Clear Sky Science · en
LLM-based medical dialogue dataset generation with automated instructions
Why synthetic medical chats matter
Hospitals are full of conversations: doctors questioning patients, nurses explaining treatments, and colleagues debating diagnoses. These talks are vital for care, but they are hard to record and share because of privacy laws and the sensitive nature of health information. At the same time, international students who want to work in Chinese hospitals must pass the Medical Chinese Test (MCT), which demands realistic multi-turn medical dialogues. This paper describes a way to use large language models—systems like ChatGPT—to automatically create a rich, safe, and exam-ready collection of medical conversations in Chinese.
Building useful data without touching real patients
The authors tackle a key problem: how to get enough high-quality medical dialogue data for training and testing language skills without exposing real patient information. Ordinary public chat datasets do not match the complexity, professionalism, or ethical rules of real medical encounters. Medical talks are long, tightly connected across many turns, and must respect strict role patterns—doctors speaking in professional terms, patients using everyday descriptions, and nurses coordinating care. On top of that, MCT has its own official guidelines that specify which topics, tasks, and vocabulary should appear. Simply asking a language model to “make up” dialogues often produces unrealistic or off‑standard content, so the team designs a structured framework to steer generation.
From hand-crafted prompts to an evolving instruction pool
The framework, called AIG-MCT, starts with a small hand-crafted set of instructions that act like detailed prompts for the language model. Each instruction describes who is talking (doctor, patient, nurse), the medical scenario (for example, a pediatric clinic or emergency room), the task (history taking, diagnosis, treatment discussion, prevention advice), the desired number of dialogue turns, and an approximate length. These seed instructions are carefully built from the MCT task outline, topic list, and official medical vocabulary, and they require that the resulting conversations stay within realistic medical settings and meet specific complexity levels suitable for MCT candidates.
Filtering, scoring, and smart sampling for diversity
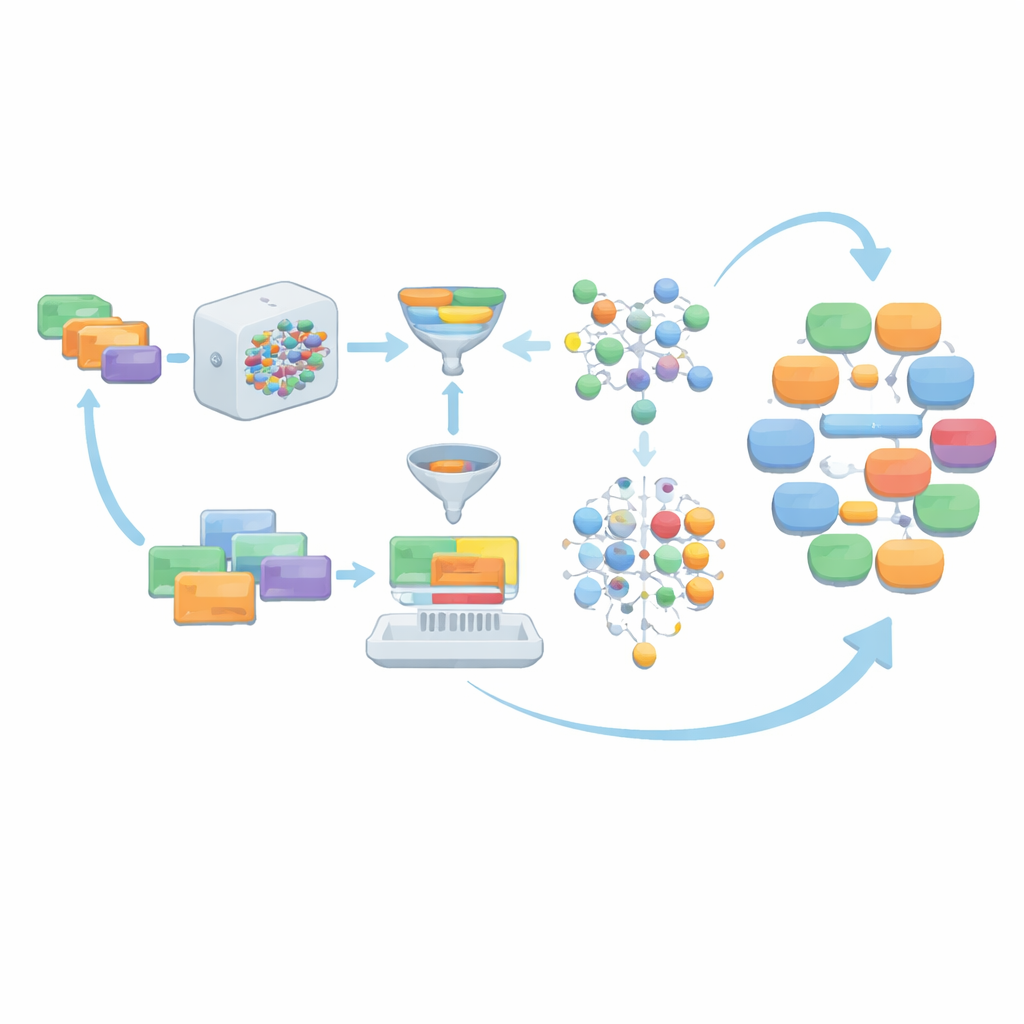
When the language model generates dialogues from these instructions, the raw output is not accepted as-is. Instead, it goes through several layers of clean‑up. Non-dialogue material, such as record-like lists or structured data, is removed. Speaker roles are standardized into four main relationship types—doctor–patient, doctor–nurse, doctor–doctor, and patient–nurse—to match MCT needs. The team then checks whether each dialogue uses enough words from the official MCT medical vocabulary, whether it reaches a minimum number of turns, and whether its length falls within a carefully chosen range. Optional grammar correction tools further polish the language. Dialogues that fail these checks, along with their underlying instructions, are discarded so that only strong examples remain.
Letting the model help write better prompts
Rather than relying forever on the initial human-written prompts, AIG-MCT allows the system to learn new instructions from its own outputs. The language model is asked not only to produce dialogues but also to propose new machine-generated instructions. A technique called Maximal Marginal Relevance is used to pick instructions that are both relevant to the existing pool and clearly different from what is already there, by comparing how similar the instructions and their resulting dialogues are. These candidate instructions are then clustered using the K-means algorithm, and representative ones from each cluster are chosen to refresh the instruction pool. Over many rounds, the share of human-written prompts is gradually reduced, while carefully selected machine-generated prompts take over, maintaining diversity without losing alignment with MCT rules.
How good is the resulting medical chat collection?
To test their approach, the authors used ChatGPT (gpt-3.5-turbo) as the main generator and a specialized medical language model, ZuoYi, to help check medical content. They iterated this process 40 times, combining automated filters with human expert review, and ultimately built a dataset called MCT-Chat with about 20,000 multi-turn dialogues. The team compared MCT-Chat to well-known real-world Chinese medical dialogue datasets such as MedDialog, MedDG, and DISC-Med-SFT. Objective measures showed that MCT-Chat has very strong lexical diversity and rich wording, while still focusing on a targeted set of diseases and symptoms appropriate for an exam setting. It also covers a wide range of dialogue roles, topics, and tasks, and its typical length and turn count are well matched to MCT expectations.
Expert judgments and future directions
Five medical experts rated random samples from MCT-Chat and from the comparison datasets. They scored fluency, fairness, medical soundness, match with MCT requirements, and the ability to distinguish different proficiency levels. MCT-Chat scored on par with or slightly better than real-world datasets on most criteria, especially in rationality and grading discrimination, suggesting that synthetic data can be serious candidates for exam materials—though the authors stress that any actual test items must still undergo strict manual vetting. They also note remaining challenges: language models can still misinterpret tricky topics, and long dialogues can deteriorate into repetition without careful control. The authors propose improving the clustering step, incorporating more advanced knowledge updates, and extending the framework to multilingual and multicultural settings so that similar exam-aligned medical dialogue datasets can be built around the world.
Take-home message for non-specialists
This study shows that, with the right safeguards and smart sampling strategies, large language models can help create realistic, privacy-safe medical conversations tailored to a specific language exam. By mixing official guidelines, automatic filters, and expert review, the authors build a 20,000-dialogue dataset that closely follows the Medical Chinese Test. For patients and learners alike, the implication is that future doctors may train and be assessed using synthetic yet credible dialogues, reducing reliance on sensitive real-world data while still preparing them for authentic hospital communication.
Citation: Zhou, H., Hu, X., He, T. et al. LLM-based medical dialogue dataset generation with automated instructions. Sci Rep 16, 12410 (2026). https://doi.org/10.1038/s41598-025-34835-1
Keywords: synthetic medical dialogue, large language models, medical chinese test, instruction generation, medical language education