Clear Sky Science · pl
Generowanie zbioru rozmów medycznych przez LLM z automatycznymi instrukcjami
Dlaczego syntetyczne rozmowy medyczne są ważne
W szpitalach odbywa się mnóstwo rozmów: lekarze wypytują pacjentów, pielęgniarki wyjaśniają leczenie, a współpracownicy omawiają diagnozy. Te rozmowy są kluczowe dla opieki, ale trudno je rejestrować i udostępniać ze względu na prawo do prywatności i wrażliwy charakter informacji medycznych. Jednocześnie studenci zagraniczni, którzy chcą pracować w chińskich szpitalach, muszą zdać Medical Chinese Test (MCT), który wymaga realistycznych, wieloturowych dialogów medycznych. Artykuł opisuje metodę wykorzystania dużych modeli językowych — systemów typu ChatGPT — do automatycznego tworzenia bogatej, bezpiecznej i gotowej do egzaminu kolekcji rozmów medycznych w języku chińskim.
Tworzenie użytecznych danych bez kontaktu z prawdziwymi pacjentami
Autorzy stawiają czoło kluczowemu problemowi: jak uzyskać wystarczająco dużo wysokiej jakości danych dialogowych do treningu i testowania umiejętności językowych, nie narażając informacji o prawdziwych pacjentach. Zwykłe publiczne zbiory rozmów nie odzwierciedlają złożoności, fachowości ani zasad etycznych prawdziwych spotkań medycznych. Rozmowy medyczne są długie, silnie powiązane przez wiele tur i muszą respektować ścisłe role — lekarze mówią fachowo, pacjenci używają potocznych opisów, a pielęgniarki koordynują opiekę. Ponadto MCT ma własne oficjalne wytyczne określające tematy, zadania i słownictwo, które powinny się pojawić. Proste polecenie modelowi językowemu „wymyśl” dialogi często daje treść nierealistyczną lub niestandardową, dlatego zespół zaprojektował ustrukturyzowane ramy do kierowania generacją.
Od ręcznie przygotowanych promptów do ewoluującej puli instrukcji
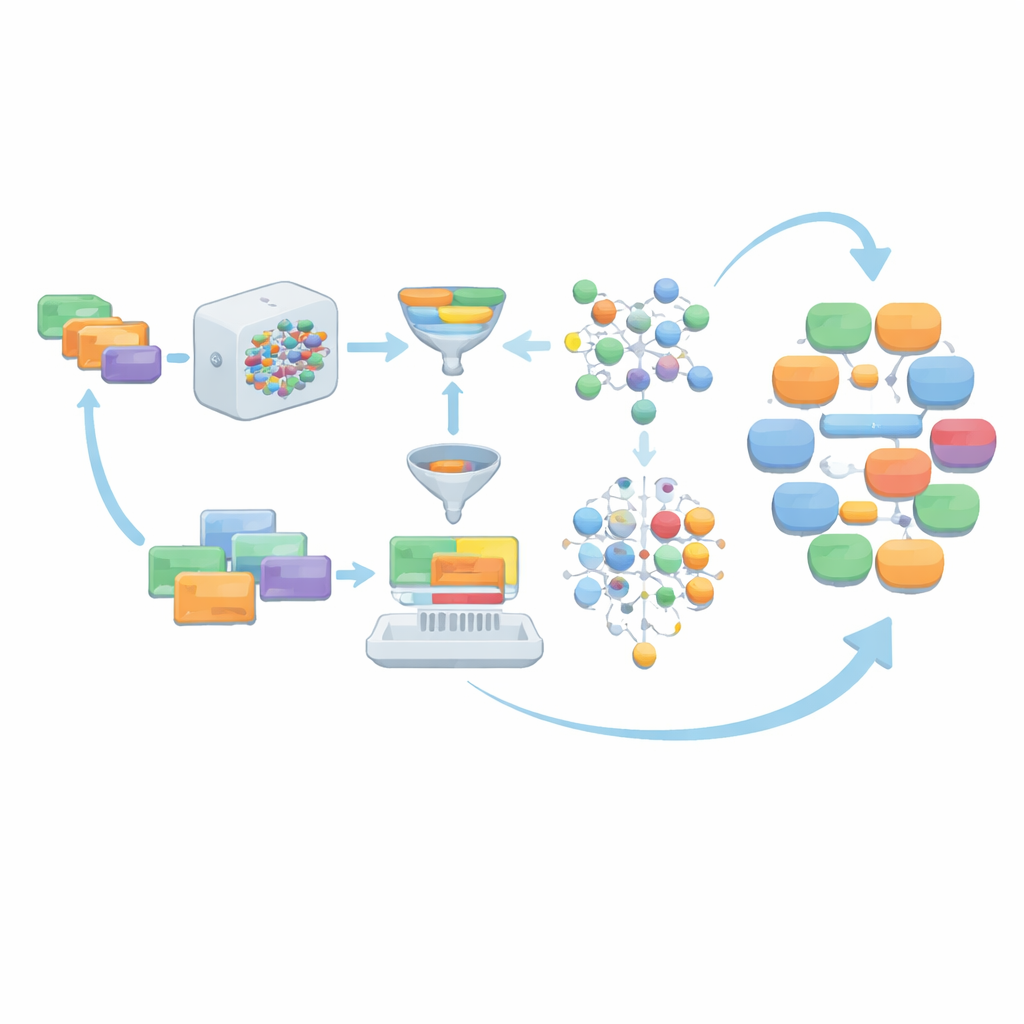
Ramę nazwaną AIG-MCT rozpoczyna niewielki, ręcznie opracowany zestaw instrukcji działających jak szczegółowe promptu dla modelu językowego. Każda instrukcja opisuje, kto rozmawia (lekarz, pacjent, pielęgniarka), scenariusz medyczny (np. poradnia pediatryczna czy oddział ratunkowy), zadanie (wywiad, diagnoza, omówienie leczenia, porady zapobiegawcze), pożądaną liczbę tur dialogu i przybliżoną długość. Te wstępne instrukcje są starannie zbudowane na podstawie zarysu zadań MCT, listy tematów i oficjalnego słownictwa medycznego; wymuszają też, by powstałe rozmowy pozostawały w realistycznych ramach medycznych i spełniały określone poziomy złożoności odpowiednie dla kandydatów MCT.
Filtrowanie, ocenianie i inteligentne próbkowanie dla różnorodności
Gdy model językowy generuje dialogi na podstawie tych instrukcji, surowe wyniki nie są przyjmowane bez sprawdzenia. Przechodzą przez kilka warstw oczyszczania. Materiały niebędące dialogami, takie jak listy przypominające rekordy czy dane strukturalne, są usuwane. Role mówców standaryzuje się do czterech głównych relacji — lekarz–pacjent, lekarz–pielęgniarka, lekarz–lekarz i pacjent–pielęgniarka — aby dopasować je do wymagań MCT. Zespół sprawdza następnie, czy każdy dialog używa wystarczającej liczby słów z oficjalnego słownika MCT, czy osiąga minimalną liczbę tur i czy jego długość mieści się w starannie dobranym zakresie. Opcjonalne narzędzia korekty gramatycznej dodatkowo szlifują język. Dialogi, które nie przejdą tych kontroli, wraz z odpowiadającymi im instrukcjami, są odrzucane, tak że pozostają tylko mocne przykłady.
Pozwolić modelowi pomagać w pisaniu lepszych promptów
Zamiast polegać wiecznie na początkowych, ręcznie napisanych promptach, AIG-MCT pozwala systemowi uczyć się nowych instrukcji z własnych wyników. Model językowy proszony jest nie tylko o tworzenie dialogów, ale też o proponowanie nowych, maszynowo wygenerowanych instrukcji. Technika zwana Maximal Marginal Relevance służy do wybierania instrukcji, które są zarówno istotne względem istniejącej puli, jak i wyraźnie różne od tego, co już tam jest, poprzez porównywanie podobieństw instrukcji i wygenerowanych przez nie dialogów. Te kandydackie instrukcje są następnie klastrowane za pomocą algorytmu K-means, a reprezentatywne z każdego klastra wybierane są do odświeżenia puli instrukcji. W miarę kolejnych rund udział promptów napisanych przez ludzi stopniowo maleje, podczas gdy starannie wybrane, maszynowo wygenerowane promptu przejmują, utrzymując różnorodność bez utraty zgodności z zasadami MCT.
Jak dobry jest powstały zbiór rozmów medycznych?
Aby przetestować swoje podejście, autorzy użyli ChatGPT (gpt-3.5-turbo) jako głównego generatora oraz wyspecjalizowanego modelu medycznego ZuoYi do pomocy przy weryfikacji treści medycznych. Iterowali ten proces 40 razy, łącząc automatyczne filtry z przeglądem ekspertów ludzkich, i ostatecznie zbudowali zbiór danych o nazwie MCT-Chat z około 20 000 wieloturowych dialogów. Zespół porównał MCT-Chat ze znanymi, rzeczywistymi chińskimi zbiorami dialogów medycznych, takimi jak MedDialog, MedDG i DISC-Med-SFT. Miary obiektywne wykazały, że MCT-Chat ma bardzo silną różnorodność leksykalną i bogactwo formułowań, jednocześnie skupiając się na ukierunkowanym zestawie chorób i objawów odpowiednich dla warunków egzaminu. Zawiera też szeroki zakres ról rozmówców, tematów i zadań, a jego typowa długość i liczba tur dobrze odpowiadają oczekiwaniom MCT.
Oceny ekspertów i kierunki rozwoju
Pięciu ekspertów medycznych oceniło losowe próbki z MCT-Chat i z porównawczych zbiorów. Punktowali płynność, bezstronność, poprawność medyczną, dopasowanie do wymagań MCT oraz zdolność do rozróżniania różnych poziomów biegłości. MCT-Chat wypadł porównywalnie lub nieco lepiej niż zbiory rzeczywiste w większości kryteriów, zwłaszcza pod względem racjonalności i zdolności do różnicowania poziomów, co sugeruje, że dane syntetyczne mogą być poważnymi kandydatami na materiały egzaminacyjne — choć autorzy podkreślają, że wszelkie rzeczywiste zadania egzaminacyjne muszą nadal przejść rygorystyczną weryfikację ręczną. Zauważają też pozostałe wyzwania: modele językowe wciąż mogą błędnie interpretować trudne tematy, a długie dialogi mogą popadać w powtarzalność bez ostrożnej kontroli. Autorzy proponują ulepszenie etapu klastrowania, włączenie bardziej zaawansowanych aktualizacji wiedzy oraz rozszerzenie ram na ustawienia wielojęzyczne i wielokulturowe, aby podobne, zgodne z egzaminami zbiory dialogów medycznych można było budować na całym świecie.
Wniosek dla czytelników niebędących specjalistami
Badanie pokazuje, że przy odpowiednich zabezpieczeniach i inteligentnych strategiach próbkowania duże modele językowe mogą pomóc tworzyć realistyczne, bezpieczne pod względem prywatności rozmowy medyczne dopasowane do konkretnego egzaminu językowego. Poprzez łączenie oficjalnych wytycznych, automatycznych filtrów i przeglądu ekspertów, autorzy zbudowali zbiór 20 000 dialogów, który ściśle odpowiada Medical Chinese Test. Dla pacjentów i uczących się oznacza to, że przyszli lekarze mogą być szkoleni i oceniani przy użyciu syntetycznych, lecz wiarygodnych dialogów, co zmniejsza zależność od wrażliwych danych rzeczywistych, a jednocześnie przygotowuje ich do autentycznej komunikacji szpitalnej.
Cytowanie: Zhou, H., Hu, X., He, T. et al. LLM-based medical dialogue dataset generation with automated instructions. Sci Rep 16, 12410 (2026). https://doi.org/10.1038/s41598-025-34835-1
Słowa kluczowe: syntetyczne rozmowy medyczne, duże modele językowe, chiński test medyczny, generowanie instrukcji, edukacja języka medycznego