Clear Sky Science · ru
Генерация медицинских диалогов на основе LLM с автоматизированными инструкциями
Почему важны синтетические медицинские беседы
В больницах постоянно ведутся разговоры: врачи расспрашивают пациентов, медсёстры объясняют лечение, коллеги обсуждают диагнозы. Эти беседы жизненно важны для ухода, но их трудно записывать и распространять из‑за законов о конфиденциальности и чувствительного характера медицинской информации. В то же время иностранным студентам, желающим работать в китайских больницах, необходимо сдать тест по медицинскому китайскому (MCT), который требует реалистичных многоходовых медицинских диалогов. В этой работе описывается метод использования больших языковых моделей — систем наподобие ChatGPT — для автоматического создания богатой, безопасной и готовой к экзамену коллекции медицинских разговоров на китайском.
Создание полезных данных без контакта с реальными пациентами
Авторы решают ключевую задачу: как получить достаточное количество высококачественных медицинских диалогов для обучения и тестирования языковых навыков, не раскрывая данные реальных пациентов. Обычные публичные наборы чатов не соответствуют сложности, профессионализму и этическим требованиям реальных медицинских взаимодействий. Медицинские разговоры длинные, тесно связаны между ходами и должны соблюдаться строгие роль‑овые шаблоны — врачи говорят профессионально, пациенты используют повседневные описания, медсёстры координируют уход. Кроме того, MCT имеет свои официальные руководящие указания, определяющие темы, задачи и лексику. Простая просьба к модели «сочинить» диалоги часто даёт нереалистичный или не соответствующий стандартам контент, поэтому команда разработала структурированную рамку для управления генерацией.
От вручную подготовленных подсказок к развивающемуся пулу инструкций
Рамка, названная AIG-MCT, начинается с небольшой вручную подготовленной коллекции инструкций, которые действуют как детализированные подсказки для языковой модели. Каждая инструкция описывает, кто говорит (врач, пациент, медсестра), медицинский сценарий (например, педиатрическая клиника или отделение неотложной помощи), задачу (сбор анамнеза, постановка диагноза, обсуждение лечения, профилактические советы), желаемое число ходов диалога и ориентировочную длину. Эти стартовые инструкции тщательно составлены на основе плана задач MCT, списка тем и официальной медицинской лексики и требуют, чтобы получившиеся беседы оставались в реалистичных медицинских рамках и соответствовали определённым уровням сложности, подходящим кандидатам MCT.
Фильтрация, оценка и умная выборка для разнообразия
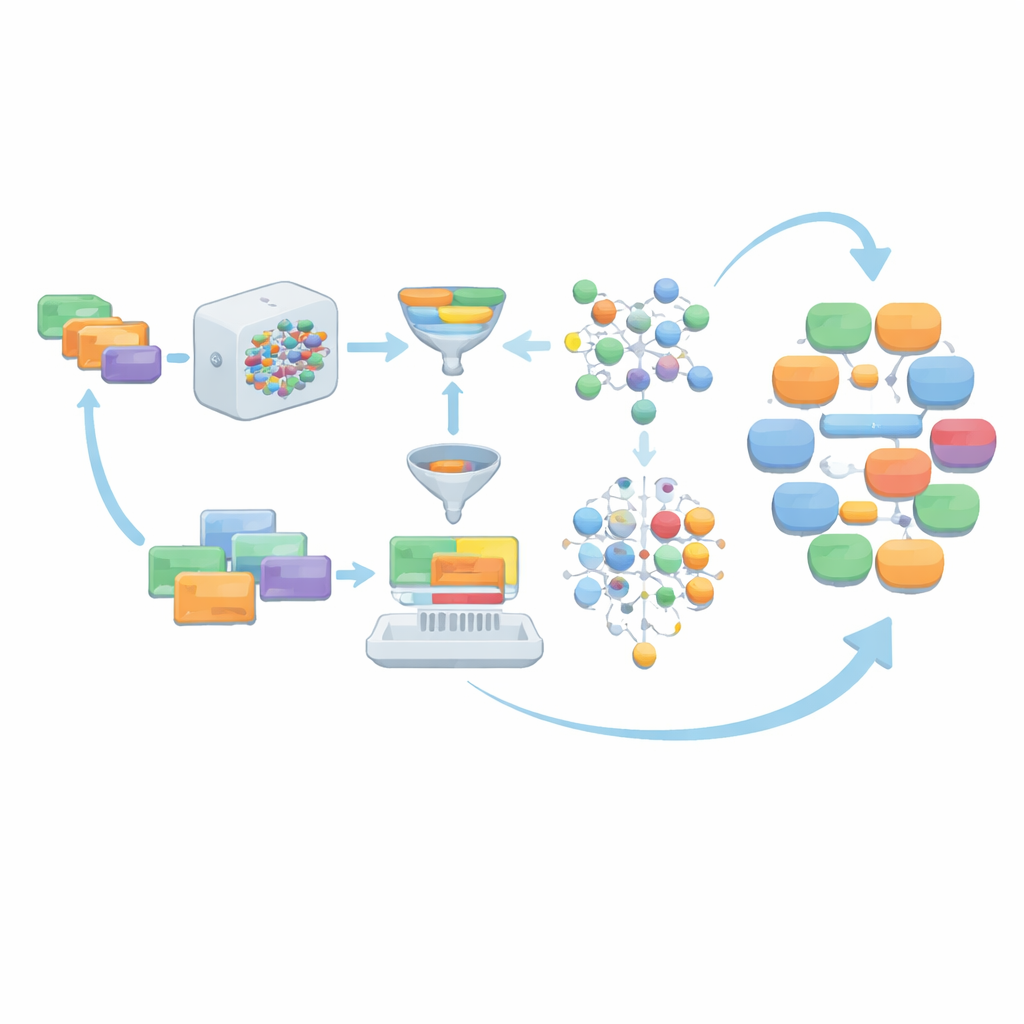
Когда языковая модель генерирует диалоги по этим инструкциям, сырой вывод не принимается как есть. Вместо этого он проходит несколько уровней очистки. Удаляется недиалоговый материал, такой как списки в виде записей или структурированные данные. Ролевые позиции стандартизируются в четыре основные пары отношений — врач–пациент, врач–медсестра, врач–врач и пациент–медсестра — чтобы соответствовать требованиям MCT. Затем команда проверяет, использует ли каждый диалог достаточное количество слов из официальной медицинской лексики MCT, достигает ли минимального числа ходов и находится ли в заданном диапазоне длины. Дополнительные инструменты грамматической коррекции при необходимости полируют язык. Диалоги, не прошедшие эти проверки, вместе с исходными инструкциями отбрасываются, чтобы в наборе оставались только качественные примеры.
Позволяя модели помогать писать лучшие подсказки
Вместо того чтобы вечно полагаться на изначально написанные людьми подсказки, AIG-MCT дает системе возможность учиться новым инструкциям на основе собственных результатов. У модели просят не только генерировать диалоги, но и предлагать новые машинно‑сгенерированные инструкции. Метод, называемый Maximal Marginal Relevance, используется для выбора инструкций, которые одновременно релевантны существующему пулу и заметно отличаются от уже имеющихся, путём сравнения схожести инструкций и их порождённых диалогов. Эти кандидатные инструкции затем кластеризуются алгоритмом K‑means, и из каждого кластера выбираются представительные, чтобы освежить пул инструкций. В ходе многих раундов доля вручную созданных подсказок постепенно уменьшается, а тщательно отобранные машинно‑сгенерированные подсказки берут на себя роль, сохраняя разнообразие без утраты соответствия правилам MCT.
Насколько хороша получившаяся коллекция медицинских бесед?
Для проверки подхода авторы использовали ChatGPT (gpt-3.5-turbo) в качестве основного генератора и специализированную медицинскую модель ZuoYi для проверки медицинского содержания. Они прогоняли этот процесс 40 раз, сочетая автоматические фильтры с экспертизой людей, и в итоге собрали датасет под названием MCT-Chat примерно из 20 000 многоходовых диалогов. Команда сравнила MCT-Chat с известными реальными китайскими наборами медицинских диалогов, такими как MedDialog, MedDG и DISC-Med-SFT. Объективные метрики показали, что MCT-Chat обладает высокой лексической разнообразностью и насыщенной формулировкой, при этом фокусируясь на целевом наборе болезней и симптомов, подходящих для экзамена. Набор также охватывает широкий спектр ролей, тем и задач, а типичная длина и число ходов хорошо соответствуют ожиданиям MCT.
Оценки экспертов и направления развития
Пять медицинских экспертов оценивали случайные выборки из MCT-Chat и сравниваемых наборов. Они выставляли баллы за беглость, справедливость, медицинскую корректность, соответствие требованиям MCT и способность различать уровни подготовки. MCT-Chat по большинству критериев показал результаты не хуже или немного лучше реальных наборов, особенно в рациональности и дискриминации при выставлении оценок, что говорит о том, что синтетические данные могут стать серьёзными кандидатами для экзаменационных материалов — хотя авторы подчёркивают, что любые реальные тестовые задания всё равно должны проходить строгую ручную проверку. Они также отмечают оставшиеся вызовы: модели всё ещё могут неверно интерпретировать сложные темы, а длинные диалоги без тщательного контроля могут скатиться в повторение. Авторы предлагают улучшить этап кластеризации, внедрить более продвинутые обновления знаний и расширить рамки на многоязычные и мультикультурные настройки, чтобы подобные экзамено‑ориентированные медицинские диалоговые наборы можно было создавать по всему миру.
Вывод для неспециалистов
Исследование показывает, что при правильных гарантиях и умных стратегиях выборки большие языковые модели могут помочь создавать реалистичные, безопасные с точки зрения конфиденциальности медицинские беседы, адаптированные к конкретному языковому экзамену. Сочетая официальные руководства, автоматические фильтры и экспертную проверку, авторы построили набор из 20 000 диалогов, тесно соответствующий требованиям Medical Chinese Test. Для пациентов и обучающихся это означает, что будущие врачи могут тренироваться и оцениваться с помощью синтетических, но правдоподобных диалогов, что уменьшит зависимость от чувствительных реальных данных, при этом готовя их к аутентичному общению в больнице.
Цитирование: Zhou, H., Hu, X., He, T. et al. LLM-based medical dialogue dataset generation with automated instructions. Sci Rep 16, 12410 (2026). https://doi.org/10.1038/s41598-025-34835-1
Ключевые слова: синтетический медицинский диалог, большие языковые модели, тест по медицинскому китайскому, генерация инструкций, медицинское языковое образование