видят в движении. Более глубокие модели ResNet оказались особенно эффективны: самая мощная версия, ResNet-152, показала около 96 процентов точности в различении письменностей, что лучше прежних эталонов для сценического текста на индийских языках. Кроме того, они внедрили шаг исправления на основе словарей для распознанных слов. Строя языко-специфические списки слов из аннотированных данных и сравнивая каждое предсказанное слово с ближайшими словарными совпадениями по расстоянию Левенштейна, жадный алгоритм поиска часто исправляет неверно распознанные символы. Это дает улучшение точности на уровне слов до 17 процентных пунктов в некоторых письменностях, существенно очищая шумные результаты.
От сырых изображений к пригодным точкам интереса
Определение точного расположения мелких полей, таких как телефонные номера или налоговые коды, на перегруженных табличках по-прежнему затруднено, и средняя точность детектора объектов в 33 процента отражает эту проблему. Тем не менее авторы показывают, что даже несовершенные ограничивающие рамки могут быть достаточными для последующих шагов по распознаванию и исправлению, где словарь и модели, учитывающие письменность, помогают понять, что на самом деле содержит каждая область. Центральный программный «мостовой» слой координирует все эти модули, стандартизируя форматы данных, отбрасывая результаты с низкой уверенностью и применяя стратегии резервирования, когда какая-либо часть системы дает сбой. При оценке по сравнению с современными подходами полный конвейер превосходит предыдущие системы по распознаванию письменности, распознаванию слов и обнаружению полей точек интереса, особенно для малообеспеченных ресурсов индийских письменностей, которые часто недопредставлены в глобальных датасетах.
Что это значит для повседневных пользователей
Бережно сочетая существующие инструменты глубокого обучения с языко-специфичными данными и интеллектуальным слоем исправления, авторы создали практичную сквозную систему, способную в масштабе читать и понимать многоязычные индийские уличные вывески. Итоговый результат — структурированное, машинно-читаемое описание каждой точки интереса — с названием, контактными данными и другими ключевыми полями, которое можно напрямую интегрировать в цифровые карты, навигационные приложения и локальные поисковые системы. Для обычных пользователей это может означать более точные маршруты, лучшее обнаружение близлежащих сервисов и цифровые инструменты, которые одинаково хорошо работают во множестве индийских письменностей и языков. Работа показывает, что при продуманной инженерии искусственный интеллект может не упрощать лингвистическое разнообразие до одной письменности, а помогать сохранять и использовать его.
Цитирование: Kashyap, A.K., Upadhya, M., Panwar, V.S. et al. Integrated framework utilizing scene text detection and recognition techniques for enhancing point of interest extraction from name boards in all Indic languages. Sci Rep 16, 12907 (2026). https://doi.org/10.1038/s41598-026-40742-w
Ключевые слова: распознавание текста на изображениях, многоязычный OCR, индикские письменности, извлечение точек интереса, глубокое обучение в компьютерном зрении