Clear Sky Science · nl
Geïntegreerd kader dat technieken voor detectie en herkenning van tekst in scènes benut om punten van interesse van naamborden in alle Indiase talen te verbeteren
Slimme kaarten voor een meertalig land
Je weg vinden in een Indiase stad betekent vaak dat je een wirwar van winkelborden, reclameborden en straatnaamborden moet scannen die in vele verschillende schriftsystemen zijn geschreven. Mensen doen dit moeiteloos, maar digitale kaarten en navigatietools hebben nog steeds moeite om deze borden betrouwbaar te lezen. Dit artikel presenteert een geïntegreerd systeem dat computers leert tekst te zien en te lezen uit real-world afbeeldingen in vrijwel alle belangrijke Indiase schriftsystemen, en die informatie omzet in schone, doorzoekbare interessepunten — een stap naar slimmer navigeren, betere lokale zoekfuncties en meer inclusieve digitale diensten.
Waarom straatborden lezen zo moeilijk is voor machines
In tegenstelling tot nette gedrukte pagina’s zijn straatbeelden visueel rommelig. Tekst verschijnt onder vreemde hoeken, in verschillende formaten en tegen drukke achtergronden. In India wordt dit nog gecompliceerder door het gebruik van veel schriftsystemen—zoals Devanagari, Tamil, Bengali en anderen—die op het eerste gezicht vergelijkbaar kunnen lijken maar in cruciale details verschillen. Traditionele optische tekenherkenning, ontworpen vooral voor het Latijnse alfabet en schone documenten, faalt bij lage-resolutiefoto’s van bewegende voertuigen, overlappende borden en decoratieve lettertypen. De auteurs richten zich op beelden vastgelegd door Mobile Mapping Systems—voertuigen met camera’s die stadsstraten in kaart brengen—om deze uitdagingen uit de echte wereld direct aan te pakken.
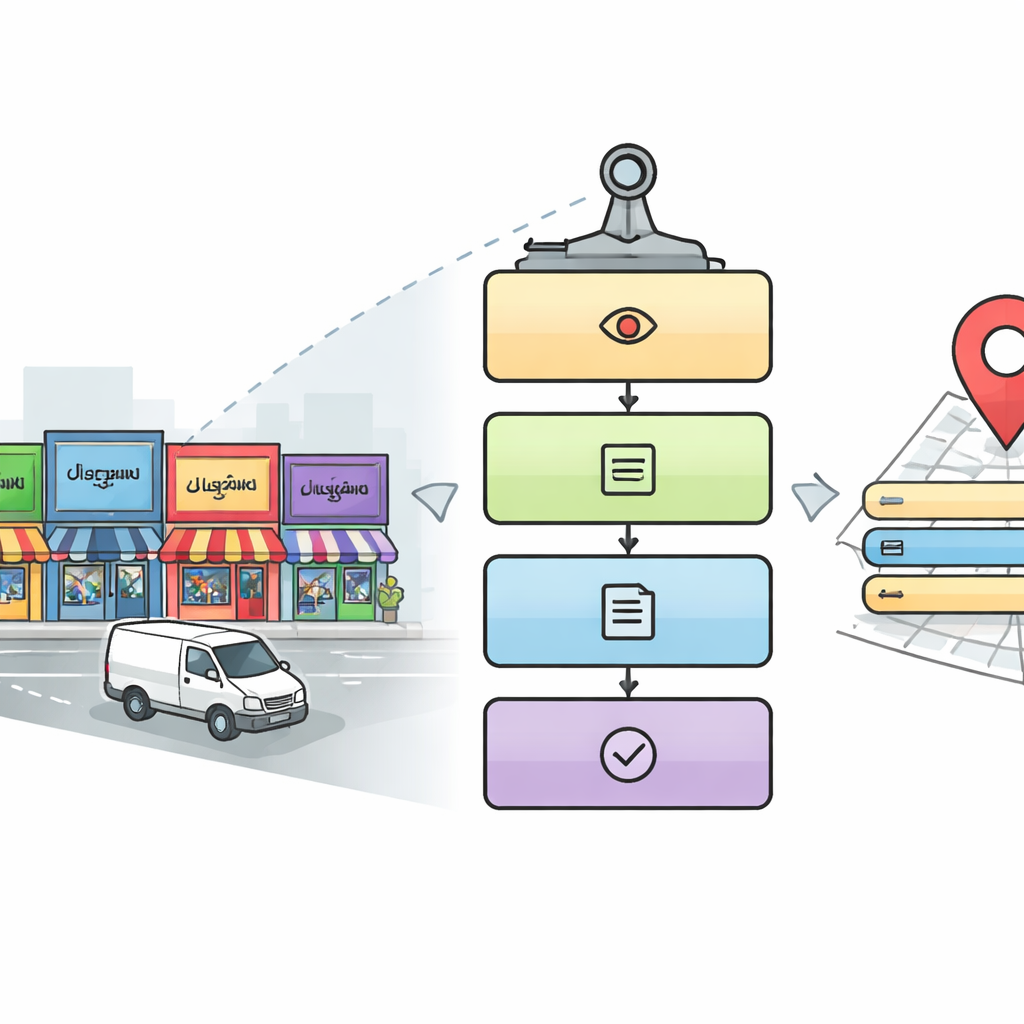
Een vijfstaps digitale lezer voor straatbeelden
De onderzoekers ontwerpen een vijf-fasen pijplijn die het lezen van een complexe straatscène door een oplettende mens nabootst. Eerst scant een detectiemodule elke afbeelding om gebieden te vinden die waarschijnlijk relevante borden en naamborden bevatten, met behulp van een populaire objectdetectie-aanpak genaamd YOLOv5. Vervolgens snijdt het systeem de tekstgebieden uit binnen die gebieden. In de derde fase identificeert een deep-learningmodel gebaseerd op ResNet-netwerken welk schrift elk uitgesneden woord gebruikt, waarbij wordt gekozen uit tien Indiase schriftsystemen plus Engels. Zodra het schrift bekend is, gebruikt een vierde fase een bijpassende tekenherkenner om de afbeelding van het woord om te zetten in digitale tekst. Ten slotte zoekt een vijfde, parallelle fase in de afbeelding naar sleutelgegevens—zoals plaatsnaam, adrescomponenten, telefoonnummer, postcode, iconen en belastingidentificatienummer—en zet die om in een volledige, mensleesbare adresregel en een gestructureerd digitaal record.
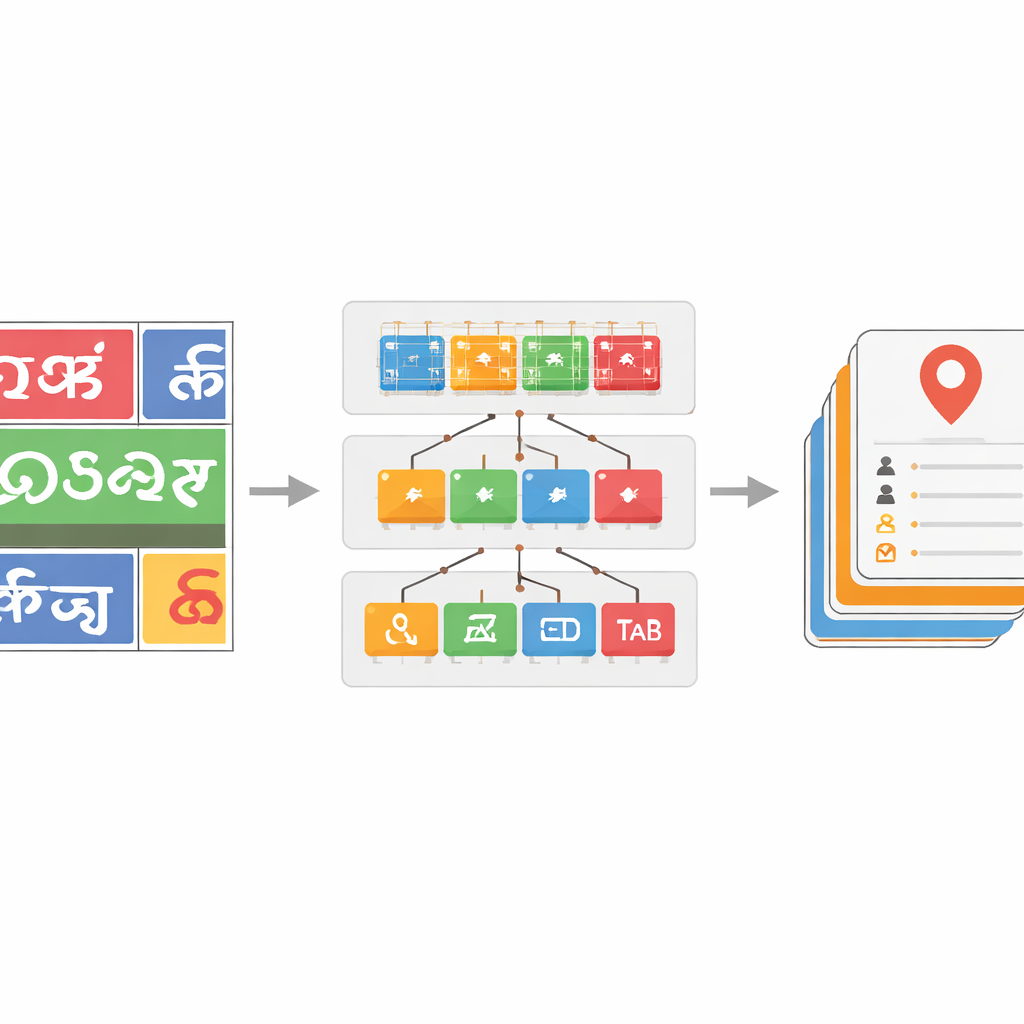
Het systeem leren omgaan met veel schriftsystemen en lawaaierige tekst
Om de schriftclassificator robuust te maken, stelt het team een grote dataset samen van woordafbeeldingen afkomstig uit echte straatbeelden, aangevuld met openbare datasets en synthetische voorbeelden. Ze passen realistische vervormingen toe—zoals onscherpte, ruis en perspectiefveranderingen—om te imiteren wat camera’s in het verkeer zien. Diepere ResNet-modellen blijken bijzonder effectief, waarbij de krachtigste versie, ResNet-152, ongeveer 96 procent nauwkeurigheid bereikt in het onderscheiden van schriftsystemen, beter dan eerdere benchmarks voor scene text in Indiase schriftsystemen. Daarbovenop introduceren ze een woordenboek-gebaseerde correctiestap voor de herkende woorden. Door taalspecifieke woordlijsten te bouwen uit geannoteerde gegevens en elk voorspeld woord te vergelijken met nabijgelegen woordenboekvermeldingen met behulp van bewerkingsafstand (edit-distance), kan een gierige zoekalgoritme vaak verkeerd gelezen tekens herstellen. Dit levert woordniveau-nauwkeurigheidswinst op tot wel 17 procentpunten in sommige schriftsystemen en maakt de ruis in de uitvoer aanzienlijk schoner.
Van ruwe afbeeldingen naar bruikbare interessepunten
Het detecteren van de exacte locatie van kleine velden zoals telefoonnummers of belasting-ID’s op drukke borden blijft moeilijk, en de gemiddelde precisie van de objectdetector van 33 procent weerspiegelt deze uitdaging. De auteurs laten echter zien dat zelfs onvolmaakte begrenzingsvakken vaak voldoende zijn om door de latere tekst- en correctiestappen gevoed te worden, waarbij het woordenboek en de schriftbewuste modellen helpen te bepalen wat elk gebied daadwerkelijk bevat. Een centrale software "brug"-laag coördineert al deze modules, standaardiseert gegevensformaten, filtert outputs met lage betrouwbaarheid en past terugvalstrategieën toe wanneer een deel van het systeem faalt. Bij evaluatie tegen recente benaderingen overtreft de volledige pijplijn eerdere systemen op het gebied van schriftherkenning, woordherkenning en detectie van velden van interessepunten, met name voor laag-resources Indiase schriftsystemen die vaak ondervertegenwoordigd zijn in wereldwijde datasets.
Wat dit betekent voor alledaagse gebruikers
Door bestaande deep-learningtools zorgvuldig te combineren met taalspecifieke data en een slimme correctielaag bouwen de auteurs een praktisch end-to-endsysteem dat meertalige Indiase straatborden op schaal kan lezen en begrijpen. De uiteindelijke output is een gestructureerde, machineleesbare beschrijving van elk interessepunt—compleet met naam, contactgegevens en andere sleutelvelden—die direct kan worden geïntegreerd in digitale kaarten, navigatie-apps en lokale zoekmachines. Voor alledaagse gebruikers kan dit betekenen: nauwkeurigere routes, betere vindbaarheid van nabijgelegen diensten en digitale hulpmiddelen die even goed werken voor de vele schriftsystemen en talen van India. Het werk laat zien dat kunstmatige intelligentie met doordachte engineering kan bijdragen aan het behouden en benutten van taalkundige diversiteit in plaats van alles in één enkel schrift te dwingen.
Bronvermelding: Kashyap, A.K., Upadhya, M., Panwar, V.S. et al. Integrated framework utilizing scene text detection and recognition techniques for enhancing point of interest extraction from name boards in all Indic languages. Sci Rep 16, 12907 (2026). https://doi.org/10.1038/s41598-026-40742-w
Trefwoorden: scene text recognition, meertalige OCR, Indiase schriftbeelden, extractie van interessepunten, deep learning vision