Clear Sky Science · fr
Génération de jeux de dialogues médicaux basés sur des LLM avec instructions automatisées
Pourquoi les conversations médicales synthétiques comptent
Les hôpitaux regorgent de conversations : médecins interrogeant des patients, infirmières expliquant des traitements et collègues débattant de diagnostics. Ces échanges sont essentiels aux soins, mais ils sont difficiles à enregistrer et à partager en raison des lois sur la confidentialité et de la nature sensible des informations de santé. Parallèlement, les étudiants internationaux qui souhaitent travailler dans des hôpitaux chinois doivent réussir le Medical Chinese Test (MCT), qui exige des dialogues médicaux réalistes à plusieurs tours. Cet article décrit une méthode pour utiliser de grands modèles de langue — des systèmes comme ChatGPT — afin de créer automatiquement une collection riche, sûre et prête pour les examens de conversations médicales en chinois.
Construire des données utiles sans toucher aux patients réels
Les auteurs s'attaquent à un problème fondamental : comment obtenir suffisamment de dialogues médicaux de haute qualité pour former et évaluer des compétences linguistiques sans exposer d'informations réelles sur les patients. Les jeux de données de conversations publics ordinaires ne reflètent pas la complexité, le professionnalisme ni les règles éthiques des rencontres médicales réelles. Les échanges médicaux sont longs, étroitement connectés sur de nombreux tours et doivent respecter des schémas de rôle stricts — médecins s'exprimant en termes professionnels, patients décrivant leur état en langage courant, et infirmières coordonnant les soins. De plus, le MCT dispose de ses propres directives officielles qui précisent les sujets, tâches et vocabulaires attendus. Simplement demander à un modèle de langue de « fabriquer » des dialogues produit souvent un contenu irréaliste ou hors norme, aussi l'équipe conçoit-elle un cadre structuré pour orienter la génération.
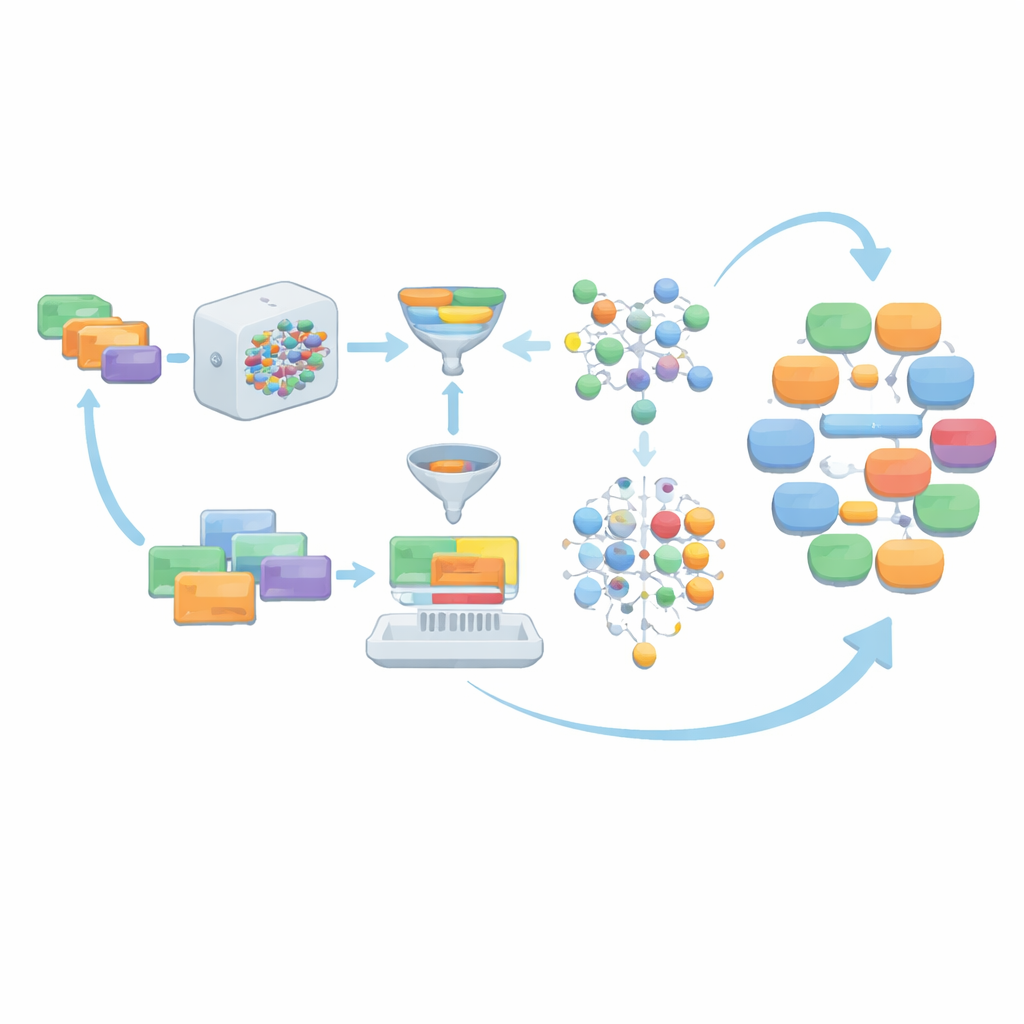
Des invites artisanales à un pool d'instructions évolutif
Le cadre, nommé AIG-MCT, commence par un petit ensemble d'instructions rédigées à la main qui font office de prompts détaillés pour le modèle de langue. Chaque instruction décrit qui parle (médecin, patient, infirmière), le scénario médical (par exemple, une consultation pédiatrique ou une urgence), la tâche (anamnèse, diagnostic, discussion du traitement, conseils de prévention), le nombre souhaité de tours de dialogue et une longueur approximative. Ces instructions initiales sont soigneusement construites à partir du plan des tâches du MCT, de la liste des sujets et du vocabulaire médical officiel, et exigent que les conversations résultantes restent dans des contextes médicaux réalistes et atteignent des niveaux de complexité spécifiques adaptés aux candidats du MCT.
Filtrage, notation et échantillonnage intelligent pour la diversité
Lorsque le modèle de langue génère des dialogues à partir de ces instructions, la sortie brute n'est pas acceptée telle quelle. Elle est soumise à plusieurs couches de nettoyage. Le matériel non dialogué, tel que des listes de type compte rendu ou des données structurées, est supprimé. Les rôles des locuteurs sont standardisés en quatre types de relation principaux — médecin–patient, médecin–infirmière, médecin–médecin et patient–infirmière — pour correspondre aux besoins du MCT. L'équipe vérifie ensuite si chaque dialogue utilise suffisamment de termes du vocabulaire médical officiel du MCT, s'il atteint un nombre minimum de tours et si sa longueur se situe dans une fourchette soigneusement choisie. Des outils optionnels de correction grammaticale polissent davantage le langage. Les dialogues qui échouent à ces contrôles, ainsi que leurs instructions sous-jacentes, sont écartés afin que seuls des exemples solides subsistent.
Laisser le modèle aider à écrire de meilleures prompts
Plutôt que de s'en remettre indéfiniment aux prompts initiaux rédigés par des humains, AIG-MCT permet au système d'apprendre de nouvelles instructions à partir de ses propres sorties. Le modèle de langue est invité non seulement à produire des dialogues, mais aussi à proposer de nouvelles instructions générées par la machine. Une technique appelée Maximal Marginal Relevance est utilisée pour sélectionner des instructions à la fois pertinentes par rapport au pool existant et clairement différentes de ce qui existe déjà, en comparant la similarité des instructions et des dialogues qu'elles génèrent. Ces instructions candidates sont ensuite regroupées par clustering avec l'algorithme k-means, et des représentants de chaque cluster sont choisis pour rafraîchir le pool d'instructions. Au fil des nombreuses itérations, la part des prompts écrits par des humains est progressivement réduite, tandis que des prompts générés par machine, soigneusement sélectionnés, prennent le relais, maintenant la diversité sans perdre l'alignement avec les règles du MCT.
Quelle est la qualité de la collection de dialogues médicaux obtenue ?
Pour tester leur approche, les auteurs ont utilisé ChatGPT (gpt-3.5-turbo) comme générateur principal et un modèle de langue médical spécialisé, ZuoYi, pour aider à vérifier le contenu médical. Ils ont itéré ce processus 40 fois, combinant filtres automatiques et relecture par des experts humains, et ont finalement construit un jeu de données appelé MCT-Chat contenant environ 20 000 dialogues multi‑tours. L'équipe a comparé MCT-Chat à des jeux de données connus de dialogues médicaux chinois issus du monde réel tels que MedDialog, MedDG et DISC-Med-SFT. Des mesures objectives ont montré que MCT-Chat présente une très forte diversité lexicale et une richesse de formulation, tout en restant concentré sur un ensemble ciblé de maladies et de symptômes appropriés pour un contexte d'examen. Il couvre également un large éventail de rôles, de sujets et de tâches de dialogue, et sa longueur et son nombre de tours typiques correspondent bien aux attentes du MCT.
Évaluations d'experts et directions futures
Cinq experts médicaux ont évalué des échantillons aléatoires tirés de MCT-Chat et des jeux de données de comparaison. Ils ont noté la fluidité, l'impartialité, la validité médicale, la conformité aux exigences du MCT et la capacité à distinguer différents niveaux de compétence. MCT-Chat obtient des scores équivalents ou légèrement supérieurs à ceux des jeux de données réels sur la plupart des critères, en particulier en rationalité et discrimination de niveau, suggérant que les données synthétiques peuvent être de sérieux candidats pour des matériaux d'examen — même si les auteurs soulignent que tout élément de test réel doit encore subir une validation manuelle stricte. Ils notent aussi des défis persistants : les modèles de langue peuvent encore mal interpréter des sujets délicats, et les dialogues longs peuvent dériver vers la répétition sans un contrôle attentif. Les auteurs proposent d'améliorer l'étape de clustering, d'incorporer des mises à jour de connaissances plus avancées et d'étendre le cadre à des contextes multilingues et multiculturels afin que des jeux de dialogues médicaux alignés sur des examens puissent être construits dans le monde entier.
Message clé pour non-spécialistes
Cette étude montre qu'avec des garde-fous appropriés et des stratégies d'échantillonnage intelligentes, les grands modèles de langue peuvent aider à créer des conversations médicales réalistes et respectueuses de la vie privée, adaptées à un examen linguistique précis. En combinant directives officielles, filtres automatiques et relecture par des experts, les auteurs ont construit un jeu de données de 20 000 dialogues qui suit de près le Medical Chinese Test. Pour les patients et les apprenants, cela signifie que les futurs médecins pourraient s'entraîner et être évalués à l'aide de dialogues synthétiques mais crédibles, réduisant la dépendance aux données sensibles du monde réel tout en les préparant à une communication hospitalière authentique.
Citation: Zhou, H., Hu, X., He, T. et al. LLM-based medical dialogue dataset generation with automated instructions. Sci Rep 16, 12410 (2026). https://doi.org/10.1038/s41598-025-34835-1
Mots-clés: dialogue médical synthétique, grands modèles de langue, test de chinois médical, génération d'instructions, enseignement de la langue médicale