Clear Sky Science · ar
توليد مجموعة بيانات حوارية طبية باستخدام نماذج لغوية كبيرة وتعليمات مؤتمتة
لماذا تهم المحادثات الطبية الاصطناعية
المستشفيات غنية بالمحادثات: أطباء يستقصون عن المرضى، وممرضات يشرحْن العلاج، وزملاء يناقشون التشخيصات. هذه الحوارات حيوية للرعاية، لكنها يصعب تسجيلها ومشاركتها بسبب قوانين الخصوصية وحساسية المعلومات الصحية. وفي الوقت نفسه، يجب على الطلاب الدوليين الراغبين في العمل بالمستشفيات الصينية اجتياز اختبار اللغة الطبية الصينية (MCT)، الذي يطلب حوارات طبية متعددة اللفات وواقعية. يصف هذا البحث طريقة لاستخدام نماذج لغوية كبيرة—أنظمة مثل ChatGPT—لإنشاء مجموعة غنية وآمنة ومناسبة للامتحانات من المحادثات الطبية بالصينية بشكل آلي.
بناء بيانات مفيدة دون المساس بالمرضى الحقيقيين
يتصدى المؤلفون لمشكلة رئيسية: كيفية الحصول على كمية كافية من بيانات الحوار الطبي عالية الجودة لتدريب واختبار مهارات اللغة دون كشف معلومات المرضى الحقيقية. مجموعات البيانات العامة مجردة عادةً لا تطابق تعقيد أو مهنية أو قواعد الأخلاقيات في اللقاءات الطبية الواقعية. الحوارات الطبية طويلة ومرتبطة عبر عدة لِفات، ويجب احترام أنماط أدوار صارمة—الأطباء يتكلمون بمصطلحات مهنية، والمرضى بوصف يومي، والممرضات ينسقن الرعاية. بالإضافة إلى ذلك، لدى MCT إرشادات رسمية تحدد المواضيع والمهام والمفردات المطلوبة. مجرد مطالبة نموذج لغوي «بتأليف» حوارات غالباً ما تنتج محتوى غير واقعي أو خارج المعايير، لذا صمّم الفريق إطاراً منظماً لتوجيه التوليد.
من تعليمات مكتوبة يدوياً إلى مجموعة تعليمات متطورة
الإطار، المسمى AIG-MCT، يبدأ بمجموعة صغيرة من التعليمات المصمَّمة يدوياً التي تعمل كمطالبات مفصّلة للنموذج اللغوي. كل تعليمات تصف من يتحدث (طبيب، مريض، ممرضة)، السيناريو الطبي (مثل عيادة أطفال أو غرفة طوارئ)، المهمة (أخذ التاريخ المرضي، التشخيص، مناقشة العلاج، نصائح وقائية)، عدد دورات المحادثة المرغوب فيها والطول التقريبي. تم بناء هذه التعليمات الأولية بعناية من مخطط مهام MCT وقائمة الموضوعات والمفردات الطبية الرسمية، وتطلب أن تظل الحوارات الناتجة ضمن سياقات طبية واقعية وتصل إلى مستويات تعقيد محددة مناسبة لمرشحي MCT.
تنقية، تسجيل نقاط، وعينات ذكية من أجل التنوع
عندما يُنتج النموذج اللغوي حوارات من هذه التعليمات، لا يُقبل النص الخام كما هو. بل يمر عبر عدة طبقات من التنظيف. تُزال المواد غير الحوارية، مثل القوائم المشابهة للسجلات أو البيانات المهيكلة. تُوحَّد أدوار المتحدثين إلى أربعة أنواع رئيسية—طبيب–مريض، طبيب–ممرضة، طبيب–طبيب، ومريض–ممرضة—لتتوافق مع احتياجات MCT. ثم يتحقق الفريق مما إذا كانت كل حوار يستخدم عدداً كافياً من كلمات المفردات الطبية الرسمية لـMCT، وما إذا وصل إلى حد أدنى من الدوران، وما إذا كان طوله ضمن نطاق محدد بعناية. أدوات تصحيح القواعد الاختيارية تُلمّع اللغة أكثر. تُرفض الحوارات التي تفشل في هذه الفحوصات، مع تعليماتها الأساسية، بحيث تبقى أمثلة قوية فقط.
السماح للنموذج بمساعدة كتابة مطالبات أفضل
بدلاً من الاعتماد الدائم على المطالبات المكتوبة بشرياً، يسمح AIG-MCT للنظام بتعلّم تعليمات جديدة من مخرجاته ذاتها. يُطلب من النموذج اللغوي ليس فقط إنتاج الحوارات بل اقتراح تعليمات مولّدة آلياً. تُستخدم تقنية تسمى الصلة الحدّية القصوى (Maximal Marginal Relevance) لاختيار تعليمات تكون ذات صلة بمجموعة التعليمات الحالية ومختلفة بوضوح عما هو موجود، عبر مقارنة مدى تشابه التعليمات والحوارات الناتجة عنها. تُجمَّع هذه التعليمات المرشحة باستخدام خوارزمية K-means، ويُختار ممثلون من كل مجموعة لتحديث مجموعة التعليمات. عبر جولات متعددة، يتناقص سهم المطالبات المكتوبة يدويًا تدريجياً، بينما تتولى مطالبات مولّدة بعناية من الآلة المهمة، محافظةً على التنوع دون فقدان التوافق مع قواعد MCT.
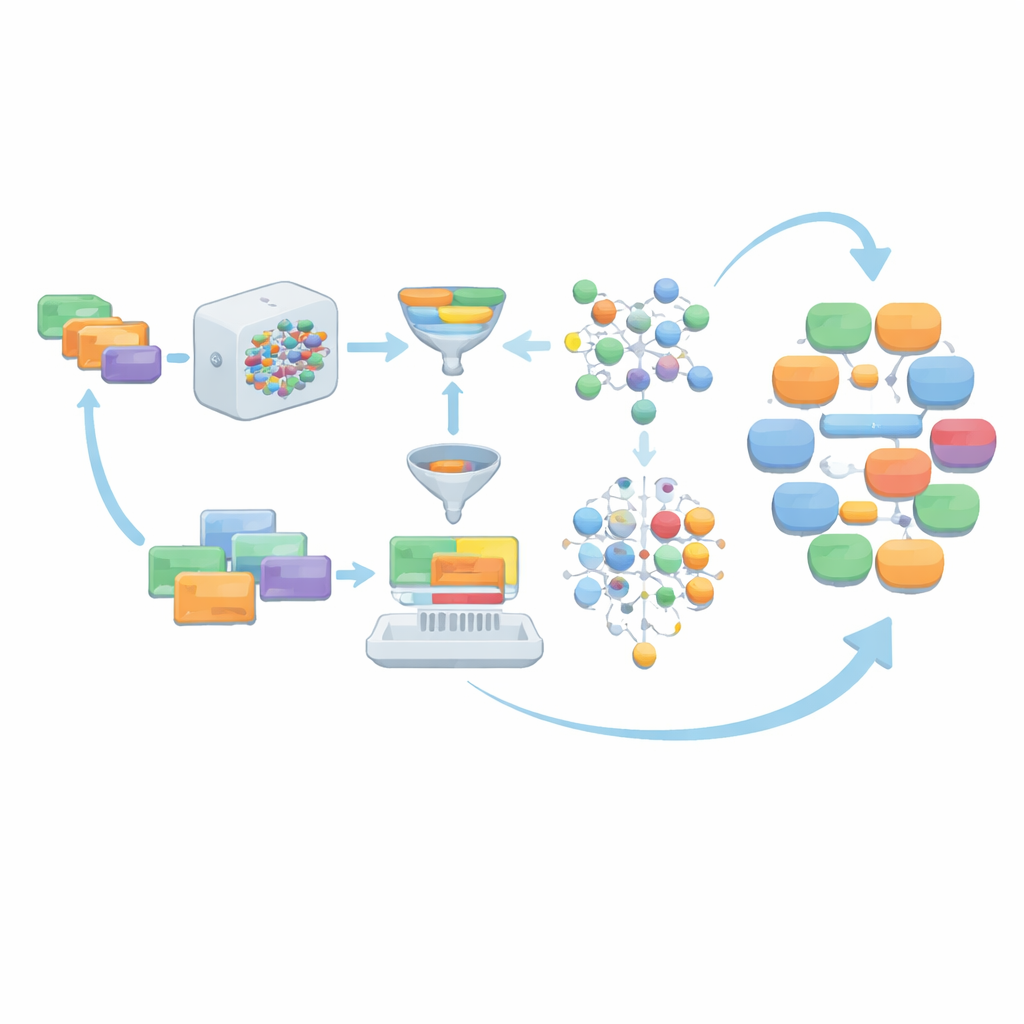
ما جودة مجموعة المحادثات الطبية الناتجة؟
لاختبار المنهج، استخدم المؤلفون ChatGPT (gpt-3.5-turbo) كمولّد رئيسي ونموذج لغة طبية متخصص، ZuoYi، للمساعدة في مراجعة المحتوى الطبي. كرروا هذه العملية 40 مرة، ممزوجة بمرشحات آلية ومراجعة خبراء بشرية، وأنشأوا أخيراً مجموعة بيانات اسمها MCT-Chat تضم حوالي 20,000 حوار متعدد اللفات. قارن الفريق MCT-Chat بمجموعات بيانات حوارية طبية صينية معروفة في العالم الحقيقي مثل MedDialog وMedDG وDISC-Med-SFT. أظهرت المقاييس الموضوعية أن MCT-Chat تتميز بتنوع معجمي قوي وثراء في الصياغة، بينما تظل مركزة على مجموعة مستهدفة من الأمراض والأعراض المناسبة لسياق الامتحان. كما تغطي نطاقاً واسعاً من الأدوار والمواضيع والمهام الحوارية، ويطابق طولها وعدد لفاتها المتوقعات في MCT.
أحكام الخبراء والاتجاهات المستقبلية
قيّم خمسة خبراء طبيون عينات عشوائية من MCT-Chat ومن مجموعات المقارنة. قيّموا الطلاقة، والحياد، والسلامة الطبية، والتوافق مع متطلبات MCT، والقدرة على التمييز بين مستويات الكفاءة المختلفة. سجلت MCT-Chat نتائج متكافئة أو أفضل قليلاً من مجموعات العالم الحقيقي في معظم المعايير، خاصة في المعقولية والتمييز للتقدير، ما يشير إلى أن البيانات الاصطناعية يمكن أن تكون مرشحة جادة لاستخدامها في مواد الامتحانات—مع تأكيد المؤلفين على ضرورة مرور أي عناصر اختبار فعلية بمراجعة يدوية صارمة. كما يشيرون إلى تحديات باقية: نماذج اللغة لا تزال قد تسئ تفسير مواضيع معقّدة، والحوارات الطويلة قد تنهار إلى تكرار دون تحكم دقيق. يقترح المؤلفون تحسين خطوة التجميع، وإدماج تحديثات معرفية متقدمة أكثر، وتوسيع الإطار إلى إعدادات متعددة اللغات والثقافات بحيث يمكن بناء مجموعات بيانات حوارية طبية موائمة للامتحانات في أنحاء العالم.
النتيجة الأساسية لغير المتخصصين
تُظهر هذه الدراسة أنه، مع الضمانات الصحيحة واستراتيجيات أخذ عينات ذكية، يمكن لنماذج اللغة الكبيرة أن تساعد في إنشاء محادثات طبية واقعية وآمنة من حيث الخصوصية ومصممة لامتحان لغوي محدد. من خلال مزج الإرشادات الرسمية والمرشحات الآلية والمراجعة الخبيرة، بنى المؤلفون مجموعة بيانات مكونة من 20,000 حوار تتبع عن كثب اختبار اللغة الطبية الصينية. للمرضى والمتعلمين على حد سواء، يعني ذلك أن الأطباء المستقبليين قد يتدرّبون ويُقَيَّمون باستخدام حوارات اصطناعية موثوقة، مما يقلل الاعتماد على بيانات العالم الحقيقي الحساسة مع إعدادهم للتواصل المستند إلى الواقع في المستشفى.
الاستشهاد: Zhou, H., Hu, X., He, T. et al. LLM-based medical dialogue dataset generation with automated instructions. Sci Rep 16, 12410 (2026). https://doi.org/10.1038/s41598-025-34835-1
الكلمات المفتاحية: حوار طبي اصطناعي, نماذج لغوية كبيرة, اختبار اللغة الطبية الصينية, توليد التعليمات, تعليم اللغة الطبية