Clear Sky Science · ja
全てのインディック言語の名板からの関心地点抽出を強化するためのシーンテキスト検出・認識技術を利用した統合フレームワーク
多言語国家のためのスマートマップ
インドの都市で道を探すことは、多様な文字で書かれた店の看板や広告、街路標識のぼやけた群れを見分けることを意味します。人間には容易でも、デジタル地図やナビゲーションツールはこれらの標識を確実に読み取るのにまだ苦労します。本論文は、コンピュータに実世界の画像からほぼすべての主要なインディック文字を見つけ読ませ、その情報を検索可能なきれいな関心地点(POI)に変換する統合システムを提示します。これにより、より賢明なナビゲーション、改善されたローカル検索、包摂的なデジタルサービスへの道が開かれます。
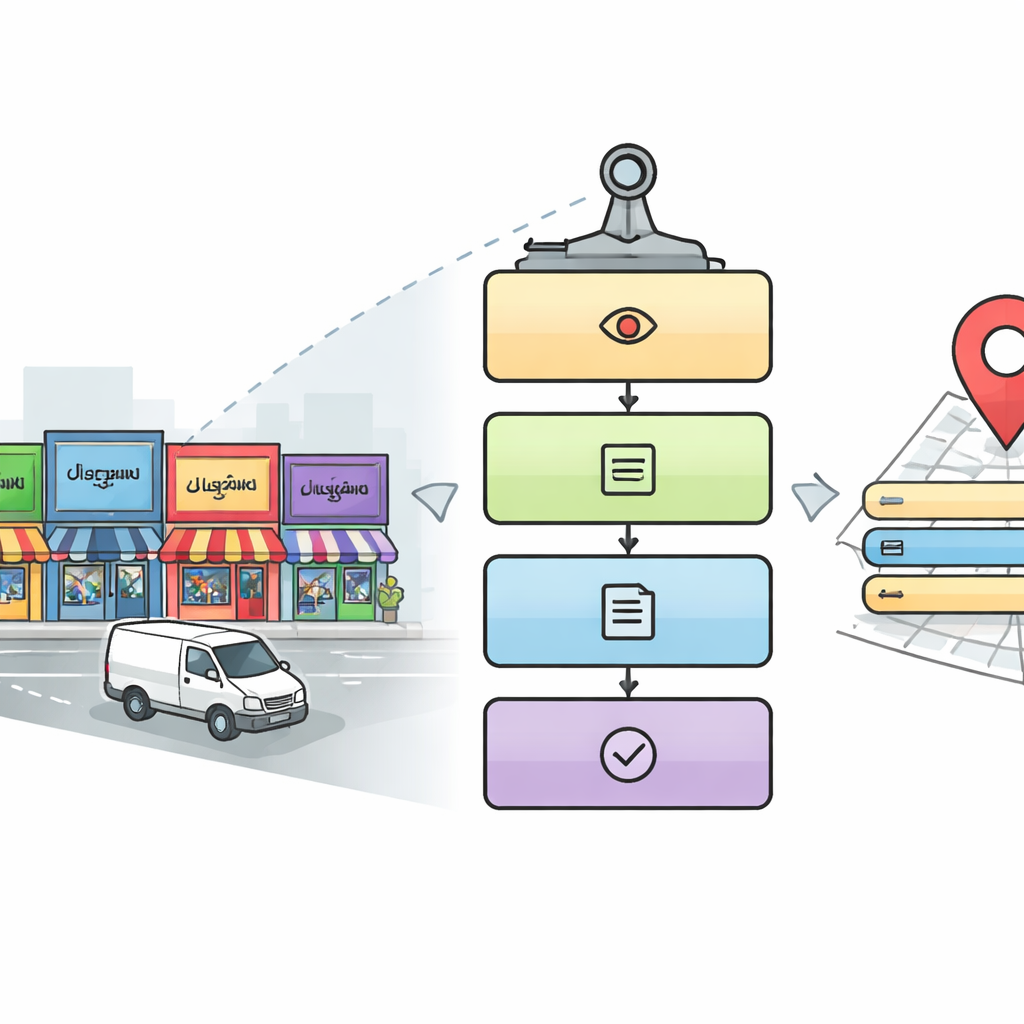
なぜ街の標識を機械が読むのは難しいのか
整った印刷ページと異なり、街の風景は視覚的に乱雑です。文字は不規則な角度で現れ、サイズも様々、背景もごちゃごちゃしています。インドではデーヴァナーガリー、タミル、ベンガルなど多数の文字体系が使われ、ぱっと見は似ていても重要な点で異なります。主にラテン文字ときれいな文書向けに構築された従来の光学文字認識は、走行中の車両が撮った低解像度写真、重なった看板、装飾的な書体に直面すると脆弱です。著者らはモバイルマッピングシステム(街路を撮影するカメラ搭載車両)で撮影された画像に着目し、これらの現実世界の課題に正面から取り組みます。
街路のための五段階デジタルリーダー
研究者らは、注意深い人間が複雑な街景を読むのに似た五段階のパイプラインを設計しています。まず検出モジュールが各画像を走査し、関連する看板や名板を含む可能性のある領域を、YOLOv5という代表的な物体検出手法で見つけます。次に、そこからテキスト領域を切り出します。三段階目では、ResNetベースの深層学習モデルが切り出された単語ごとにどの文字体系か(英語を含む10のインディック文字体系のいずれか)を識別します。文字体系が判明すると、四段階目で対応する文字認識器を用いて単語画像をデジタルテキストに変換します。最後に五段階目の並列プロセスが画像から地名、住所要素、電話番号、郵便番号、アイコン、税識別番号などの重要情報を検索し、それらを完全な人間可読の住所と構造化されたデジタル記録に組み立てます。
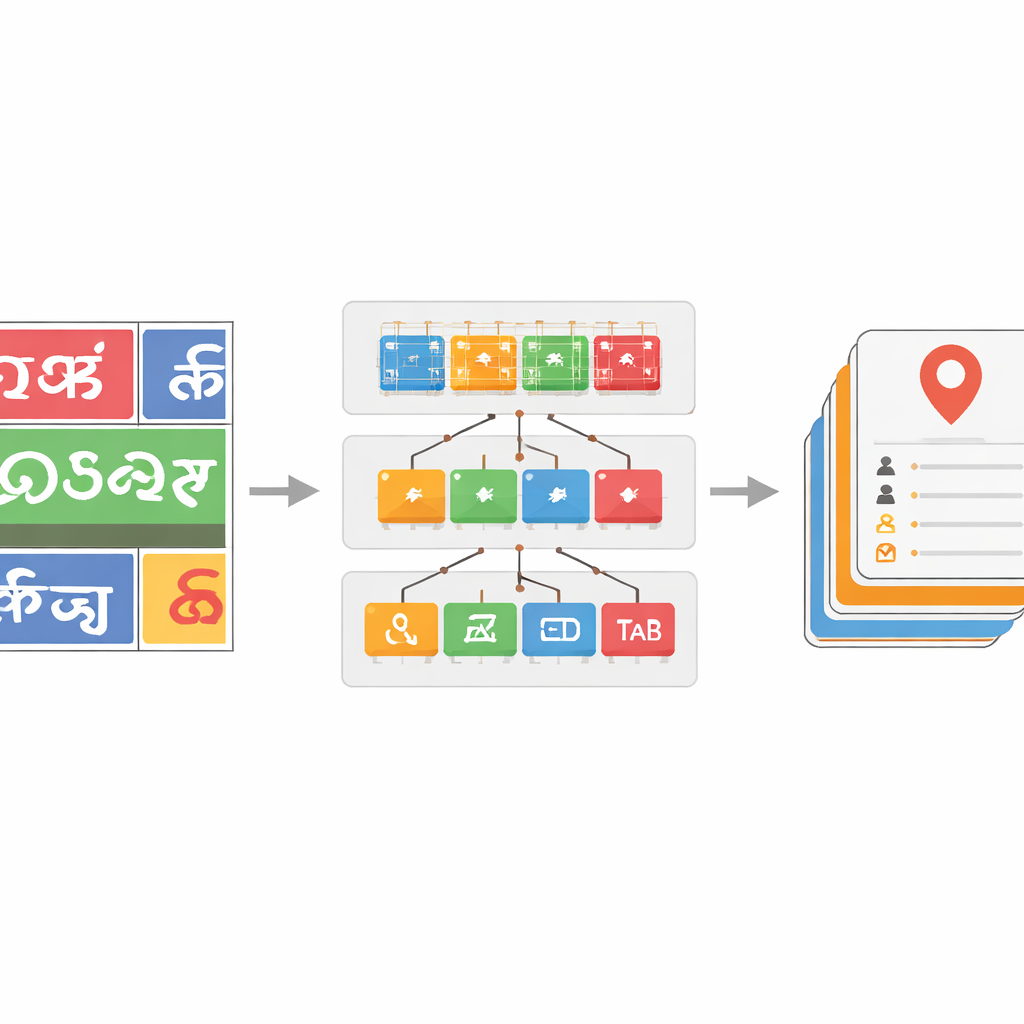
多数の文字体系と雑音の多いテキストに対処する学習
文字体系分類器を堅牢にするため、チームは実際の街路画像から抽出した単語画像の大規模データセットを精選し、公開データや合成サンプルで補強しました。カメラが交通の中で捉える像を模倣するために、ぼかし、ノイズ、遠近歪みなどの現実的な歪みを適用します。より深いResNetモデルが特に有効であり、最も強力なResNet-152は文字体系識別で約96%の精度を達成し、インディックシーンテキストの従来ベンチマークを上回りました。さらに、認識された単語に対する辞書ベースの補正ステップを導入しています。注釈付きデータから言語ごとの単語リストを構築し、各予測単語を編集距離で近傍の辞書項目と比較することで、貪欲探索アルゴリズムが誤読文字を修正できることが多くあります。これにより、スクリプトによっては単語レベルの精度が最大で17パーセントポイント向上し、騒がしい出力を大幅に浄化します。
生画像から実用的な関心地点へ
混雑した名板上で電話番号や税IDなど小さなフィールドの正確な位置を検出するのは依然難しく、物体検出器の平均適合率(AP)が33%という数値はこの課題を反映しています。しかし著者らは、不完全なバウンディングボックスであっても後続のテキスト認識や補正ステップに投入するには十分であり、辞書や文字体系認識モデルが各領域に何が含まれているかを整理するのに役立つことを示しています。中央のソフトウェア“ブリッジ”層がこれらのモジュールを調整し、データ形式を標準化し、低信頼度出力をフィルタリングし、システムの一部が不調なときにフォールバック戦略を適用します。最近の手法と比較評価した結果、フルパイプラインは文字体系認識、単語認識、関心地点フィールド検出において従来のシステムを上回り、特にグローバルデータセットで過小評価されがちな資源の少ないインディック文字で高い性能を示しました。
日常の利用者にとって何を意味するか
既存の深層学習ツールを言語特有のデータと賢い補正層とを慎重に組み合わせることで、著者らは多言語のインドの街頭看板を大規模に読み取り理解できる実用的なエンドツーエンドシステムを構築しました。最終出力は、名称、連絡先、その他の主要フィールドを含む各関心地点の構造化された機械可読な記述であり、これをデジタル地図、ナビアプリ、ローカル検索エンジンに直接取り込めます。日常の利用者にとっては、より正確な案内、近隣サービスの発見性の向上、インドの多様な文字体系と言語に等しく対応するデジタルツールの実現を意味します。本研究は、慎重な工学的設計により、人工知能がすべてを単一の文字に押し込めるのではなく、言語的多様性を保存し活用する手助けができることを示しています。
引用: Kashyap, A.K., Upadhya, M., Panwar, V.S. et al. Integrated framework utilizing scene text detection and recognition techniques for enhancing point of interest extraction from name boards in all Indic languages. Sci Rep 16, 12907 (2026). https://doi.org/10.1038/s41598-026-40742-w
キーワード: シーンテキスト認識, 多言語OCR, インディック文字体系, 関心地点抽出, 深層学習ビジョン