Clear Sky Science · pt
Estrutura integrada que utiliza técnicas de detecção e reconhecimento de texto em cena para aprimorar a extração de pontos de interesse a partir de placas em todas as línguas índicas
Mapas inteligentes para uma nação multilíngue
Encontrar o caminho em uma cidade indiana costuma significar escanear um emaranhado de letreiros de lojas, outdoors e placas de rua escritos em vários alfabetos. Humanos fazem isso com facilidade, mas mapas digitais e ferramentas de navegação ainda têm dificuldade para ler esses sinais de forma confiável. Este artigo apresenta um sistema integrado que ensina computadores a localizar e ler textos de imagens do mundo real em quase todas as principais escritas indianas, e então transformar essa informação em pontos de interesse limpos e pesquisáveis — abrindo caminho para navegação mais inteligente, busca local aprimorada e serviços digitais mais inclusivos.
Por que ler placas de rua é tão difícil para máquinas
Diferente de páginas impressas organizadas, cenas de rua são visualmente desordenadas. O texto aparece em ângulos estranhos, em tamanhos variados e contra fundos confusos. Na Índia, isso se complica ainda mais pelo uso de muitas escritas — como Devanagari, Tamil, Bengali e outras — que podem parecer semelhantes à primeira vista, mas diferem em detalhes cruciais. O reconhecimento óptico de caracteres tradicional, desenvolvido principalmente para alfabetos latinos e documentos limpos, falha diante de fotos de baixa resolução capturadas por veículos em movimento, placas sobrepostas e fontes ornamentais. Os autores se concentram em imagens capturadas por Sistemas Móveis de Mapeamento — veículos equipados com câmeras que fazem varredura das ruas — para enfrentar esses desafios do mundo real de frente.
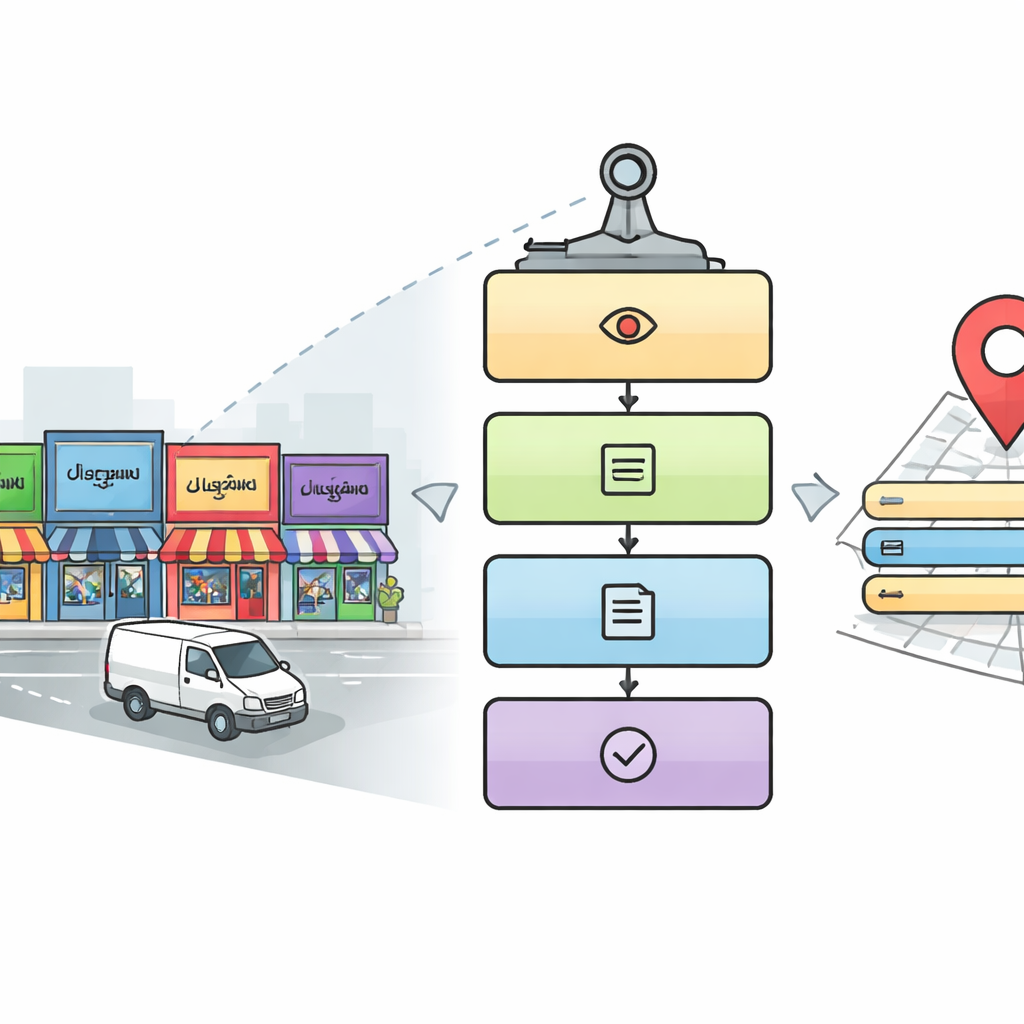
Um leitor digital em cinco etapas para ruas da cidade
Os pesquisadores projetam um fluxo de processamento em cinco estágios que imita como um leitor humano cuidadoso abordaria uma paisagem urbana complexa. Primeiro, um módulo de detecção varre cada imagem para encontrar áreas com probabilidade de conter letreiros e placas, usando uma abordagem popular de detecção de objetos chamada YOLOv5. Em seguida, o sistema recorta as regiões de texto dentro dessas áreas. No terceiro estágio, um modelo de aprendizado profundo baseado em redes ResNet identifica em qual escrita cada palavra recortada está escrita, escolhendo entre dez escritas índicas mais inglês. Uma vez conhecida a escrita, o quarto estágio usa um reconhecedor de caracteres correspondente para converter a imagem da palavra em texto digital. Por fim, um quinto estágio, em paralelo, busca na imagem detalhes-chave — como nome do local, elementos de endereço, número de telefone, código postal, ícones e número de identificação fiscal — e os reúne em um endereço completo legível por humanos e em um registro digital estruturado.
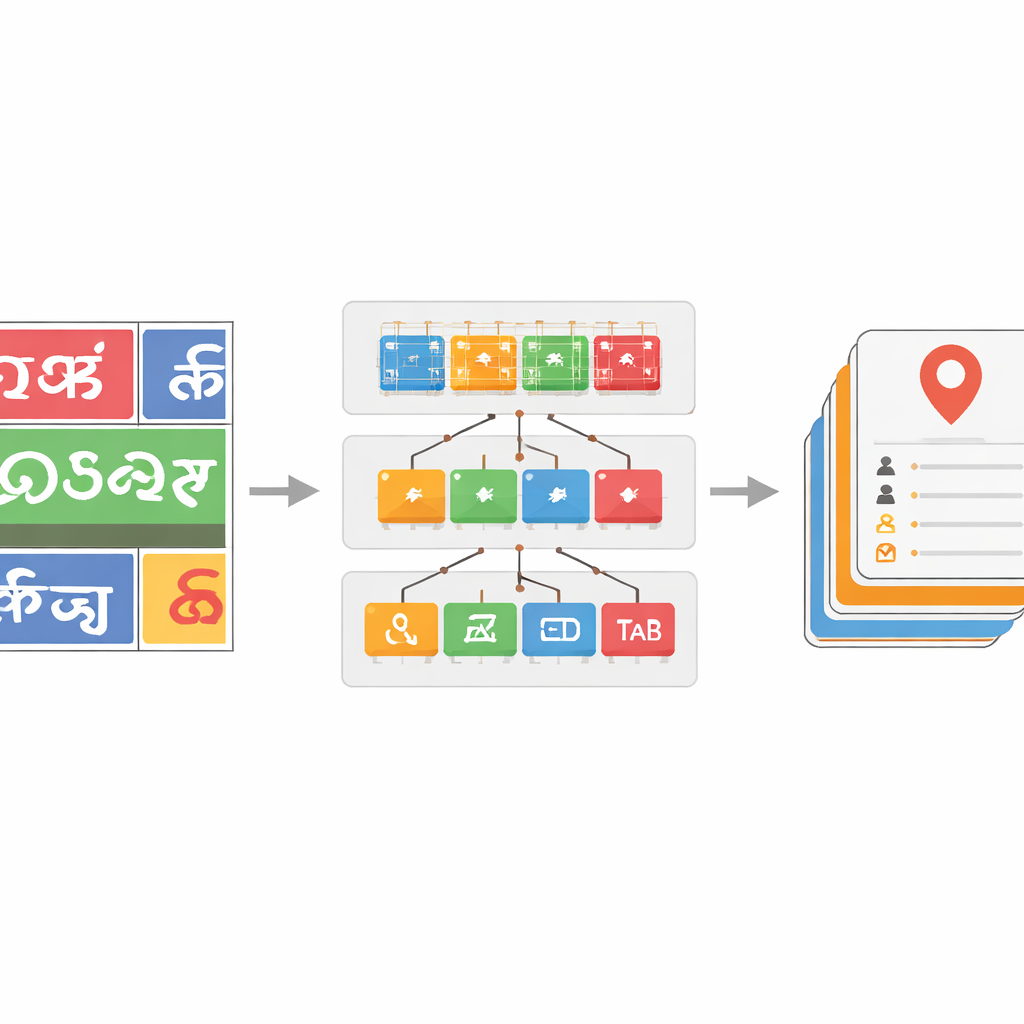
Ensinando o sistema a lidar com muitas escritas e texto ruidoso
Para tornar o classificador de escritas robusto, a equipe seleciona um grande conjunto de dados de imagens de palavras extraídas de imagens reais de rua, suplementado com bases públicas e amostras sintéticas. Eles aplicam distorções realistas — como desfoque, ruído e mudanças de perspectiva — para imitar o que as câmeras veem no tráfego. Modelos ResNet mais profundos demonstram-se particularmente eficazes, com a versão mais potente, ResNet-152, alcançando cerca de 96% de acurácia na discriminação entre escritas, superando benchmarks anteriores para texto de cena em escritas índicas. Além disso, introduzem um passo de correção baseado em dicionário para as palavras reconhecidas. Ao construir listas de palavras específicas por idioma a partir de dados anotados e comparar cada palavra prevista com entradas dicionárias próximas usando medidas de distância de edição, um algoritmo de busca gulosa frequentemente corrige caracteres lidos incorretamente. Isso proporciona ganhos de acurácia ao nível da palavra de até 17 pontos percentuais em algumas escritas, limpando significativamente saídas ruidosas.
De imagens brutas a pontos de interesse utilizáveis
Detectar a localização exata de campos pequenos como números de telefone ou identificações fiscais em placas lotadas continua sendo difícil, e a precisão média de 33% do detector de objetos reflete esse desafio. Contudo, os autores mostram que mesmo caixas delimitadoras imperfeitas podem ser suficientes para alimentar as etapas posteriores de reconhecimento e correção, onde o dicionário e os modelos sensíveis à escrita ajudam a esclarecer o conteúdo de cada região. Uma camada de software central tipo "ponte" coordena todos esses módulos, padronizando formatos de dados, filtrando saídas de baixa confiança e aplicando estratégias de contingência quando uma parte do sistema falha. Ao ser avaliado contra abordagens recentes, o pipeline completo supera sistemas anteriores em reconhecimento de escrita, reconhecimento de palavras e detecção de campos de pontos de interesse, particularmente para escritas índicas de poucos recursos que frequentemente são sub-representadas em bases de dados globais.
O que isso significa para usuários do dia a dia
Ao combinar cuidadosamente ferramentas existentes de aprendizado profundo com dados específicos por idioma e uma camada inteligente de correção, os autores constroem um sistema prático e de ponta a ponta que pode ler e entender letreiros multimilíngues indianos em escala. A saída final é uma descrição estruturada e legível por máquina de cada ponto de interesse — completa com nome, dados de contato e outros campos importantes — que pode ser integrada diretamente a mapas digitais, aplicativos de navegação e mecanismos de busca locais. Para usuários cotidianos, isso pode significar direções mais precisas, melhor descoberta de serviços próximos e ferramentas digitais que funcionem igualmente bem através das muitas escritas e línguas da Índia. O trabalho demonstra que, com engenharia cuidadosa, a inteligência artificial pode ajudar a preservar e aproveitar a diversidade linguística em vez de forçar tudo a um único sistema de escrita.
Citação: Kashyap, A.K., Upadhya, M., Panwar, V.S. et al. Integrated framework utilizing scene text detection and recognition techniques for enhancing point of interest extraction from name boards in all Indic languages. Sci Rep 16, 12907 (2026). https://doi.org/10.1038/s41598-026-40742-w
Palavras-chave: reconhecimento de texto em cena, OCR multilíngue, escritas índicas, extração de pontos de interesse, visão profunda