Clear Sky Science · nl
Datasetgeneratie voor medische dialogen gebaseerd op LLM's met geautomatiseerde instructies
Waarom synthetische medische gesprekken ertoe doen
Ziekenhuizen zitten vol gesprekken: artsen die patiënten bevragen, verpleegkundigen die behandelingen uitleggen en collega’s die diagnoses bespreken. Deze gesprekken zijn cruciaal voor de zorg, maar ze zijn moeilijk vast te leggen en te delen vanwege privacywetgeving en de gevoelige aard van gezondheidsinformatie. Tegelijkertijd moeten internationale studenten die in Chinese ziekenhuizen willen werken slagen voor de Medical Chinese Test (MCT), waarvoor realistische meerbeurtige medische dialogen nodig zijn. Dit artikel beschrijft een methode om grote taalmodellen — systemen zoals ChatGPT — te gebruiken om automatisch een rijke, veilige en examenklare verzameling medische gesprekken in het Chinees te genereren.
Handige data opbouwen zonder echte patiënten te betrekken
De auteurs pakken een kernprobleem aan: hoe verkrijg je voldoende hoogwaardige medische dialoogdata voor training en toetsing van taalvaardigheden zonder echte patiëntgegevens bloot te leggen. Gewone openbare chatdatasets missen de complexiteit, professionaliteit en ethische regels van echte medische ontmoetingen. Medische gesprekken zijn lang, sterk verbonden over veel beurten en moeten strikte rolpatronen respecteren — artsen spreken professioneel, patiënten gebruiken alledaagse beschrijvingen en verpleegkundigen coördineren de zorg. Bovendien heeft de MCT eigen officiële richtlijnen die specificeren welke onderwerpen, taken en woordenschat moeten voorkomen. Het zomaar laten ‘verzinnen’ van dialogen door een taalmodel levert vaak onrealistische of niet-standaard inhoud op, daarom ontwerp het team een gestructureerd raamwerk om de generatie te sturen.
Van handgemaakte prompts naar een evoluerend instructievoorraad
Het raamwerk, AIG-MCT genoemd, begint met een kleine set handgemaakte instructies die fungeren als gedetailleerde prompts voor het taalmodel. Elke instructie beschrijft wie er spreekt (arts, patiënt, verpleegkundige), het medische scenario (bijvoorbeeld een kinderafdeling of spoedeisende hulp), de taak (anamnese, diagnose, behandelingsbespreking, preventieadvies), het gewenste aantal dialoogbeurten en een geschatte lengte. Deze zaad-instructies zijn zorgvuldig opgebouwd uit het MCT-taakoverzicht, de lijst met onderwerpen en de officiële medische woordenschat, en vereisen dat de resulterende gesprekken binnen realistische medische contexten blijven en specifieke complexiteitsniveaus halen die geschikt zijn voor MCT-kandidaten.
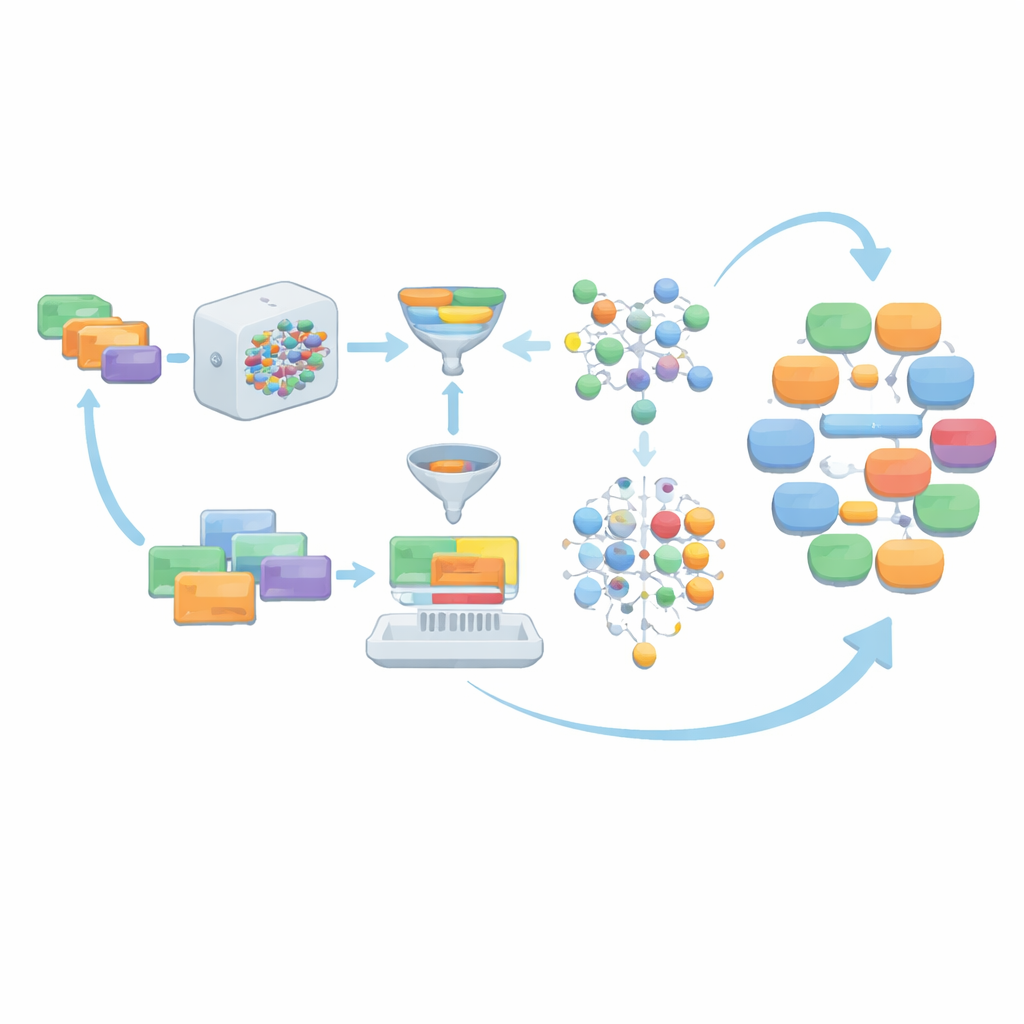
Filteren, scoren en slim sampelen voor diversiteit
Wanneer het taalmodel dialogen genereert op basis van deze instructies, wordt de ruwe output niet klakkeloos aangenomen. In plaats daarvan doorloopt deze meerdere lagen van opschoning. Niet-dialogisch materiaal, zoals recordachtige lijsten of gestructureerde data, wordt verwijderd. Sprekersrollen worden gestandaardiseerd in vier hoofdrelatietypen — arts–patiënt, arts–verpleegkundige, arts–arts en patiënt–verpleegkundige — om aan MCT-behoeften te voldoen. Het team controleert vervolgens of elke dialoog voldoende woorden uit de officiële MCT-medische woordenschat gebruikt, of het een minimum aantal beurten bereikt en of de lengte binnen een zorgvuldig gekozen bereik valt. Optionele grammaticacorrectietools polijsten de taal verder. Dialogen die deze controles niet doorstaan, samen met hun onderliggende instructies, worden verworpen zodat alleen sterke voorbeelden overblijven.
Het model laten helpen betere prompts te schrijven
In plaats van voor altijd te vertrouwen op de initiële menselijk geschreven prompts, laat AIG-MCT het systeem nieuwe instructies leren uit zijn eigen output. Het taalmodel wordt gevraagd niet alleen dialogen te produceren, maar ook nieuwe machinegegenereerde instructies voor te stellen. Een techniek genaamd Maximal Marginal Relevance wordt gebruikt om instructies te selecteren die zowel relevant zijn voor de bestaande voorraad als duidelijk verschillen van wat al aanwezig is, door te vergelijken hoe gelijkend de instructies en hun resulterende dialogen zijn. Deze kandidaat-instructies worden vervolgens geclusterd met behulp van het K-means-algoritme, en representatieve instructies uit elke cluster worden gekozen om de instructievoorraad te vernieuwen. Over vele rondes wordt het aandeel menselijk geschreven prompts geleidelijk verminderd, terwijl zorgvuldig geselecteerde machinegegenereerde prompts het overnemen, waardoor diversiteit behouden blijft zonder de afstemming op MCT-regels te verliezen.
Hoe goed is de resulterende verzameling medische gesprekken?
Om hun aanpak te testen gebruikten de auteurs ChatGPT (gpt-3.5-turbo) als hoofdgenerator en een gespecialiseerd medisch taalmodel, ZuoYi, om te helpen bij het controleren van medische inhoud. Ze herhaalden dit proces 40 keer, combineerden geautomatiseerde filters met beoordeling door menselijke experts en bouwden uiteindelijk een dataset genaamd MCT-Chat met ongeveer 20.000 meerbeurtige dialogen. Het team vergeleek MCT-Chat met bekende Chinese medische dialoogdatasets uit de praktijk zoals MedDialog, MedDG en DISC-Med-SFT. Objectieve metingen lieten zien dat MCT-Chat een zeer sterke lexicale diversiteit en rijke woordkeuze heeft, terwijl het zich toch richt op een doelgerichte set ziekten en symptomen die geschikt zijn voor een examenomgeving. Het dekt ook een breed scala aan dialogrollen, onderwerpen en taken, en de typische lengte en het aantal beurten komen goed overeen met MCT-verwachtingen.
Beoordelingen door experts en toekomstige richtingen
Vijf medische experts beoordeelden willekeurige steekproeven uit MCT-Chat en uit de vergelijkingsdatasets. Ze beoordeelden vloeiendheid, eerlijkheid, medische degelijkheid, overeenstemming met MCT-vereisten en het vermogen om verschillende vaardigheidsniveaus te onderscheiden. MCT-Chat scoorde gelijk aan of iets beter dan real-world datasets op de meeste criteria, vooral op rationaliteit en discriminatie bij beoordeling, wat suggereert dat synthetische data serieuze kandidaten kunnen zijn voor examenvragen — hoewel de auteurs benadrukken dat daadwerkelijke toetsitems nog steeds strenge handmatige evaluatie moeten ondergaan. Ze merken ook resterende uitdagingen op: taalmodellen kunnen ingewikkelde onderwerpen nog misinterpreteren en lange dialogen kunnen zonder zorgvuldige sturing in herhaling vervallen. De auteurs stellen verbeteringen voor in de clusteringstap, het opnemen van meer geavanceerde kennisupdates en het uitbreiden van het raamwerk naar meertalige en multiculturele settings, zodat vergelijkbare examen-gealigneerde medische dialoogdatasets wereldwijd gebouwd kunnen worden.
Belangrijkste boodschap voor niet-specialisten
Deze studie toont aan dat grote taalmodellen, met de juiste waarborgen en slimme steekproefstrategieën, kunnen helpen bij het creëren van realistische, privacy-veilige medische gesprekken afgestemd op een specifiek taalexamen. Door officiële richtlijnen, automatische filters en deskundige beoordeling te combineren, bouwen de auteurs een dataset van 20.000 dialogen die nauw aansluit bij de Medical Chinese Test. Voor patiënten en studenten betekent dit dat toekomstige artsen mogelijk getraind en beoordeeld worden met synthetische maar geloofwaardige dialogen, waardoor afhankelijkheid van gevoelige echte data afneemt terwijl ze toch voorbereid worden op authentieke ziekenhuiscommunicatie.
Bronvermelding: Zhou, H., Hu, X., He, T. et al. LLM-based medical dialogue dataset generation with automated instructions. Sci Rep 16, 12410 (2026). https://doi.org/10.1038/s41598-025-34835-1
Trefwoorden: synthetische medische dialoog, grote taalmodellen, Medisch Chinees examen, instructiegeneratie, medische taaleducatie