Clear Sky Science · fr
Cadre intégré utilisant des techniques de détection et de reconnaissance de texte en scène pour améliorer l’extraction de points d’intérêt à partir d’enseignes dans toutes les langues indiennes
Cartes intelligentes pour une nation multilingue
Se repérer dans une ville indienne implique souvent de décrypter un paysage d’enseignes, de panneaux publicitaires et de plaques de rue rédigés dans de nombreux scripts. Les humains le font aisément, mais les cartes numériques et les outils de navigation peinent encore à lire ces panneaux de façon fiable. Cet article présente un système intégré qui apprend aux ordinateurs à repérer et lire le texte d’images réelles dans presque tous les scripts indiens majeurs, puis à convertir ces informations en points d’intérêt propres et consultables — ouvrant la voie à une navigation plus intelligente, une recherche locale améliorée et des services numériques plus inclusifs.
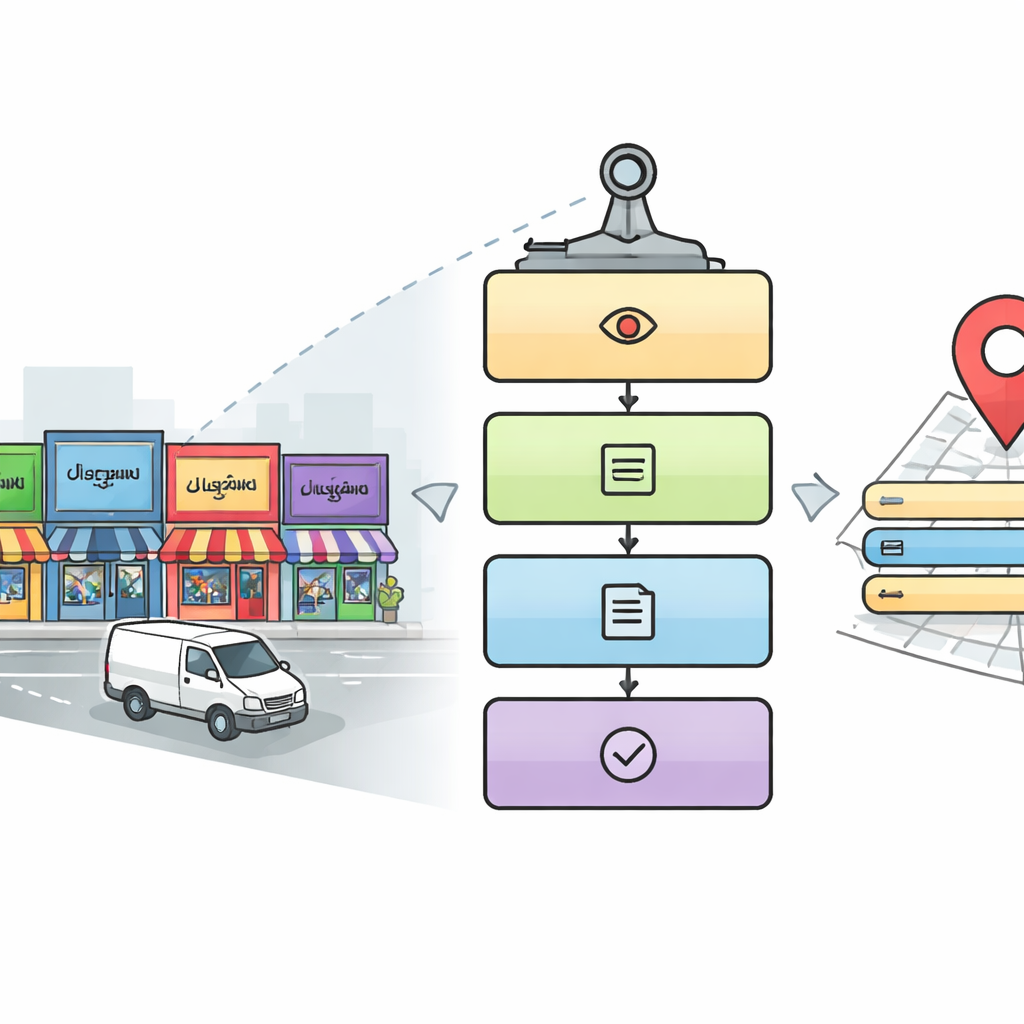
Pourquoi la lecture des panneaux de rue est si difficile pour les machines
Contrairement à des pages imprimées bien ordonnées, les scènes de rue sont visuellement désordonnées. Le texte apparaît à des angles étranges, dans des tailles variées et sur des arrière-plans encombrés. En Inde, la situation se complique encore par l’utilisation de nombreux scripts — tels que le devanagari, le tamoul, le bengali et d’autres — qui peuvent sembler similaires au premier regard mais diffèrent sur des détails cruciaux. La reconnaissance optique de caractères traditionnelle, conçue principalement pour les alphabets latins et des documents propres, montre ses limites face à des photos basse résolution prises depuis des véhicules en mouvement, des panneaux qui se chevauchent ou des polices décoratives. Les auteurs se concentrent sur des images capturées par des systèmes de cartographie mobile — des véhicules équipés de caméras qui sondent les rues urbaines — pour relever ces défis du monde réel.
Un lecteur numérique en cinq étapes pour les rues de la ville
Les chercheurs conçoivent une chaîne de traitement en cinq étapes qui imite la manière dont un observateur humain attentif lirait un paysage urbain complexe. D’abord, un module de détection analyse chaque image pour trouver les zones susceptibles de contenir des panneaux et des enseignes, en utilisant une approche d’object detection populaire appelée YOLOv5. Ensuite, le système recadre les régions de texte à l’intérieur de ces zones. À la troisième étape, un modèle d’apprentissage profond basé sur des réseaux ResNet identifie dans quel script chaque mot recadré est écrit, choisissant parmi dix scripts indiens plus l’anglais. Une fois le script connu, une quatrième étape utilise un reconnaisseur de caractères adapté pour convertir l’image du mot en texte numérique. Enfin, une cinquième étape, en parallèle, recherche dans l’image des informations clés — telles que le nom du lieu, les éléments d’adresse, le numéro de téléphone, le code postal, les icônes et le numéro d’identification fiscale — et les assemble en une adresse lisible par l’homme et en un enregistrement numérique structuré.
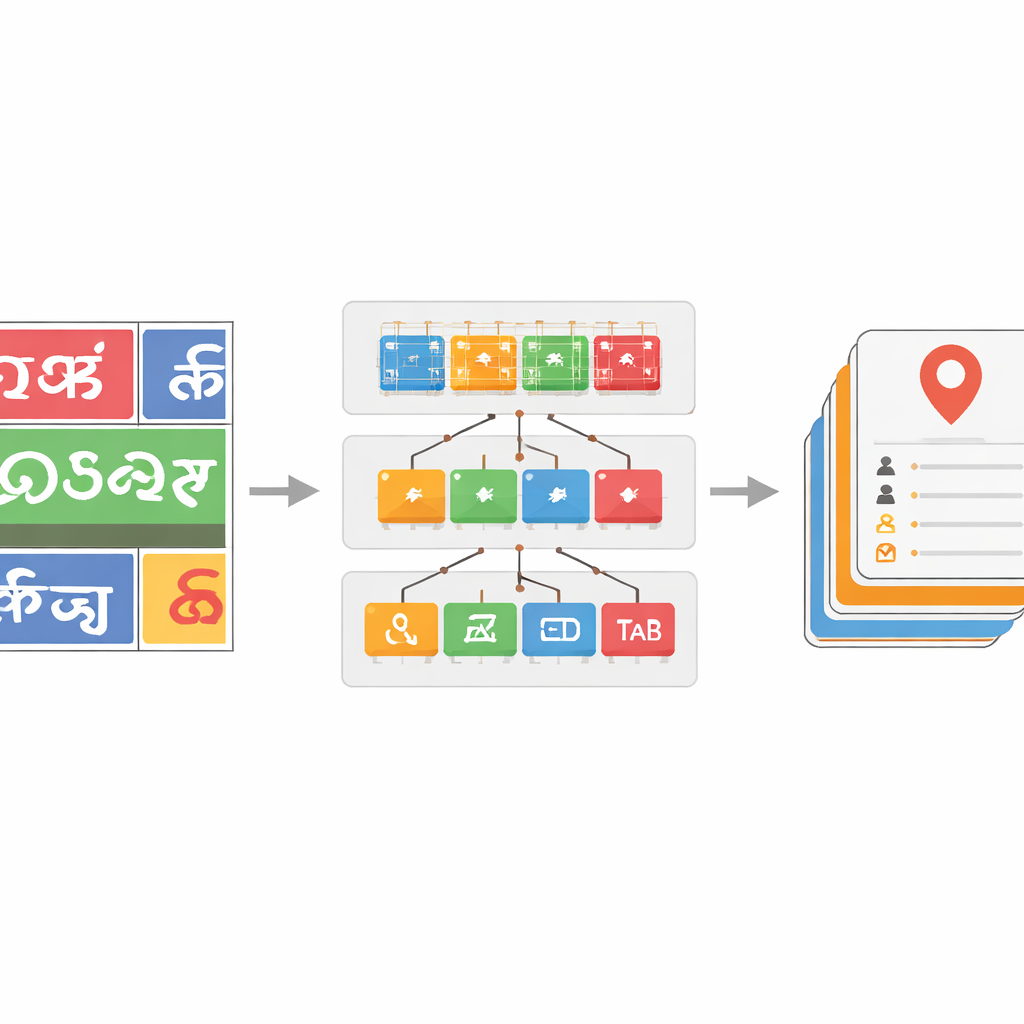
Apprendre au système à gérer de nombreux scripts et du texte bruité
Pour rendre le classifieur de script robuste, l’équipe constitue un large jeu de données d’images de mots tirées d’images de rue réelles, complété par des jeux de données publics et des échantillons synthétiques. Ils appliquent des distorsions réalistes — telles que flou, bruit et changements de perspective — pour simuler ce que voient les caméras en circulation. Des modèles ResNet plus profonds se révèlent particulièrement efficaces, la version la plus puissante, ResNet-152, atteignant environ 96 % de précision pour différencier les scripts, surpassant les repères précédents pour le texte en scène en scripts indiens. Par-dessus cela, ils introduisent une étape de correction basée sur un dictionnaire pour les mots reconnus. En construisant des listes de mots spécifiques à chaque langue à partir de données annotées et en comparant chaque mot prédit aux entrées du dictionnaire proches à l’aide de mesures de distance d’édition, un algorithme de recherche gloutonne peut souvent corriger des caractères mal lus. Cela permet des gains d’exactitude au niveau du mot pouvant atteindre 17 points de pourcentage pour certains scripts, nettoyant sensiblement les sorties bruitées.
Des images brutes à des points d’intérêt exploitables
Détecter l’emplacement exact de petits champs comme les numéros de téléphone ou les identifiants fiscaux sur des panneaux surchargés reste difficile, et la précision moyenne de 33 % de l’objet détecteur reflète ce défi. Cependant, les auteurs montrent que des boîtes englobantes imparfaites peuvent suffire à alimenter les étapes ultérieures de reconnaissance et de correction, où le dictionnaire et les modèles sensibles au script aident à déterminer ce que contient réellement chaque région. Une couche logicielle centrale en « passerelle » coordonne tous ces modules, standardisant les formats de données, filtrant les sorties à faible confiance et appliquant des stratégies de repli lorsqu’une partie du système faiblit. Évaluée face à des approches récentes, la chaîne complète surpasse les systèmes antérieurs en reconnaissance de script, en reconnaissance de mots et en détection des champs de points d’intérêt, en particulier pour les scripts indiens à faibles ressources souvent sous-représentés dans les jeux de données mondiaux.
Ce que cela signifie pour les utilisateurs au quotidien
En combinant soigneusement des outils d’apprentissage profond existants avec des données spécifiques aux langues et une couche de correction intelligente, les auteurs construisent un système pratique de bout en bout capable de lire et comprendre à grande échelle les enseignes multilingues indiennes. Le résultat final est une description structurée et lisible par machine de chaque point d’intérêt — complète avec nom, coordonnées et autres champs clés — pouvant s’intégrer directement aux cartes numériques, aux applications de navigation et aux moteurs de recherche locaux. Pour les utilisateurs quotidiens, cela peut se traduire par des itinéraires plus précis, une meilleure découverte des services à proximité et des outils numériques fonctionnant de manière équivalente à travers les nombreux scripts et langues de l’Inde. Ce travail montre qu’avec une ingénierie réfléchie, l’intelligence artificielle peut aider à préserver et exploiter la diversité linguistique plutôt que de tout forcer dans un seul script.
Citation: Kashyap, A.K., Upadhya, M., Panwar, V.S. et al. Integrated framework utilizing scene text detection and recognition techniques for enhancing point of interest extraction from name boards in all Indic languages. Sci Rep 16, 12907 (2026). https://doi.org/10.1038/s41598-026-40742-w
Mots-clés: reconnaissance de texte en scène, OCR multilingue, scripts indiens, extraction de points d’intérêt, vision par apprentissage profond