Clear Sky Science · sv
LLM-baserad generering av medicinska dialoger med automatiserade instruktioner
Varför syntetiska medicinska samtal är viktiga
Sjukhus är fulla av samtal: läkare som ställer frågor till patienter, sjuksköterskor som förklarar behandlingar och kollegor som diskuterar diagnoser. Dessa samtal är avgörande för vården, men de är svåra att spela in och dela på grund av sekretesslagar och känslig hälsorelaterad information. Samtidigt måste internationella studenter som vill arbeta på kinesiska sjukhus klara Medical Chinese Test (MCT), vilket kräver realistiska medicinska dialoger med flera vändor. Den här artikeln beskriver ett sätt att använda stora språkmodeller — system som ChatGPT — för att automatiskt skapa en rik, säker och provanpassad samling medicinska konversationer på kinesiska.
Bygga användbar data utan att röra riktiga patienter
Författarna tar sig an en central utmaning: hur man får tillräckligt med högkvalitativ medicinsk dialogdata för att träna och testa språkkunskaper utan att exponera verklig patientinformation. Vanliga offentliga chattdataset motsvarar inte komplexiteten, yrkesmässigheten eller de etiska reglerna i verkliga medicinska möten. Medicinska samtal är långa, tätt sammankopplade över många vändor och måste följa strikta rollmönster — läkare som talar i professionella termer, patienter som använder vardagliga beskrivningar och sjuksköterskor som samordnar vården. Dessutom har MCT sina egna officiella riktlinjer som specificerar vilka ämnen, uppgifter och vokabulär som ska förekomma. Att bara be en språkmodell att "hitta på" dialoger ger ofta orealistiskt eller icke-standardinnehåll, så teamet utformar ett strukturerat ramverk för att styra genereringen.
Från handgjorda prompts till en växande instruktionpool
Ramverket, kallat AIG-MCT, börjar med en liten handgjord uppsättning instruktioner som fungerar som detaljerade prompts för språkmodellen. Varje instruktion beskriver vem som talar (läkare, patient, sjuksköterska), det medicinska scenariot (till exempel barnkliniken eller akutmottagningen), uppgiften (anamnes, diagnostik, behandlingsdiskussion, förebyggande råd), önskat antal dialogvändor och ungefärlig längd. Dessa startinstruktioner är noggrant byggda utifrån MCT:s uppgiftsöversikt, ämneslista och officiella medicinska vokabulär, och de kräver att de resulterande konversationerna håller sig inom realistiska medicinska ramar och uppnår särskilda komplexitetsnivåer som passar MCT-kandidater.
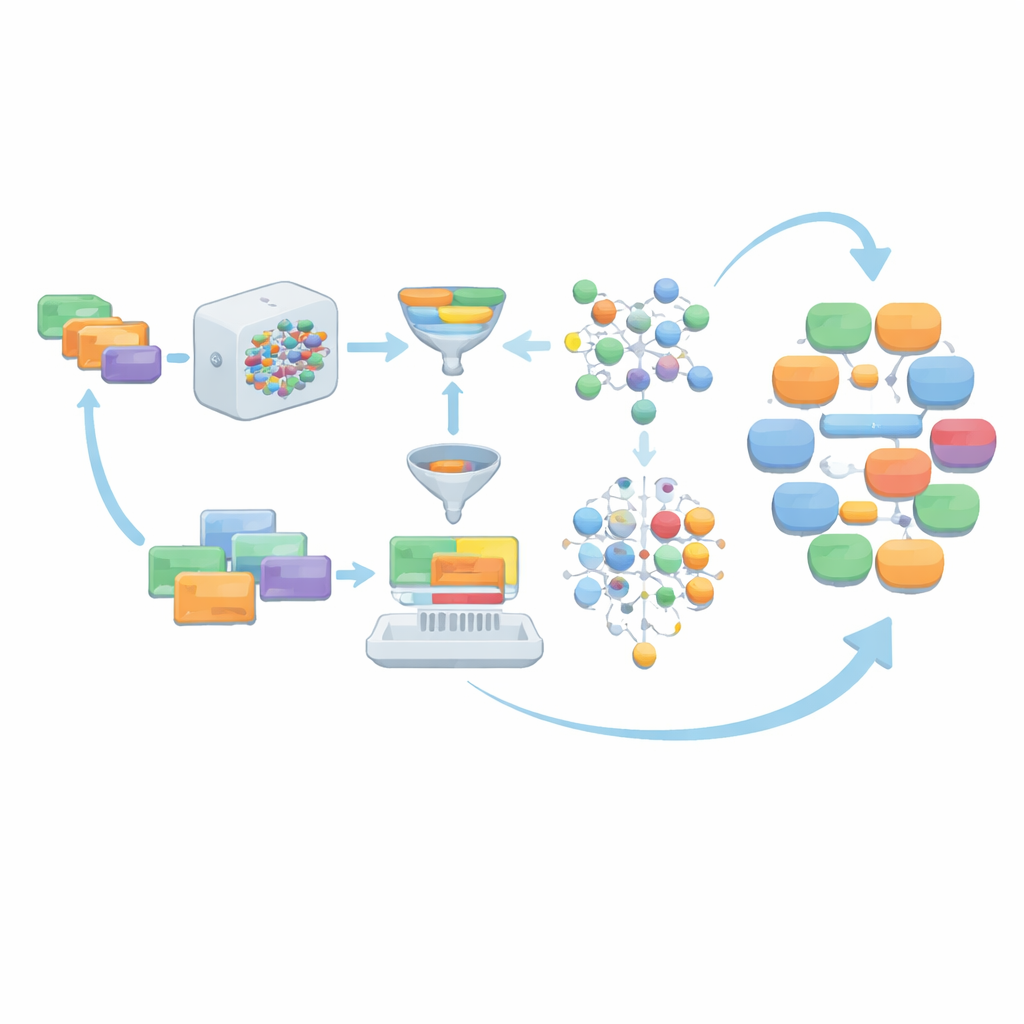
Filtrering, poängsättning och smart sampling för mångfald
När språkmodellen genererar dialoger från dessa instruktioner accepteras inte råutdata som de är. Istället går de igenom flera lager av uppstädning. Icke-dialogiskt material, såsom journal-liknande listor eller strukturerade data, tas bort. Talarroller standardiseras till fyra huvudsakliga relationstyper — läkare–patient, läkare–sjuksköterska, läkare–läkare och patient–sjuksköterska — för att matcha MCT-behoven. Teamet kontrollerar sedan om varje dialog använder tillräckligt många ord från den officiella MCT-medicinska vokabulären, om den når ett minsta antal vändor och om dess längd ligger inom ett noggrant valt intervall. Valfria grammatikkorrigeringsverktyg polerar språket ytterligare. Dialoger som inte klarar dessa kontroller, tillsammans med deras underliggande instruktioner, kasseras så att endast starka exempel blir kvar.
Låta modellen hjälpa till att skriva bättre prompts
I stället för att förlita sig för alltid på de ursprungliga människoskrivna promptarna tillåter AIG-MCT systemet att lära sig nya instruktioner från sina egna utdata. Språkmodellen ombeds inte bara att producera dialoger utan också att föreslå nya maskingenererade instruktioner. En teknik kallad Maximal Marginal Relevance används för att välja instruktioner som både är relevanta för den befintliga poolen och tydligt skiljer sig från vad som redan finns, genom att jämföra hur lika instruktionerna och deras resulterande dialoger är. Dessa kandidat-instruktioner klustras sedan med K-means-algoritmen, och representativa instruktioner från varje kluster väljs för att förnya instruktionpoolen. Över många rundor minskar andelen människoskrivna prompts gradvis, medan noggrant utvalda maskingenererade prompts tar över, vilket bevarar mångfald utan att tappa överensstämmelse med MCT-reglerna.
Hur bra är den resulterande samlingen medicinska chattar?
För att testa sitt tillvägagångssätt använde författarna ChatGPT (gpt-3.5-turbo) som huvudsaklig generator och en specialiserad medicinsk språkmodell, ZuoYi, för att hjälpa till att kontrollera medicinskt innehåll. De itererade denna process 40 gånger, kombinerade automatiska filter med human expertgranskning och byggde slutligen ett dataset kallat MCT-Chat med omkring 20 000 dialoger med flera vändor. Teamet jämförde MCT-Chat med välkända verkliga kinesiska medicinska dialogdataset som MedDialog, MedDG och DISC-Med-SFT. Objektiva mått visade att MCT-Chat har mycket stark lexikal mångfald och rik ordanvändning, samtidigt som det fokuserar på en riktad uppsättning sjukdomar och symtom som är lämpliga för ett provsammanhang. Det täcker också ett brett spektrum av dialogroller, ämnen och uppgifter, och dess typiska längd och antal vändor matchar väl MCT-förväntningarna.
Expertbedömningar och framtida riktningar
Fem medicinska experter bedömde slumpmässiga urval från MCT-Chat och från jämförelsedatamängderna. De poängsatte flyt, rättvisa, medicinsk hållbarhet, överensstämmelse med MCT-krav och förmågan att särskilja olika kompetensnivåer. MCT-Chat fick resultat i nivå med eller något bättre än verkliga dataset på de flesta kriterier, särskilt vad gäller rationalitet och diskriminering i bedömning, vilket tyder på att syntetiska data kan vara seriösa kandidater för provmaterial — även om författarna betonar att faktiska provuppgifter fortfarande måste genomgå strikt manuell prövning. De noterar också återstående utmaningar: språkmodeller kan fortfarande misstolka knepiga ämnen, och långa dialoger kan urarta i upprepning utan noggrann kontroll. Författarna föreslår att förbättra klustringssteget, införliva mer avancerade kunskapsuppdateringar och utvidga ramverket till flerspråkiga och mångkulturella inställningar så att liknande provanpassade medicinska dialogdataset kan byggas runt om i världen.
Sammanfattning för icke-specialister
Studien visar att med rätt skyddsåtgärder och smarta samplingsstrategier kan stora språkmodeller hjälpa till att skapa realistiska, sekretessäkra medicinska konversationer anpassade till ett specifikt språktest. Genom att blanda officiella riktlinjer, automatiska filter och expertgranskning bygger författarna ett dataset med 20 000 dialoger som följer Medical Chinese Test nära. För både patienter och studerande innebär detta att framtida läkare kan träna och bedömas med syntetiska men trovärdiga dialoger, vilket minskar beroendet av känslig verklig data samtidigt som de förbereds för autentisk sjukhuskommunikation.
Citering: Zhou, H., Hu, X., He, T. et al. LLM-based medical dialogue dataset generation with automated instructions. Sci Rep 16, 12410 (2026). https://doi.org/10.1038/s41598-025-34835-1
Nyckelord: syntetisk medicinsk dialog, stora språkmodeller, medicinskt kinesiskt prov, generering av instruktioner, medicinskt språkutbildning