Clear Sky Science · es
Generación de conjuntos de datos de diálogos médicos basados en LLM con instrucciones automatizadas
Por qué importan los chats médicos sintéticos
Los hospitales están llenos de conversaciones: médicos interrogando a pacientes, enfermeras explicando tratamientos y colegas debatiendo diagnósticos. Estas charlas son vitales para la atención, pero son difíciles de grabar y compartir debido a las leyes de privacidad y a la naturaleza sensible de la información sanitaria. Al mismo tiempo, los estudiantes internacionales que desean trabajar en hospitales chinos deben aprobar el Examen de Chino Médico (MCT), que exige diálogos médicos realistas de múltiples turnos. Este artículo describe una forma de usar modelos de lenguaje a gran escala—sistemas como ChatGPT—para crear automáticamente una colección rica, segura y lista para exámenes de conversaciones médicas en chino.
Construir datos útiles sin tocar pacientes reales
Los autores abordan un problema clave: cómo obtener suficientes datos de diálogo médico de alta calidad para entrenar y evaluar habilidades lingüísticas sin exponer información real de pacientes. Los conjuntos de datos públicos ordinarios no coinciden con la complejidad, el profesionalismo ni las normas éticas de los encuentros médicos reales. Las conversaciones médicas son largas, están fuertemente conectadas a lo largo de muchos turnos y deben respetar patrones de rol estrictos: médicos que hablan en términos profesionales, pacientes que usan descripciones cotidianas y enfermeras que coordinan la atención. Además, el MCT tiene sus propias directrices oficiales que especifican qué temas, tareas y vocabulario deben aparecer. Pedir simplemente a un modelo de lenguaje que “invente” diálogos suele producir contenido poco realista o fuera de estándar, por lo que el equipo diseña un marco estructurado para orientar la generación.
De prompts hechos a mano a una reserva de instrucciones en evolución
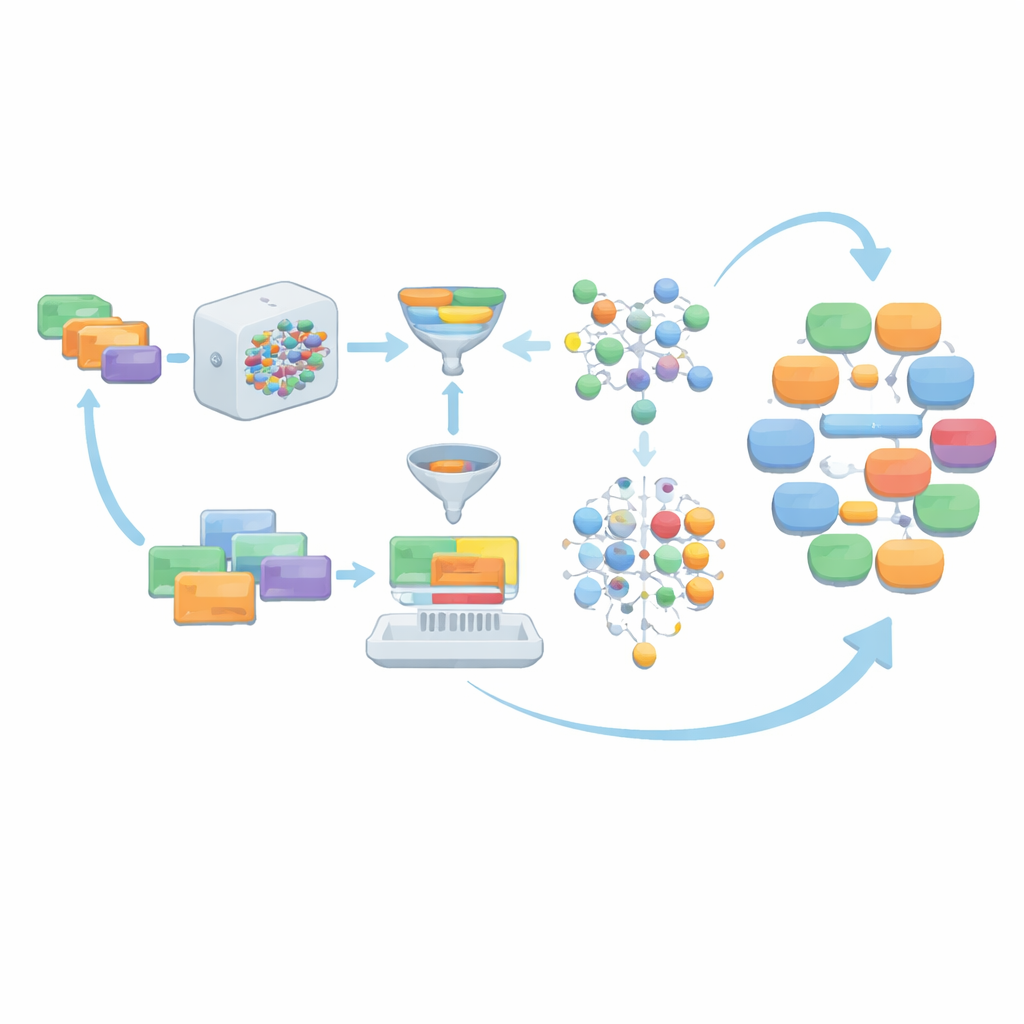
El marco, llamado AIG-MCT, comienza con un pequeño conjunto de instrucciones elaboradas a mano que actúan como prompts detallados para el modelo de lenguaje. Cada instrucción describe quién habla (médico, paciente, enfermera), el escenario médico (por ejemplo, una consulta pediátrica o urgencias), la tarea (anamnesis, diagnóstico, discusión del tratamiento, consejos de prevención), el número deseado de turnos de diálogo y una longitud aproximada. Estas instrucciones semilla se construyen cuidadosamente a partir del esquema de tareas del MCT, la lista de temas y el vocabulario médico oficial, y requieren que las conversaciones resultantes se mantengan en entornos médicos realistas y cumplan niveles de complejidad específicos adecuados para los candidatos del MCT.
Filtrado, puntuación y muestreo inteligente para diversidad
Cuando el modelo de lenguaje genera diálogos a partir de estas instrucciones, la salida cruda no se acepta tal cual. En cambio, pasa por varias capas de limpieza. Se elimina material no dialogado, como listas tipo registro o datos estructurados. Los roles de los hablantes se estandarizan en cuatro tipos de relación principales—médico–paciente, médico–enfermera, médico–médico y paciente–enfermera—para ajustarse a las necesidades del MCT. El equipo comprueba entonces si cada diálogo utiliza suficientes términos del vocabulario médico oficial del MCT, si alcanza un número mínimo de turnos y si su longitud se encuentra dentro de un rango cuidadosamente elegido. Herramientas opcionales de corrección gramatical pulen aún más el lenguaje. Los diálogos que no superan estas comprobaciones, junto con sus instrucciones subyacentes, se descartan para que sólo queden ejemplos sólidos.
Permitir que el modelo ayude a escribir mejores prompts
En lugar de depender para siempre de los prompts iniciales escritos por humanos, AIG-MCT permite que el sistema aprenda nuevas instrucciones a partir de sus propias salidas. Se pide al modelo de lenguaje no solo que produzca diálogos, sino también que proponga nuevas instrucciones generadas por máquina. Se utiliza una técnica llamada Relevancia Marginal Máxima (Maximal Marginal Relevance) para seleccionar instrucciones que sean a la vez relevantes para la reserva existente y claramente diferentes de lo ya presente, comparando la similitud entre las instrucciones y los diálogos que generan. Estas instrucciones candidatas se agrupan luego mediante el algoritmo K-means, y se eligen representantes de cada grupo para renovar la reserva de instrucciones. A lo largo de muchas rondas, la proporción de prompts escritos por humanos se reduce gradualmente, mientras que prompts generados por máquina cuidadosamente seleccionados toman el relevo, manteniendo la diversidad sin perder alineamiento con las reglas del MCT.
¿Qué tan buena es la colección de chats médicos resultante?
Para probar su enfoque, los autores usaron ChatGPT (gpt-3.5-turbo) como generador principal y un modelo de lenguaje médico especializado, ZuoYi, para ayudar a comprobar el contenido médico. Iteraron este proceso 40 veces, combinando filtros automatizados con revisión experta humana, y en última instancia construyeron un conjunto de datos llamado MCT-Chat con unas 20 000 conversaciones multi-turno. El equipo comparó MCT-Chat con conjuntos de datos médicos chinos del mundo real bien conocidos como MedDialog, MedDG y DISC-Med-SFT. Medidas objetivas mostraron que MCT-Chat tiene una diversidad léxica muy fuerte y una rica redacción, a la vez que se centra en un conjunto de enfermedades y síntomas dirigido y apropiado para un entorno de examen. También cubre una amplia gama de roles de diálogo, temas y tareas, y su longitud típica y número de turnos se ajustan bien a las expectativas del MCT.
Valoraciones de expertos y direcciones futuras
Cinco expertos médicos evaluaron muestras aleatorias de MCT-Chat y de los conjuntos comparativos. Punturaron fluidez, imparcialidad, solidez médica, concordancia con los requisitos del MCT y la capacidad de distinguir distintos niveles de competencia. MCT-Chat obtuvo resultados a la par o ligeramente superiores a los conjuntos de datos del mundo real en la mayoría de los criterios, especialmente en racionalidad y discriminación para calificación, lo que sugiere que los datos sintéticos pueden ser candidatos serios para materiales de examen—aunque los autores subrayan que cualquier ítem de prueba real debe seguir sometiéndose a una rigurosa revisión manual. También señalan retos pendientes: los modelos de lenguaje todavía pueden malinterpretar temas complejos y los diálogos largos pueden deteriorarse en repetición sin un control cuidadoso. Los autores proponen mejorar el paso de clustering, incorporar actualizaciones de conocimiento más avanzadas y extender el marco a entornos multilingües y multiculturales para que conjuntos de datos de diálogo médico alineados con exámenes similares puedan construirse en todo el mundo.
Mensaje clave para no especialistas
Este estudio muestra que, con las salvaguardas adecuadas y estrategias de muestreo inteligentes, los modelos de lenguaje a gran escala pueden ayudar a crear conversaciones médicas realistas y seguras para la privacidad, adaptadas a un examen de idioma específico. Al mezclar directrices oficiales, filtros automáticos y revisión experta, los autores construyen un conjunto de 20 000 diálogos que sigue de cerca el Examen de Chino Médico. Para pacientes y estudiantes por igual, la implicación es que los futuros médicos podrían entrenar y ser evaluados usando diálogos sintéticos pero creíbles, reduciendo la dependencia de datos sensibles del mundo real sin dejar de prepararlos para la comunicación hospitalaria auténtica.
Cita: Zhou, H., Hu, X., He, T. et al. LLM-based medical dialogue dataset generation with automated instructions. Sci Rep 16, 12410 (2026). https://doi.org/10.1038/s41598-025-34835-1
Palabras clave: diálogo médico sintético, modelos de lenguaje a gran escala, examen de chino médico, generación de instrucciones, educación en lenguaje médico