Clear Sky Science · en
Integrated framework utilizing scene text detection and recognition techniques for enhancing point of interest extraction from name boards in all Indic languages
Smart Maps for a Multilingual Nation
Finding your way in an Indian city often means scanning a blur of shop signs, billboards, and street boards written in many different scripts. Humans do this with ease, but digital maps and navigation tools still struggle to read these signs reliably. This paper presents an integrated system that teaches computers to spot and read text from real-world images in almost all major Indian scripts, then turn that information into clean, searchable points of interest—paving the way for smarter navigation, better local search, and more inclusive digital services.
Why Reading Street Signs Is So Hard for Machines
Unlike tidy printed pages, street scenes are visually messy. Text appears at odd angles, in different sizes, and against cluttered backgrounds. In India, this is complicated further by the use of many scripts—such as Devanagari, Tamil, Bengali, and others—which can look similar at a glance but differ in critical details. Traditional optical character recognition, built mainly for Latin alphabets and clean documents, falters when faced with low-resolution photos from moving vehicles, overlapping signs, and decorative fonts. The authors focus on images captured by Mobile Mapping Systems—vehicles equipped with cameras that survey city streets—to tackle these real-world challenges head-on.
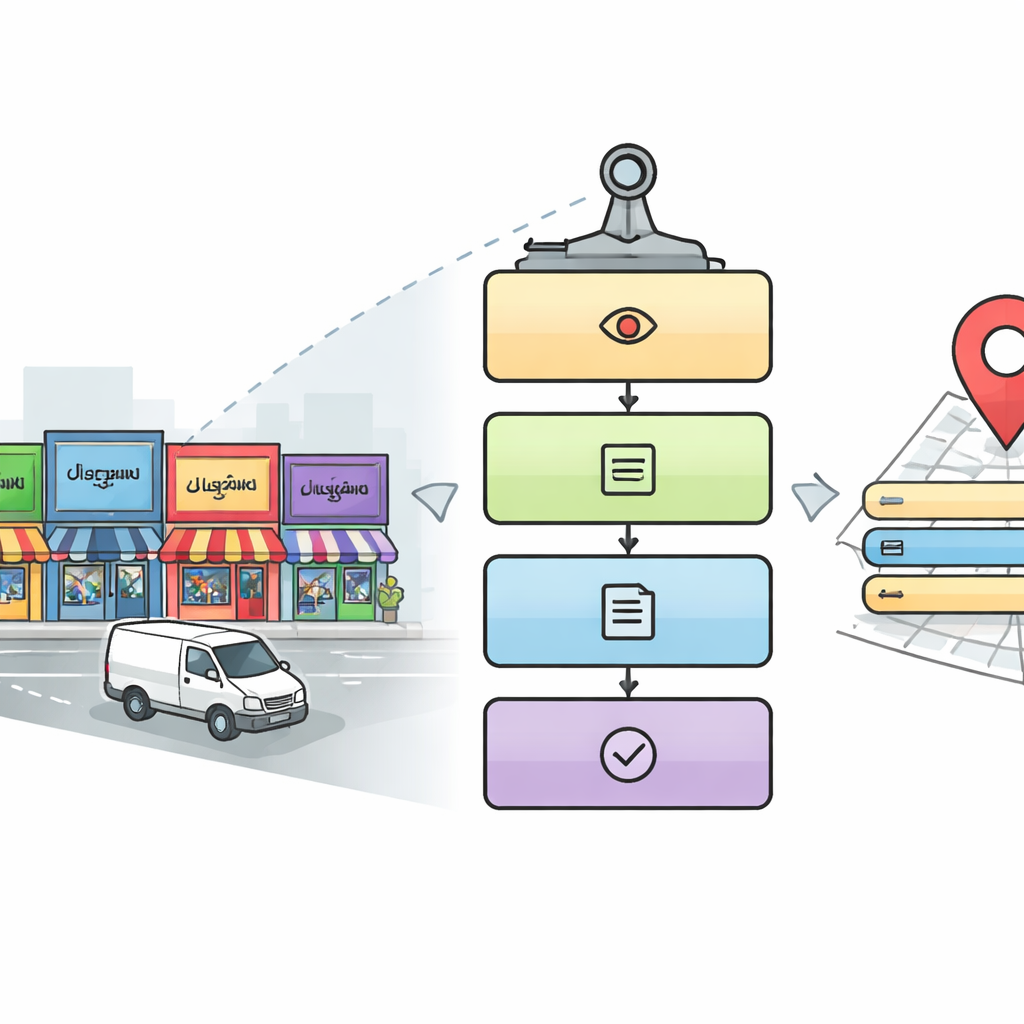
A Five-Step Digital Reader for City Streets
The researchers design a five-stage pipeline that mimics how a careful human might read a complex streetscape. First, a detection module scans each image to find areas likely to contain relevant signs and name boards, using a popular object-detection approach called YOLOv5. Next, the system crops out the text regions inside those areas. In the third stage, a deep learning model based on ResNet networks identifies which script each cropped word is written in, choosing among ten Indic scripts plus English. Once the script is known, a fourth stage uses a matching character recognizer to convert the image of the word into digital text. Finally, a fifth, parallel stage searches the image for key details—such as place name, address elements, phone number, postal code, icons, and tax identification number—and assembles them into a complete, human-readable address and a structured digital record.
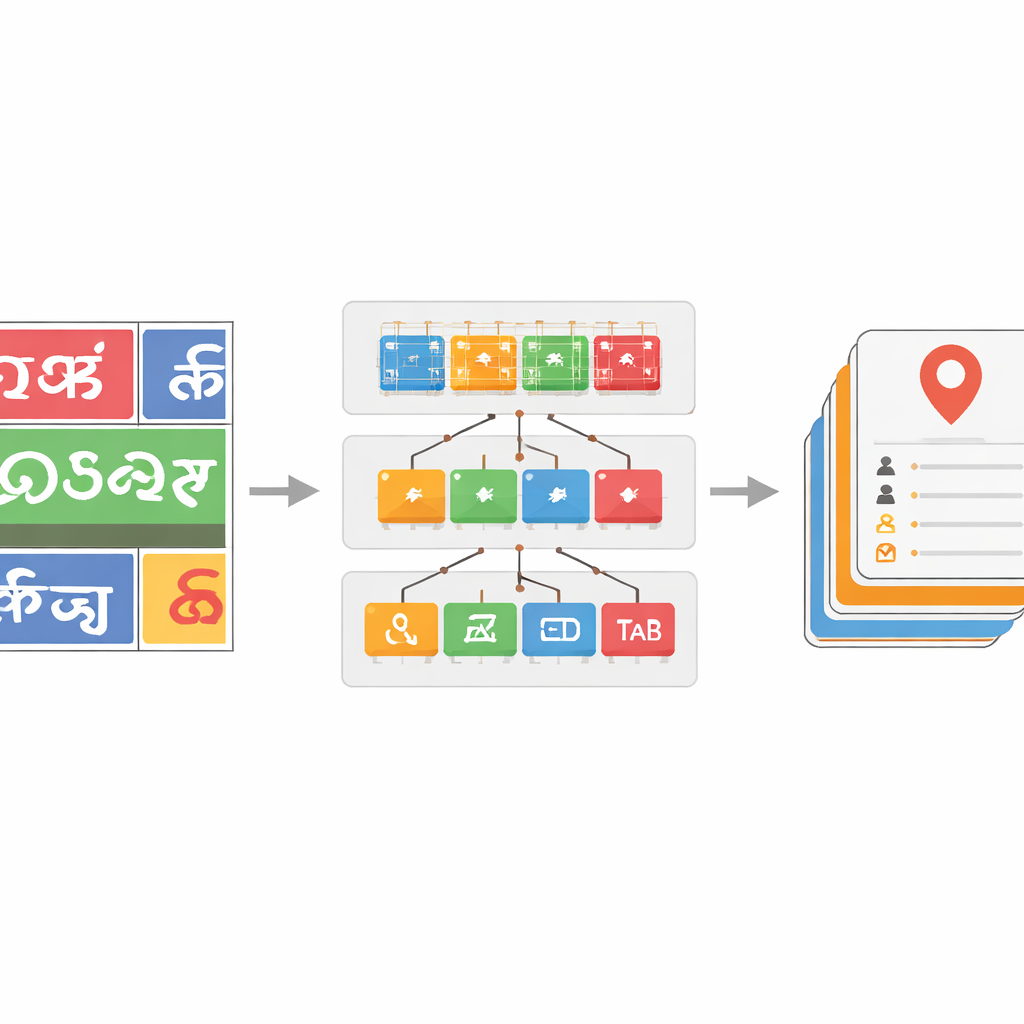
Teaching the System to Handle Many Scripts and Noisy Text
To make the script classifier robust, the team curates a large dataset of word images drawn from actual street imagery, supplemented with public datasets and synthetic samples. They apply realistic distortions—such as blur, noise, and perspective changes—to mimic what cameras see in traffic. Deeper ResNet models prove particularly effective, with the most powerful version, ResNet-152, achieving about 96 percent accuracy in telling scripts apart, better than earlier benchmarks for Indic scene text. On top of this, they introduce a dictionary-based correction step for the recognized words. By building language-specific word lists from annotated data and comparing each predicted word to nearby dictionary entries using edit-distance measures, a greedy search algorithm can often fix misread characters. This yields word-level accuracy gains of up to 17 percentage points in some scripts, substantially cleaning up noisy outputs.
From Raw Images to Usable Points of Interest
Detecting the exact location of small fields like phone numbers or tax IDs on crowded boards remains difficult, and the object detector’s average precision of 33 percent reflects this challenge. However, the authors show that even imperfect bounding boxes can be good enough to feed into later text and correction steps, where the dictionary and script-aware models help sort out what each region actually contains. A central software "bridge" layer coordinates all these modules, standardizing data formats, filtering out low-confidence outputs, and applying fallback strategies when one part of the system falters. When evaluated against recent approaches, the full pipeline outperforms prior systems on script recognition, word recognition, and point-of-interest field detection, particularly for low-resource Indic scripts that are often underrepresented in global datasets.
What This Means for Everyday Users
By carefully combining existing deep learning tools with language-specific data and a smart correction layer, the authors build a practical, end-to-end system that can read and understand multilingual Indian street signs at scale. The final output is a structured, machine-readable description of each point of interest—complete with name, contact details, and other key fields—that can plug directly into digital maps, navigation apps, and local search engines. For everyday users, this could mean more accurate directions, better discovery of nearby services, and digital tools that work equally well across India’s many scripts and languages. The work shows that with thoughtful engineering, artificial intelligence can help preserve and leverage linguistic diversity rather than forcing everything into a single script.
Citation: Kashyap, A.K., Upadhya, M., Panwar, V.S. et al. Integrated framework utilizing scene text detection and recognition techniques for enhancing point of interest extraction from name boards in all Indic languages. Sci Rep 16, 12907 (2026). https://doi.org/10.1038/s41598-026-40742-w
Keywords: scene text recognition, multilingual OCR, Indic scripts, point of interest extraction, deep learning vision