Clear Sky Science · it
Generazione di dataset di dialoghi medici basati su LLM con istruzioni automatizzate
Perché i dialoghi medici sintetici sono importanti
Gli ospedali sono pieni di conversazioni: medici che interrogano i pazienti, infermieri che spiegano trattamenti e colleghi che discutono diagnosi. Questi colloqui sono fondamentali per l’assistenza, ma sono difficili da registrare e condividere a causa delle leggi sulla privacy e della natura sensibile delle informazioni sanitarie. Allo stesso tempo, gli studenti internazionali che vogliono lavorare negli ospedali cinesi devono superare il Medical Chinese Test (MCT), che richiede dialoghi medici realistici a più turni. Questo articolo descrive un metodo per usare modelli linguistici di grandi dimensioni — sistemi come ChatGPT — per creare automaticamente una raccolta ricca, sicura e pronta per l’esame di conversazioni mediche in cinese.
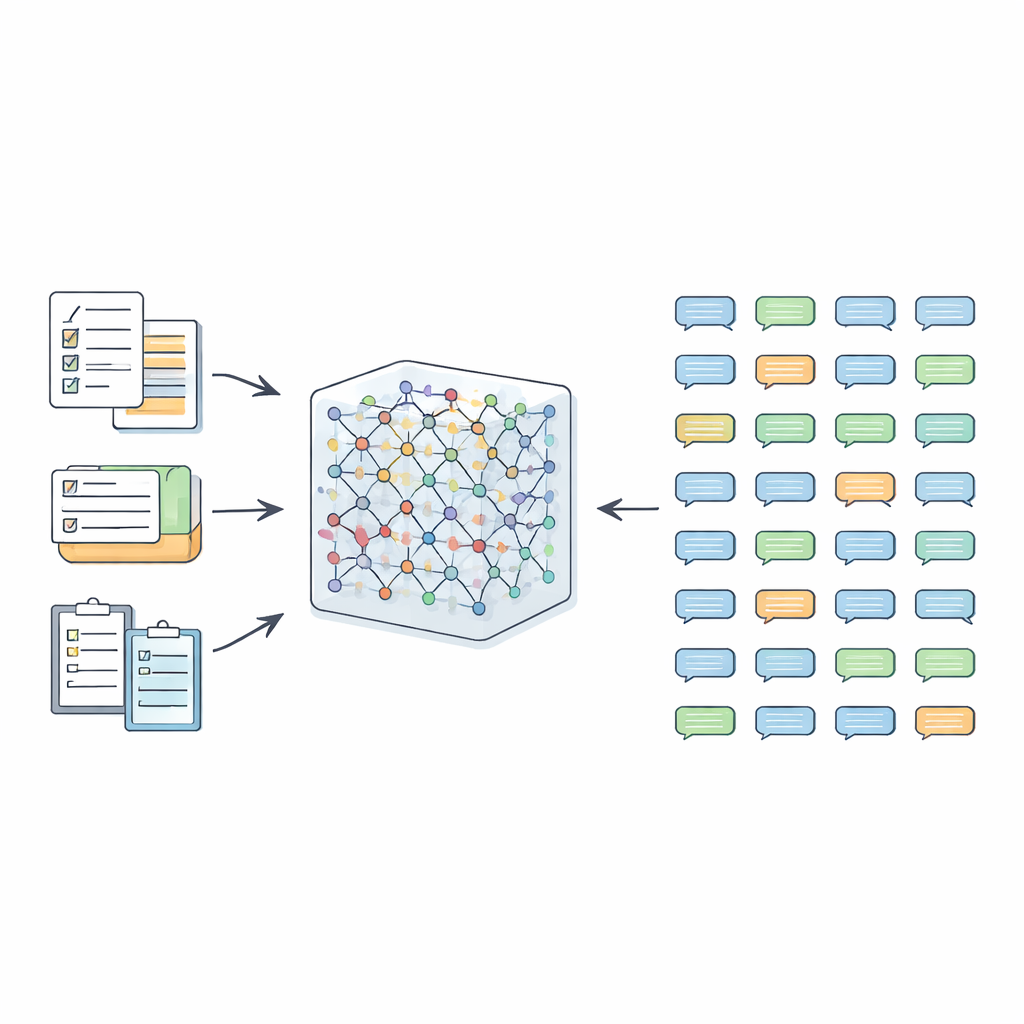
Costruire dati utili senza coinvolgere pazienti reali
Gli autori affrontano un problema chiave: come ottenere dati di dialoghi medici di alta qualità per l’addestramento e la valutazione delle competenze linguistiche senza esporre informazioni sui pazienti reali. I normali dataset di chat pubblici non corrispondono alla complessità, alla professionalità o alle regole etiche degli incontri medici reali. I dialoghi medici sono lunghi, strettamente collegati su molti turni e devono rispettare schemi di ruolo rigorosi — medici che parlano in termini professionali, pazienti che usano descrizioni quotidiane e infermieri che coordinano le cure. Inoltre, l’MCT ha linee guida ufficiali che specificano quali argomenti, compiti e vocaboli devono comparire. Chiedere semplicemente a un modello linguistico di “inventare” dialoghi spesso produce contenuti irrealistici o non conformi, perciò il team progetta un quadro strutturato per indirizzare la generazione.
Dai prompt artigianali a un pool di istruzioni in evoluzione
Il framework, chiamato AIG-MCT, parte da un piccolo insieme di istruzioni artigianali che funzionano come prompt dettagliati per il modello linguistico. Ogni istruzione descrive chi parla (medico, paziente, infermiere), lo scenario medico (per esempio, ambulatorio pediatrico o pronto soccorso), il compito (anamnesi, diagnosi, discussione del trattamento, consigli di prevenzione), il numero desiderato di turni del dialogo e una lunghezza approssimativa. Queste istruzioni iniziali sono costruite con cura dal programma di lavoro dell’MCT, dalla lista di argomenti e dal vocabolario medico ufficiale, e richiedono che i dialoghi risultanti restino in contesti medici realistici e raggiungano livelli di complessità adeguati ai candidati MCT.
Filtraggio, valutazione e campionamento intelligente per la diversità
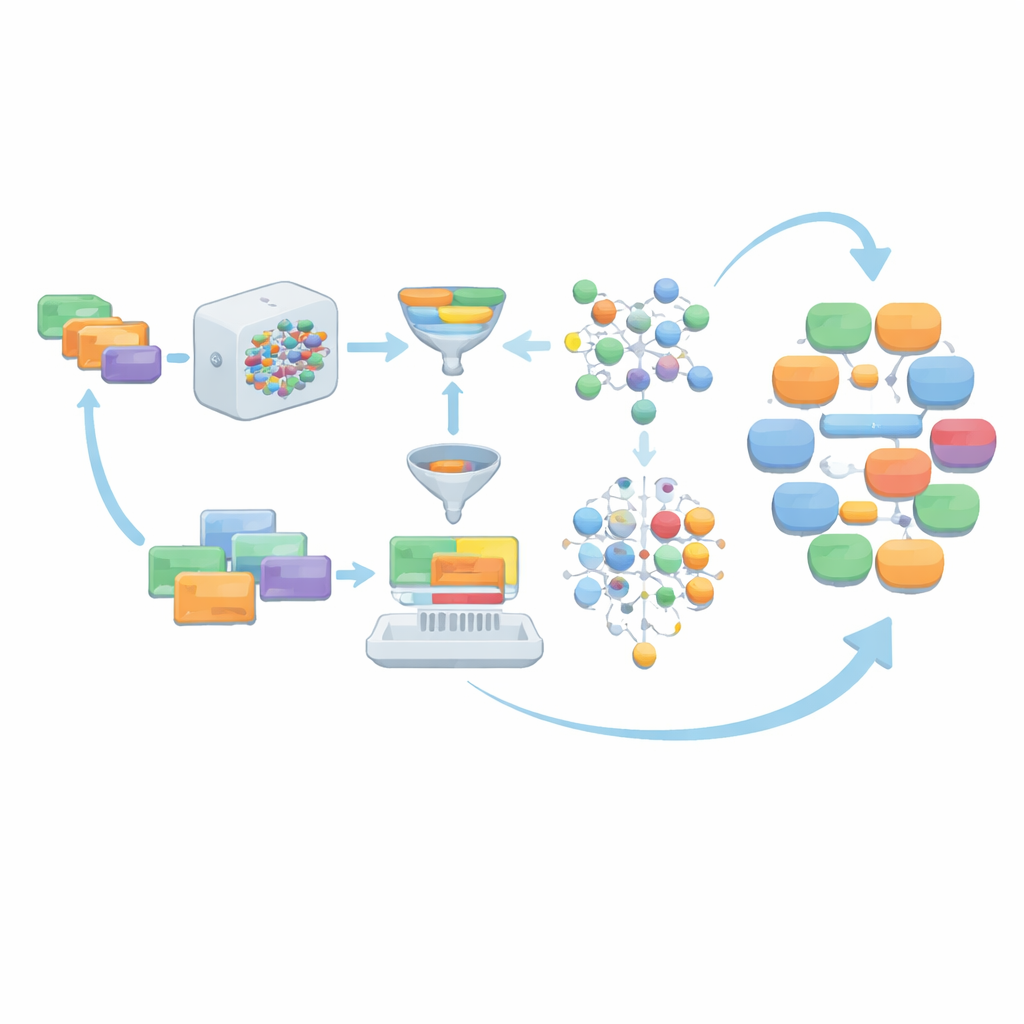
Quando il modello genera dialoghi a partire da queste istruzioni, l’output grezzo non viene accettato così com’è. Invece, passa attraverso diversi livelli di pulizia. Materiale non dialogico, come elenchi di tipo cartella clinica o dati strutturati, viene rimosso. I ruoli dei parlanti sono standardizzati in quattro principali tipi di relazione — medico–paziente, medico–infermiere, medico–medico e paziente–infermiere — per allinearsi alle esigenze dell’MCT. Il team verifica quindi se ogni dialogo utilizza un numero sufficiente di parole del vocabolario medico ufficiale dell’MCT, se raggiunge un minimo di turni e se la sua lunghezza rientra in un intervallo scelto con cura. Strumenti opzionali di correzione grammaticale perfezionano ulteriormente il linguaggio. I dialoghi che non superano questi controlli, insieme alle istruzioni sottostanti, vengono scartati in modo che rimangano solo esempi di qualità.
Lasciare che il modello aiuti a scrivere prompt migliori
Invece di affidarsi per sempre ai prompt iniziali scritti da umani, AIG-MCT permette al sistema di apprendere nuove istruzioni dai propri output. Al modello linguistico si chiede non solo di produrre dialoghi, ma anche di proporre nuove istruzioni generate dalla macchina. Una tecnica chiamata Massima Rilevanza Marginale (Maximal Marginal Relevance) viene usata per selezionare istruzioni che siano sia rilevanti rispetto al pool esistente sia chiaramente diverse da quelle già presenti, confrontando la similarità tra le istruzioni e i dialoghi che esse generano. Queste istruzioni candidate vengono poi raggruppate con l’algoritmo K-means, e vengono scelte rappresentanti da ciascun cluster per rinnovare il pool di istruzioni. Nel corso di molte iterazioni, la quota di prompt scritti da umani diminuisce gradualmente, mentre prompt generati automaticamente ma selezionati con cura prendono il loro posto, mantenendo la diversità senza perdere l’allineamento con le regole dell’MCT.
Quanto è buona la raccolta di dialoghi medici risultante?
Per testare l’approccio, gli autori hanno usato ChatGPT (gpt-3.5-turbo) come generatore principale e un modello linguistico medico specializzato, ZuoYi, per aiutare a verificare i contenuti medici. Hanno iterato questo processo 40 volte, combinando filtri automatici con revisione di esperti umani, e hanno infine costruito un dataset chiamato MCT-Chat con circa 20.000 dialoghi multi-turno. Il team ha confrontato MCT-Chat con noti dataset di dialoghi medici in cinese del mondo reale come MedDialog, MedDG e DISC-Med-SFT. Misure oggettive hanno mostrato che MCT-Chat possiede una forte diversità lessicale e ricchezza di formulazioni, pur concentrandosi su un set mirato di malattie e sintomi appropriati per un contesto d’esame. Copre anche un’ampia gamma di ruoli, argomenti e compiti dialogici, e la sua lunghezza tipica e il numero di turni corrispondono bene alle aspettative dell’MCT.
Valutazioni di esperti e direzioni future
Cinque esperti medici hanno valutato campioni casuali estratti da MCT-Chat e dai dataset di confronto. Hanno valutato fluidità, responsabilità, fondatezza medica, corrispondenza con i requisiti MCT e la capacità di distinguere diversi livelli di competenza. MCT-Chat ha ottenuto punteggi pari o leggermente superiori rispetto ai dataset del mondo reale sulla maggior parte dei criteri, in particolare nella razionalità e nella discriminazione per la valutazione, suggerendo che i dati sintetici possono essere candidati seri per materiali d’esame — anche se gli autori sottolineano che qualsiasi item d’esame effettivo deve comunque essere sottoposto a un rigoroso controllo manuale. Segnalano inoltre sfide residue: i modelli linguistici possono ancora interpretare male argomenti complessi e i dialoghi lunghi possono degenerare in ripetizioni senza un controllo attento. Gli autori propongono di migliorare la fase di clustering, incorporare aggiornamenti di conoscenza più avanzati ed estendere il framework a contesti multilingue e multiculturali in modo che dataset di dialoghi medici allineati agli esami possano essere costruiti in tutto il mondo.
Messaggio principale per i non specialisti
Questo studio mostra che, con le giuste salvaguardie e strategie di campionamento intelligenti, i modelli linguistici di grandi dimensioni possono contribuire a creare conversazioni mediche realistiche e rispettose della privacy, su misura per un esame linguistico specifico. Mescolando linee guida ufficiali, filtri automatici e revisione di esperti, gli autori costruiscono un dataset di 20.000 dialoghi che segue da vicino il Medical Chinese Test. Per pazienti e studenti, l’implicazione è che i futuri medici potrebbero allenarsi e essere valutati usando dialoghi sintetici ma credibili, riducendo la dipendenza da dati sensibili del mondo reale pur preparandoli alla comunicazione autentica in ospedale.
Citazione: Zhou, H., Hu, X., He, T. et al. LLM-based medical dialogue dataset generation with automated instructions. Sci Rep 16, 12410 (2026). https://doi.org/10.1038/s41598-025-34835-1
Parole chiave: dialoghi medici sintetici, modelli linguistici di grandi dimensioni, test di cinese medico, generazione di istruzioni, educazione al linguaggio medico