Clear Sky Science · sv
Effekten av medicinska förklaringar från stora språkmodeller på diagnostisk noggrannhet inom radiologi
Varför denna studie är viktig
Moderna sjukhus inför snabbt kraftfulla textbaserade artificiella intelligensverktyg för att hjälpa läkare tolka komplex medicinsk information. Radiologer, som bedömer bilddiagnostik som CT- och MR-bilder, känner ständig press att leverera snabba och korrekta svar. Denna studie ställer en enkel men viktig fråga: om ett AI-system inte bara ger en diagnos utan också förklarar sitt resonemang, hjälper det då verkligen läkare att fatta bättre beslut — och vilken förklaringsstil fungerar bäst?
Olika sätt för AI att "prata" med läkare
Forskarna fokuserade på stora språkmodeller, eller LLM:er — AI-system som kan läsa och skriva naturligt språk och i det här fallet även tolka medicinska bilder. Istället för att behandla AI:n som en svart låda som levererar ett enda svar testade de tre olika sätt att presentera sina rekommendationer för radiologer. I ett format angav AI:n helt enkelt sin mest sannolika diagnos. I ett annat listade den flera möjliga diagnoser, ungefär som en läkares mentala checklista. I det tredje gick den igenom sitt resonemang steg för steg och visade hur detaljer från bilden och patientens berättelse ledde fram till slutsatsen. Teamet ville veta vilken av dessa förklaringsstilar som bäst stödjer mänskligt omdöme i stället för att ersätta det.
Stort test med fall från verklig radiologi
För att undersöka detta genomförde författarna ett randomiserat försök med 101 verksamma radiologer i USA. Varje radiolog granskade 20 verkliga patientfall hämtade från en utbildningsserie publicerad av en ledande medicinsk tidskrift. Varje fall innehöll en kort klinisk beskrivning plus en eller flera CT- eller MR-bilder, och läkarna fick skriva in en fri text-diagnos, precis som i verklig praxis. Vissa radiologer fick ingen AI-hjälp alls. Andra såg AI-råd i ett av de tre formaten: en ren diagnos, en rankad lista med fem möjliga diagnoser eller en detaljerad steg-för-steg-förklaring. Den AI som användes var en multimodal version av GPT-4 som kan hantera både text och bilder. Alla dess utsagor — inklusive misstag — visades oförändrade för att efterlikna användning i verkliga världen.
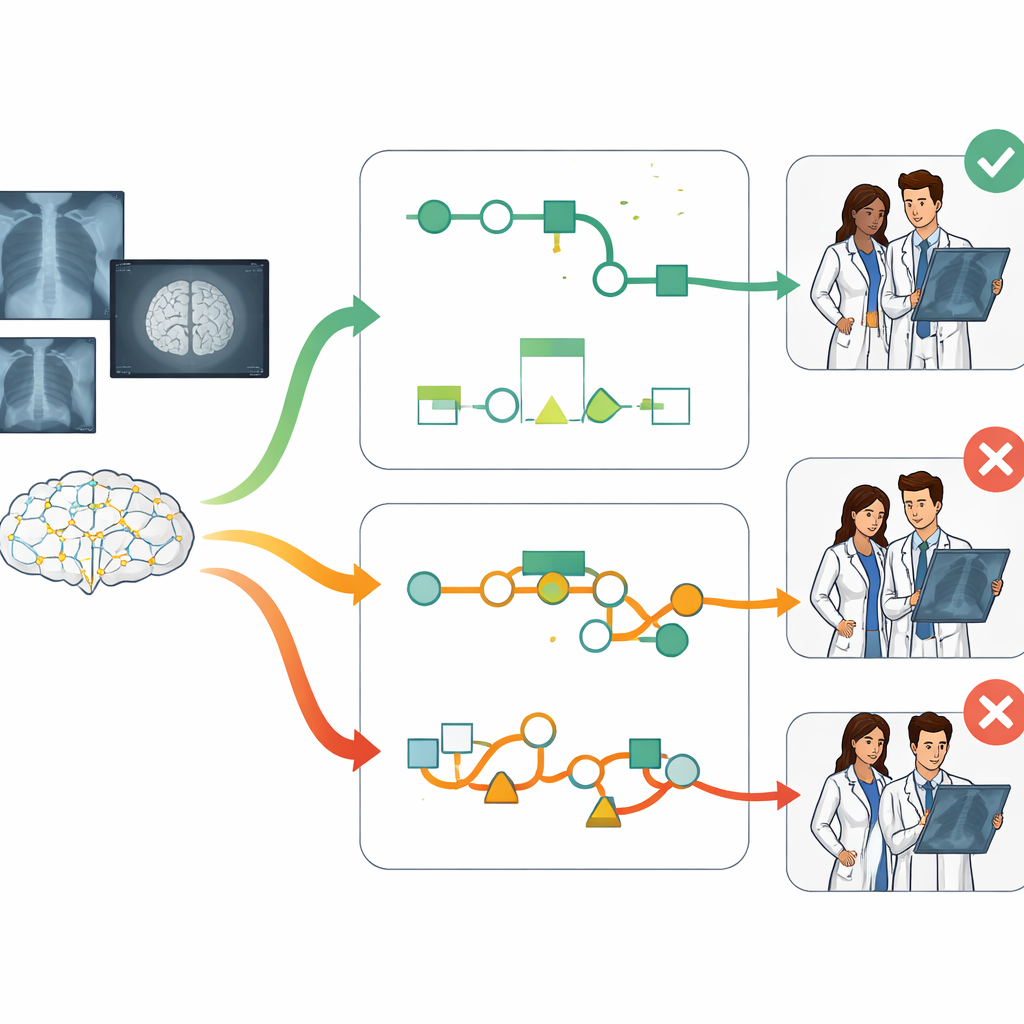
Steg-för-steg-resonemang ökar träffsäkerheten
Det centrala fyndet är tydligt: förklaringsstilen spelade stor roll. Radiologer som såg kedja-av-tanke-stilen — det stegvisa resonemanget — var märkbart mer träffsäkra än de som arbetade utan AI och också mer träffsäkra än de som bara såg en enda diagnos eller en lista med alternativ. I genomsnitt förbättrade kedja-av-tanke-stödet den diagnostiska noggrannheten med mer än 12 procentenheter jämfört med ingen AI-hjälp och med 7 till 10 enheter jämfört med de andra AI-formaten. Dessa förbättringar bestod även efter att man tagit hänsyn till faktorer som erfarenhetsår, subspecialitetsträning och hur lång tid läkarna spenderade på varje fall, vilket tyder på att sättet information presenteras på kan förändra hur väl läkare presterar.
Följa goda råd och avvisa dåliga
Studien granskade också hur läkarna reagerade när AI:n hade rätt respektive fel. Med differentialdiagnoslistan tenderade radiologerna att följa AI:ns toppförslag även när det var felaktigt, ett mönster av överdriven tillit känt som automation bias. I kontrast uppmuntrade kedja-av-tanke-formatet en mer selektiv förlitning. När AI:ns diagnos var korrekt var läkare mycket benägna att hålla med. Men när något i det stegvisa resonemanget verkade fel var de mer villiga att åsidosätta AI:n och välja ett annat svar. Med andra ord hjälpte detaljerat resonemang läkarna att bedöma när de skulle luta sig mot maskinen och när de skulle lita på sin egen expertis.
Robusta resultat över färdigheter och specialiteter
Fördelarna med steg-för-steg-förklaringar sågs i en rad olika situationer. Radiologer med både kortare och längre karriärer drog nytta, liksom de med grundläggande eller avancerade datorfärdigheter. Mönstret höll för både lättare och svårare fall och för både allmänradiologer och de som arbetar inom specialiserade områden, såsom neuroradiologi eller bukbildsdiagnostik. Författarna genomförde också många statistiska kontroller — med kontroll för AI:ns egen noggrannhet, längden på dess utsagor och olika modelleringsantaganden — och fann att överlägsenheten hos kedja-av-tanke-förklaringar var anmärkningsvärt stabil.
Vad detta betyder för patienter och framtida AI-verktyg
För patienter är budskapet försiktigt optimistiskt: AI kan hjälpa radiologer, men hur den kommunicerar sitt resonemang är avgörande. Att bara lista möjligheter eller ge ett självsäkert svar räcker inte och kan till och med driva läkare mot felaktiga val. I detta kontrollerade experiment hjälpte AI som "tänkter högt" i klar, stegvis form läkare att bättre avgöra när maskinen hade rätt och när den hade fel, vilket ledde till färre diagnostiska misstag totalt. När sjukhus fortsätter att integrera AI i kliniska arbetsflöden kan utformning av system som prioriterar transparenta, resonemangsorienterade förklaringar spela en nyckelroll för att göra medicinska diagnoser säkrare och mer tillförlitliga.
Citering: Spitzer, P., Hendriks, D., Rudolph, J. et al. The effect of medical explanations from large language models on diagnostic accuracy in radiology. npj Digit. Med. 9, 333 (2026). https://doi.org/10.1038/s41746-026-02619-0
Nyckelord: radiologisk diagnos, medicinsk AI, stora språkmodeller, tankeprocessförklaringar, kliniskt beslutsstöd