Clear Sky Science · de
Erzeugung medizinischer Dialogdatensätze mit LLMs und automatisierten Anweisungen
Warum synthetische medizinische Gespräche wichtig sind
Krankenhäuser sind voller Gespräche: Ärzt:innen befragen Patient:innen, Pflegekräfte erklären Behandlungen und Kolleg:innen diskutieren Diagnosen. Diese Unterhaltungen sind zentral für die Versorgung, lassen sich aber wegen Datenschutzbestimmungen und der sensiblen Natur von Gesundheitsdaten nur schwer aufzeichnen und teilen. Gleichzeitig müssen internationale Studierende, die in chinesischen Krankenhäusern arbeiten wollen, den Medical Chinese Test (MCT) bestehen, der realistische mehrtürige medizinische Dialoge verlangt. Dieser Beitrag beschreibt eine Methode, wie man große Sprachmodelle – Systeme wie ChatGPT – nutzt, um automatisch eine umfangreiche, sichere und prüfungsgeeignete Sammlung medizinischer Gespräche auf Chinesisch zu erzeugen.
Nützliche Daten erstellen, ohne reale Patient:innen zu berühren
Die Autor:innen gehen ein zentrales Problem an: Wie gewinnt man genügend hochwertige medizinische Dialogdaten zum Trainieren und Testen sprachlicher Fertigkeiten, ohne reale Patientendaten preiszugeben? Öffentliche Chat-Datensätze entsprechen oft weder der Komplexität noch der fachlichen Tiefe oder den ethischen Anforderungen realer medizinischer Begegnungen. Medizinische Gespräche sind lang, über viele Turns eng verknüpft und müssen strikte Rollenmuster einhalten – Ärzt:innen in fachlicher Sprache, Patient:innen in Alltagsbeschreibungen, Pflegekräfte koordinierend. Zudem hat der MCT eigene offizielle Vorgaben, welche Themen, Aufgaben und Fachbegriffe vorkommen müssen. Einfach ein Sprachmodell „Dialoge erfinden“ zu lassen, führt oft zu unrealistischem oder prüfungsfernem Inhalt, weshalb das Team ein strukturiertes Framework zur Steuerung der Generierung entwickelt.
Von handgefertigten Prompts zu einem sich entwickelnden Anweisungspool
Das Framework namens AIG-MCT beginnt mit einer kleinen, handgefertigten Menge an Anweisungen, die als detaillierte Prompts für das Sprachmodell fungieren. Jede Anweisung beschreibt, wer spricht (Arzt/Ärztin, Patient/Patientin, Pflegekraft), das medizinische Szenario (z. B. pädiatrische Ambulanz oder Notaufnahme), die Aufgabe (Anamnese, Diagnose, Therapiegespräch, Präventionsberatung), die gewünschte Anzahl an Gesprächs-Turns und eine ungefähre Länge. Diese Seed-Anweisungen leiten sich sorgfältig aus dem MCT-Aufgabenrahmen, der Themenliste und dem offiziellen medizinischen Vokabular ab und verlangen, dass die resultierenden Gespräche in realistischen medizinischen Kontexten bleiben und spezifische Komplexitätsstufen für MCT-Kandidaten erfüllen.
Filterung, Bewertung und intelligentes Sampling für Vielfalt
Wenn das Sprachmodell Dialoge aus diesen Anweisungen generiert, wird die Rohausgabe nicht unverändert übernommen. Stattdessen durchläuft sie mehrere Bereinigungsschichten. Nicht-dialogische Inhalte wie protokollartige Listen oder strukturierte Daten werden entfernt. Sprecherrollen werden in vier Hauptbeziehungstypen standardisiert – Arzt–Patient, Arzt–Pflegekraft, Arzt–Arzt und Patient–Pflegekraft – um den MCT-Bedürfnissen zu entsprechen. Das Team prüft zudem, ob jeder Dialog genügend Begriffe aus dem offiziellen MCT-medizinvokabular verwendet, ob er eine Mindestanzahl an Turns erreicht und ob seine Länge in einem sorgfältig gewählten Bereich liegt. Optionale Grammatik-Korrekturwerkzeuge polieren die Sprache weiter. Dialoge, die diese Prüfungen nicht bestehen, sowie die zugrunde liegenden Anweisungen werden verworfen, sodass nur hochwertige Beispiele verbleiben.
Das Modell anleiten, bessere Prompts zu schreiben
Anstatt dauerhaft auf die initialen menschlich geschriebenen Prompts zu setzen, erlaubt AIG-MCT dem System, neue Anweisungen aus seinen eigenen Ausgaben zu lernen. Das Sprachmodell wird nicht nur gebeten, Dialoge zu erzeugen, sondern auch neue, maschinell generierte Anweisungen vorzuschlagen. Eine Technik namens Maximal Marginal Relevance wird verwendet, um solche Anweisungen auszuwählen, die sowohl relevant für den bestehenden Pool als auch deutlich verschieden von bereits vorhandenem Material sind, indem Ähnlichkeiten zwischen Anweisungen und ihren resultierenden Dialogen verglichen werden. Diese Kandidatenanweisungen werden anschließend mit dem K-means-Algorithmus geclustert, und repräsentative Anweisungen aus jedem Cluster werden ausgewählt, um den Anweisungspool zu erneuern. Über viele Runden wird der Anteil menschlich verfasster Prompts schrittweise reduziert, während sorgfältig ausgewählte maschinell erzeugte Prompts die Vielfalt bewahren, ohne die Übereinstimmung mit den MCT-Regeln zu verlieren.
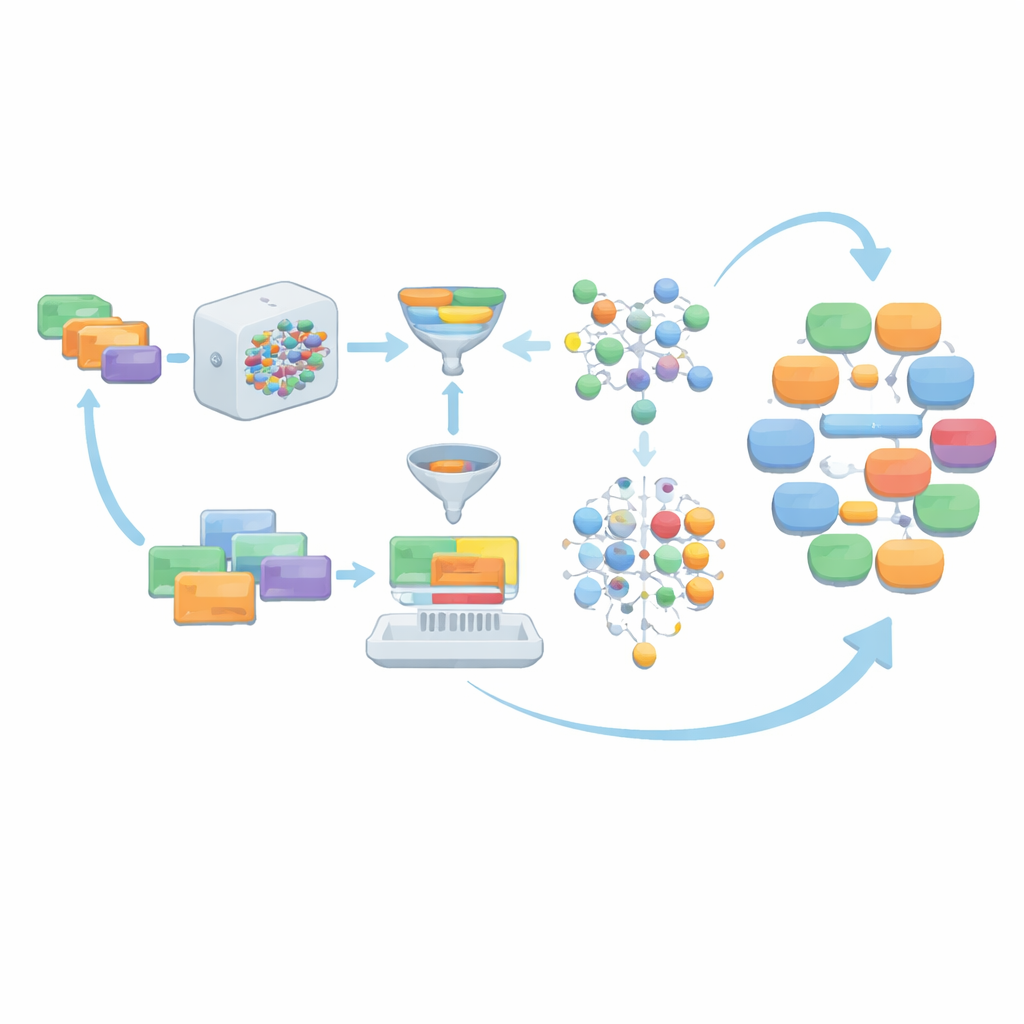
Wie gut ist die resultierende Sammlung medizinischer Dialoge?
Zur Evaluation nutzten die Autor:innen ChatGPT (gpt-3.5-turbo) als Hauptgenerator und ein spezialisiertes medizinisches Sprachmodell, ZuoYi, zur Unterstützung bei der Überprüfung medizinischer Inhalte. Sie führten diesen Prozess 40 Iterationen durch, kombinierten automatisierte Filter mit menschlicher Expertenbegutachtung und bauten schließlich einen Datensatz namens MCT-Chat mit etwa 20.000 mehrtürigen Dialogen auf. Das Team verglich MCT-Chat mit bekannten realen chinesischen medizinischen Dialogdatensätzen wie MedDialog, MedDG und DISC-Med-SFT. Objektive Messungen zeigten, dass MCT-Chat eine sehr starke lexikalische Vielfalt und reichere Ausdrucksweisen besitzt, während es sich gleichzeitig auf eine zielgerichtete Menge von Krankheiten und Symptomen konzentriert, die für eine Prüfungssituation angemessen sind. Es deckt außerdem ein breites Spektrum an Gesprächsrollen, Themen und Aufgaben ab, und typische Länge sowie Turn-Anzahl entsprechen gut den MCT-Erwartungen.
Gutachterliche Bewertungen und zukünftige Richtungen
Fünf medizinische Expert:innen bewerteten zufällige Proben aus MCT-Chat und den Vergleichsdatensätzen. Sie beurteilten Flüssigkeit, Fairness, medizinische Fundiertheit, Übereinstimmung mit den MCT-Anforderungen und die Fähigkeit, unterschiedliche Kompetenzstufen zu unterscheiden. MCT-Chat schnitt bei den meisten Kriterien in etwa gleichauf oder etwas besser ab als reale Datensätze, insbesondere bei Rationalität und in der Unterscheidung von Leistungsstufen, was darauf hindeutet, dass synthetische Daten ernsthafte Kandidaten für Prüfungsinhalte sein können – wobei die Autor:innen betonen, dass echte Testaufgaben weiterhin strenger manueller Prüfung unterzogen werden müssen. Sie verweisen auch auf verbleibende Herausforderungen: Sprachmodelle können komplexe Themen fehlinterpretieren, und lange Dialoge können ohne sorgfältige Steuerung in Wiederholung abdriften. Die Autor:innen schlagen vor, den Clustering-Schritt zu verbessern, fortgeschrittenere Wissensaktualisierungen zu integrieren und das Framework auf mehrsprachige und multikulturelle Kontexte auszudehnen, damit ähnliche prüfungsorientierte medizinische Dialogdatensätze weltweit entstehen können.
Fazit für Nicht-Spezialist:innen
Die Studie zeigt, dass große Sprachmodelle mit geeigneten Schutzmaßnahmen und intelligenten Sampling-Strategien realistische, datenschutzkonforme medizinische Gespräche zu einem spezifischen Sprachtest beitragen können. Durch die Kombination offizieller Richtlinien, automatischer Filter und Expertenprüfung erzeugen die Autor:innen einen 20.000-Dialoge-Datensatz, der eng dem Medical Chinese Test folgt. Für Patient:innen und Lernende bedeutet das: Zukünftige Ärzt:innen könnten mithilfe synthetischer, aber glaubwürdiger Dialoge ausgebildet und geprüft werden, wodurch die Abhängigkeit von sensiblen realen Daten reduziert wird, ohne die Vorbereitung auf authentische Krankenhauskommunikation zu beeinträchtigen.
Zitation: Zhou, H., Hu, X., He, T. et al. LLM-based medical dialogue dataset generation with automated instructions. Sci Rep 16, 12410 (2026). https://doi.org/10.1038/s41598-025-34835-1
Schlüsselwörter: synthetischer medizinischer Dialog, große Sprachmodelle, medizinischer Chinesisch-Test, Anweisungserzeugung, medizinische Sprachbildung