Clear Sky Science · tr
Otomatize edilmiş yönergelerle LLM tabanlı tıbbi diyalog veri seti üretimi
Neden sentetik tıbbi sohbetler önemli
Hastaneler konuşmalarla doludur: doktorların hastalara soru sorması, hemşirelerin tedavileri açıklaması ve meslektaşların tanılar üzerinde tartışması. Bu konuşmalar bakım için hayati önem taşır, fakat gizlilik yasaları ve sağlık bilgilerinin hassasiyeti nedeniyle kaydetmek ve paylaşmak zordur. Aynı zamanda Çin hastanelerinde çalışmak isteyen uluslararası öğrenciler, gerçekçi çok turlu tıbbi diyalogları gerektiren Tıbbi Çince Testi'ni (MCT) geçmek zorundadır. Bu makale, ChatGPT benzeri büyük dil modellerini kullanarak Çince için zengin, güvenli ve sınav odaklı bir tıbbi konuşma koleksiyonunu otomatik şekilde oluşturma yöntemini anlatır.
Gerçek hastalara dokunmadan kullanışlı veri oluşturmak
Yazarlar önemli bir sorunu ele alıyor: gerçek hasta bilgilerini açığa çıkarmadan dil becerilerini eğitmek ve test etmek için yeterli yüksek kaliteli tıbbi diyalog verisi nasıl elde edilir? Yaygın halka açık sohbet veri setleri, gerçek tıbbi karşılaşmaların karmaşıklığını, profesyonelliğini veya etik kurallarını karşılamaz. Tıbbi konuşmalar uzun, çok sayıda bağlı tur içerir ve rol kalıplarına—doktorların profesyonel ifadeleri, hastaların günlük betimlemeleri ve hemşirelerin bakım koordinasyonu—uymalıdır. Üstelik MCT kendi resmi yönergelerine sahiptir; hangi konuların, görevlerin ve kelime dağarcığının yer alması gerektiğini belirler. Bir dil modelinden sadece "diyalog uydurması" istenirse genellikle gerçekçi olmayan veya standart dışı içerik üretilir; bu yüzden ekip üretimi yönlendirmek için yapılandırılmış bir çerçeve tasarlar.
El yapımı istemlerden gelişen bir yönerge havuzuna
AIG-MCT adlı çerçeve, dil modeli için ayrıntılı istemler gibi davranan küçük, el yapımı bir yönerge setiyle başlar. Her yönerge kimlerin konuştuğunu (doktor, hasta, hemşire), tıbbi senaryoyu (ör. pediatri kliniği veya acil servis), görevi (öykü alma, tanı, tedavi tartışması, önleme tavsiyesi), istenen diyalog tur sayısını ve yaklaşık uzunluğu tanımlar. Bu başlangıç yönergeleri MCT görev taslağı, konu listesi ve resmi tıbbi kelime dağarcığından özenle oluşturulur ve ortaya çıkan konuşmaların gerçekçi tıbbi ortamlar içinde kalmasını ve MCT adayları için uygun belirli karmaşıklık seviyelerini karşılamasını şart koşar.
Çeşitlilik için filtreleme, puanlama ve akıllı örnekleme
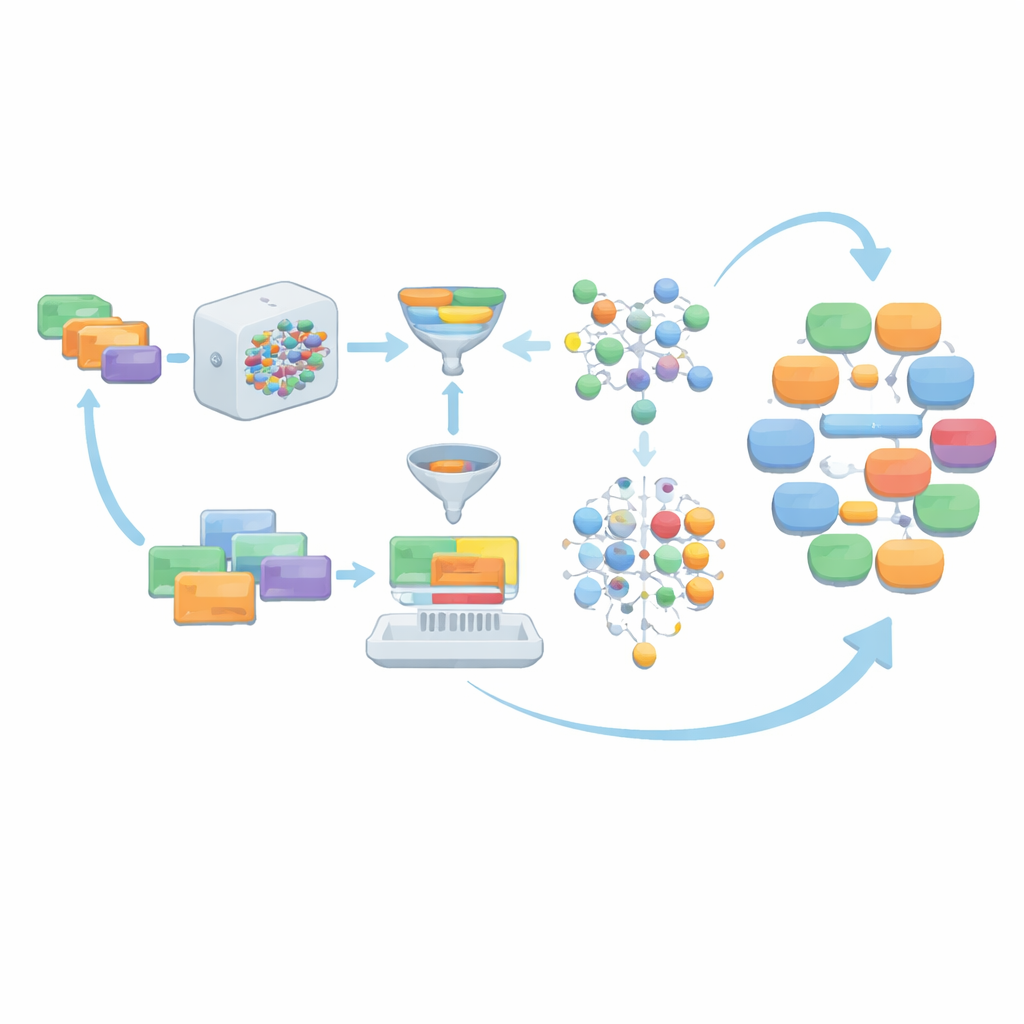
Dil modeli bu yönergelerden diyaloglar ürettiğinde, ham çıktı doğrudan kabul edilmez. Bunun yerine birkaç temizleme katmanından geçirilir. Kayıt benzeri listeler veya yapılandırılmış veriler gibi diyalog olmayan materyaller çıkarılır. Konuşmacı rolleri MCT ihtiyaçlarına uyması için dört ana ilişki türünde standartlaştırılır—doktor–hasta, doktor–hemşire, doktor–doktor ve hasta–hemşire. Ekip daha sonra her diyalogun resmi MCT tıbbi kelime dağarcığından yeterince kelime kullanıp kullanmadığını, asgari tur sayısına ulaşıp ulaşmadığını ve uzunluğunun özenle seçilmiş bir aralıkta olup olmadığını kontrol eder. İsteğe bağlı dilbilgisi düzeltme araçları dili daha da cilalar. Bu kontrolleri geçemeyen diyaloglar ve bunların temel yönergeleri elenir; böylece sadece güçlü örnekler kalır.
Modelin daha iyi istemler yazmasına izin vermek
Başlangıçta insan tarafından yazılmış istemlere sonsuza dek bağımlı kalmak yerine, AIG-MCT sistemin kendi çıktılarından yeni yönergeler öğrenmesine izin verir. Dil modelinden yalnızca diyalog üretmesi değil, aynı zamanda yeni makine tarafından üretilmiş yönergeler önermesi de istenir. Maksimal Marjinal Alaka (Maximal Marginal Relevance) adlı bir teknik, mevcut havuzla hem ilgili hem de zaten var olandan açıkça farklı yönergeleri seçmek için kullanılır; bu, yönergelerin ve onların ortaya çıkardığı diyalogların benzerlikleri karşılaştırılarak yapılır. Bu aday yönergeler daha sonra K-means algoritması ile kümelemeye tabi tutulur ve her kümeden temsilci yönergeler seçilerek yönerge havuzu yenilenir. Birçok tur boyunca insan yazımı istemlerin payı kademeli olarak azaltılırken, özenle seçilmiş makine üretimi istemler devralır; böylece çeşitlilik korunur ama MCT kurallarına uyum kaybolmaz.
Ortaya çıkan tıbbi sohbet koleksiyonu ne kadar iyi?
Yaklaşımlarını test etmek için yazarlar ana üretici olarak ChatGPT (gpt-3.5-turbo) ve tıbbi içerik kontrolüne yardımcı olmak üzere uzmanlaşmış bir tıbbi dil modeli olan ZuoYi'yi kullandı. Bu süreci 40 iterasyon boyunca yineleyip otomatik filtreleri insan uzman incelemesiyle birleştirerek nihayetinde yaklaşık 20.000 çok turlu diyalog içeren MCT-Chat adlı bir veri seti oluşturdular. Ekip MCT-Chat'i MedDialog, MedDG ve DISC-Med-SFT gibi tanınmış gerçek dünya Çince tıbbi diyalog veri setleriyle karşılaştırdı. Objektif ölçümler MCT-Chat'in söz dizimsel çeşitlilik ve zengin ifade açısından çok güçlü olduğunu, aynı zamanda sınav ortamına uygun hedefli bir hastalık ve belirti setine odaklandığını gösterdi. Ayrıca geniş bir diyalog rolü, konu ve görev yelpazesini kapsıyor ve tipik uzunluğu ile tur sayısı MCT beklentileriyle iyi uyum sağlıyor.
Uzman değerlendirmeleri ve geleceğe yönelik yönelimler
Beş tıbbi uzman MCT-Chat ve karşılaştırma veri setlerinden rastgele örnekleri puanladı. Akıcılık, tarafsızlık, tıbbi sağlamlık, MCT gereksinimleriyle uyum ve farklı yeterlilik seviyelerini ayırt etme yeteneğini değerlendirdiler. MCT-Chat çoğunlukla gerçek dünya veri setleriyle eşdeğer ya da biraz daha iyi puan aldı; özellikle akıl yürütme ve değerlendirme ayırt ediciliğinde öne çıktı. Bu, sentetik verinin sınav materyali için ciddi bir aday olabileceğini düşündürüyor—ancak yazarlar gerçek sınav maddelerinin sıkı manuel incelemeden geçmesi gerektiğini vurguluyor. Ayrıca hâlâ zorluklar olduğunu belirtiyorlar: dil modelleri karmaşık konuları yanlış yorumlayabilir ve uzun diyaloglar dikkatli kontrol olmadan tekrara düşebilir. Yazarlar kümeleme adımını geliştirmeyi, daha gelişmiş bilgi güncellemeleri entegre etmeyi ve çerçeveyi çokdilli ve çokkültürlü ortamlara genişleterek dünya çapında benzer sınav uyumlu tıbbi diyalog veri setleri oluşturmayı öneriyorlar.
Uzman olmayanlar için çıkarım
Bu çalışma gösteriyor ki doğru güvenlik önlemleri ve akıllı örnekleme stratejileriyle büyük dil modelleri, belirli bir dil sınavına yönelik gerçekçi, gizlilik açısından güvenli tıbbi konuşmalar oluşturabilir. Resmi yönergeler, otomatik filtreler ve uzman incelemesini karıştırarak yazarlar Tıbbi Çince Testi'ne yakından uyan 20.000 diyalogluk bir veri seti inşa etti. Hastalar ve öğrenenler için çıkarım şu: geleceğin doktorları, hassas gerçek dünya verilerine daha az bağımlı kalarak aynı zamanda gerçek hastane iletişimine hazırlık sağlayan sentetik ama güvenilir diyaloglarla eğitilip değerlendirilebilirler.
Atıf: Zhou, H., Hu, X., He, T. et al. LLM-based medical dialogue dataset generation with automated instructions. Sci Rep 16, 12410 (2026). https://doi.org/10.1038/s41598-025-34835-1
Anahtar kelimeler: sentetik tıbbi diyalog, büyük dil modelleri, Tıbbi Çince testi, yönerge üretimi, tıbbi dil eğitimi