Clear Sky Science · pt
Geração de conjuntos de diálogo médico baseada em LLM com instruções automatizadas
Por que conversas médicas sintéticas são importantes
Hospitais estão cheios de conversas: médicos interrogando pacientes, enfermeiros explicando tratamentos e colegas debatendo diagnósticos. Essas interações são vitais para o cuidado, mas são difíceis de gravar e compartilhar por causa de leis de privacidade e da natureza sensível das informações de saúde. Ao mesmo tempo, estudantes internacionais que desejam trabalhar em hospitais chineses precisam passar no Medical Chinese Test (MCT), que exige diálogos médicos realistas com múltiplas trocas. Este artigo descreve uma forma de usar grandes modelos de linguagem — sistemas como o ChatGPT — para criar automaticamente uma coleção rica, segura e pronta para exames de conversas médicas em chinês.
Construindo dados úteis sem envolver pacientes reais
Os autores enfrentam um problema central: como obter dados de diálogo médico de alta qualidade para treinar e testar habilidades linguísticas sem expor informações reais de pacientes. Conjuntos de conversas públicos comuns não correspondem à complexidade, ao profissionalismo ou às regras éticas de encontros médicos reais. Conversas médicas são longas, fortemente conectadas ao longo de muitas falas e devem respeitar padrões de papéis rígidos — médicos falando em termos profissionais, pacientes usando descrições do dia a dia e enfermeiros coordenando o cuidado. Além disso, o MCT tem suas próprias diretrizes oficiais que especificam quais tópicos, tarefas e vocabulário devem aparecer. Pedir simplesmente a um modelo de linguagem que “invente” diálogos frequentemente produz conteúdo irrealista ou fora do padrão, então a equipe desenha uma estrutura organizada para orientar a geração.
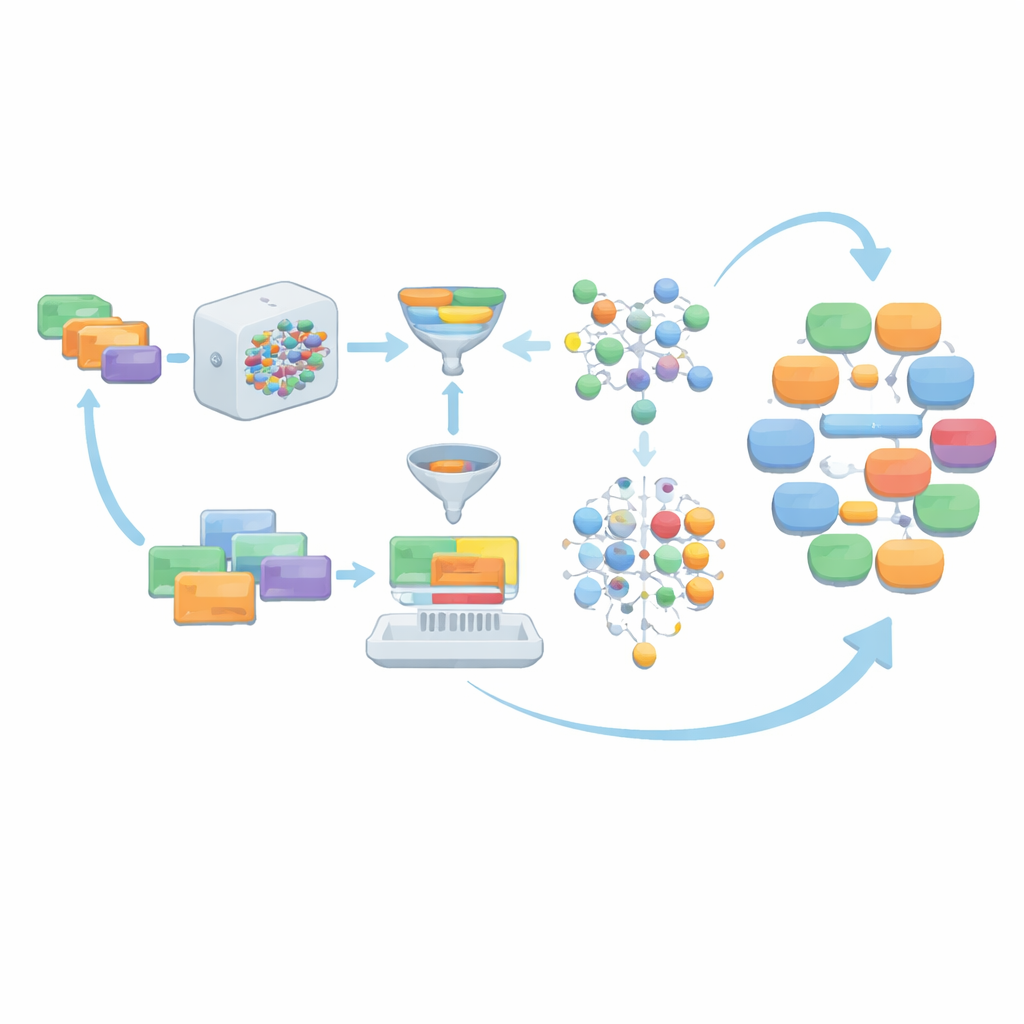
De prompts elaborados à uma piscina de instruções em evolução
A estrutura, chamada AIG-MCT, começa com um pequeno conjunto de instruções feitas manualmente que funcionam como prompts detalhados para o modelo de linguagem. Cada instrução descreve quem está falando (médico, paciente, enfermeiro), o cenário médico (por exemplo, clínica pediátrica ou emergência), a tarefa (anamnese, diagnóstico, discussão de tratamento, aconselhamento preventivo), o número desejado de turnos do diálogo e um comprimento aproximado. Essas instruções iniciais são cuidadosamente construídas a partir do esboço de tarefas do MCT, da lista de tópicos e do vocabulário médico oficial, e exigem que as conversas resultantes permaneçam dentro de cenários médicos realistas e atendam a níveis de complexidade específicos adequados aos candidatos ao MCT.
Filtragem, pontuação e amostragem inteligente para diversidade
Quando o modelo de linguagem gera diálogos a partir dessas instruções, a saída bruta não é aceita como está. Em vez disso, passa por várias camadas de limpeza. Materiais não dialogais, como listas em estilo de registro ou dados estruturados, são removidos. Os papéis dos falantes são padronizados em quatro tipos principais de relação — médico–paciente, médico–enfermeiro, médico–médico e paciente–enfermeiro — para corresponder às necessidades do MCT. A equipe então verifica se cada diálogo usa palavras suficientes do vocabulário médico oficial do MCT, se atinge um número mínimo de turnos e se seu comprimento está dentro de uma faixa cuidadosamente escolhida. Ferramentas opcionais de correção gramatical aprimoram ainda mais a linguagem. Diálogos que não passam por essas checagens, junto com suas instruções subjacentes, são descartados para que apenas exemplos robustos permaneçam.
Deixando o modelo ajudar a escrever melhores prompts
Em vez de depender indefinidamente dos prompts iniciais escritos por humanos, o AIG-MCT permite que o sistema aprenda novas instruções a partir de suas próprias saídas. Pede‑se ao modelo de linguagem não apenas para produzir diálogos, mas também para propor novas instruções geradas por máquina. Uma técnica chamada Maximal Marginal Relevance é usada para selecionar instruções que são relevantes para a piscina existente e claramente diferentes do que já está lá, comparando a similaridade entre as instruções e os diálogos resultantes. Essas instruções candidatas são então agrupadas usando o algoritmo K-means, e representantes de cada cluster são escolhidos para renovar a piscina de instruções. Ao longo de várias rodadas, a parcela de prompts escritos por humanos é gradualmente reduzida, enquanto prompts gerados por máquina cuidadosamente selecionados assumem, mantendo a diversidade sem perder alinhamento com as regras do MCT.
Quão boa é a coleção de diálogos médicos resultante?
Para testar sua abordagem, os autores usaram o ChatGPT (gpt-3.5-turbo) como gerador principal e um modelo de linguagem médica especializado, ZuoYi, para ajudar a checar o conteúdo médico. Iteraram esse processo 40 vezes, combinando filtros automatizados com revisão humana por especialistas, e construíram finalmente um conjunto de dados chamado MCT-Chat com cerca de 20.000 diálogos multi-turno. A equipe comparou o MCT-Chat com conjuntos de diálogo médico chineses do mundo real bem conhecidos, como MedDialog, MedDG e DISC-Med-SFT. Medidas objetivas mostraram que o MCT-Chat tem uma diversidade lexical muito forte e formulações ricas, ao mesmo tempo em que foca em um conjunto direcionado de doenças e sintomas apropriado para um cenário de exame. Também cobre uma ampla gama de papéis, tópicos e tarefas de diálogo, e seu comprimento típico e número de turnos estão bem alinhados com as expectativas do MCT.
Julgamentos de especialistas e direções futuras
Cinco especialistas médicos avaliaram amostras aleatórias do MCT-Chat e dos conjuntos de comparação. Eles pontuaram fluência, imparcialidade, solidez médica, conformidade com os requisitos do MCT e a capacidade de distinguir diferentes níveis de proficiência. O MCT-Chat teve desempenho equivalente ou ligeiramente melhor do que os conjuntos do mundo real na maioria dos critérios, especialmente em racionalidade e discriminação por nível de conhecimento, sugerindo que dados sintéticos podem ser candidatos sérios para materiais de exame — embora os autores ressaltem que quaisquer itens de teste reais ainda devem passar por uma rigorosa validação manual. Eles também observam desafios remanescentes: modelos de linguagem ainda podem interpretar mal tópicos complicados, e diálogos longos podem degenerar em repetição sem controle cuidadoso. Os autores propõem melhorar a etapa de clusterização, incorporar atualizações de conhecimento mais avançadas e estender a estrutura para cenários multilíngues e multiculturais para que conjuntos de diálogo médico alinhados a exames possam ser construídos ao redor do mundo.
Mensagem principal para não especialistas
Este estudo mostra que, com salvaguardas adequadas e estratégias de amostragem inteligentes, grandes modelos de linguagem podem ajudar a criar conversas médicas realistas e seguras em termos de privacidade, adaptadas a um exame linguístico específico. Ao misturar diretrizes oficiais, filtros automáticos e revisão por especialistas, os autores construíram um conjunto de dados de 20.000 diálogos que segue de perto o Medical Chinese Test. Para pacientes e aprendizes, a implicação é que futuros médicos podem treinar e ser avaliados usando diálogos sintéticos, porém críveis, reduzindo a dependência de dados sensíveis do mundo real enquanto ainda se preparam para a comunicação autêntica em hospitais.
Citação: Zhou, H., Hu, X., He, T. et al. LLM-based medical dialogue dataset generation with automated instructions. Sci Rep 16, 12410 (2026). https://doi.org/10.1038/s41598-025-34835-1
Palavras-chave: diálogo médico sintético, grandes modelos de linguagem, teste de chinês médico, geração de instruções, educação em linguagem médica