Clear Sky Science · sv
DMARS_WGO: en djup förstärkningsdriven hybrid-metaheuristik för intelligent adaptiv optimering
Smartare sökningar för komplexa problem
Från att utforma lättare flygplansdelar till att finjustera maskininlärningsmodeller, kan många moderna utmaningar kokas ner till samma fråga: hur söker vi igenom enorma mängder möjligheter för att hitta en verkligt bra lösning? Denna artikel presenterar en ny sorts "smart" sökmotor, kallad DMARS_WGO, som lär sig av erfarenhet medan den utforskar och hjälper ingenjörer och forskare att nå bättre konstruktioner snabbare och mer pålitligt.
Varför vanliga metoder inte räcker till
Traditionella optimeringstekniker, som gradientnedstigning och linjärprogrammering, fungerar bra endast när möjligheternas landskap är slätt och väluppförande. Riktiga ingenjörsproblem ser sällan ut så. De är ofta fulla av många toppar och dalar, plötsliga stup och högdimensionella tvära kast. I sådana skrovliga landskap kan klassiska metoder lätt fastna på en närliggande kulle istället för att hitta den djupaste dalen—den verkliga bästa lösningen. Under de senaste decennierna har forskare vänt sig till så kallade metaheuristiker, algoritmer inspirerade av naturen, fysik och mänskligt beteende. Dessa metoder förflyttar svärmar av kandidatlösningar genom landskapet, och imiterar fåglars flockbeteende, rovdjurs jakt eller material som svalnar. Trots sin kraft har många av dessa tekniker fortfarande svårt att balansera två konkurrerande behov: bred utforskning av nytt territorium och noggrann exploatering av lovande regioner.
Två djurmetaforer, en kärnidé
Författarna bygger vidare på två nyligen utvecklade djurinspirerade optimerare: Walrus Optimizer, som är bra på finjustering runt attraktiva platser (exploatering), och Gazelle Optimization Algorithm, som utmärker sig i bred, rörlig utforskning (utforskning). Tidigare arbete hade redan kombinerat dessa beteenden till hybrida metoder, men blandningen var till stor del hårdkodad: fasta formler eller scheman bestämde när man skulle ströva och när man skulle fokusera. Denna rigiditet gör att algoritmen kan antingen hoppa till slutsatser för tidigt eller irra omkring för länge, särskilt i mycket komplexa eller högdimensionella problem. Det nya arbetet föreställer sig denna valross–gasell-hybrid som ett system som inte bara rör sig, utan också lär sig hur det ska röra sig baserat på återkoppling från sökningen själv.
Att lägga in lärande i svärmen
Den första föreslagna metoden, AIRE_WGO, introducerar en inlärningsmekanism kallad Q‑inlärning. Istället för att följa ett fast manus observerar algoritmen enkla signaler från sin population av kandidatlösningar: hur utspridda de är (diversitet) och hur snabbt den bästa lösningen förbättras. Dessa observationer definierar sökningens nuvarande "tillstånd." För varje tillstånd upptäcker Q‑inlärningsmodulen gradvis om det är bättre att favorisera gasell-liknande utforskning eller valross-liknande exploatering. Framgångsrika beslut—de som leder till bättre lösningar—belönas, så systemet blir mer benäget att upprepa dem i liknande situationer. AIRE_WGO justerar dessutom sina interna steglängder och inför kontrollerade slumpmässiga mutationer när framsteg stannar upp, vilket hjälper den att komma ur återvändsgränder.
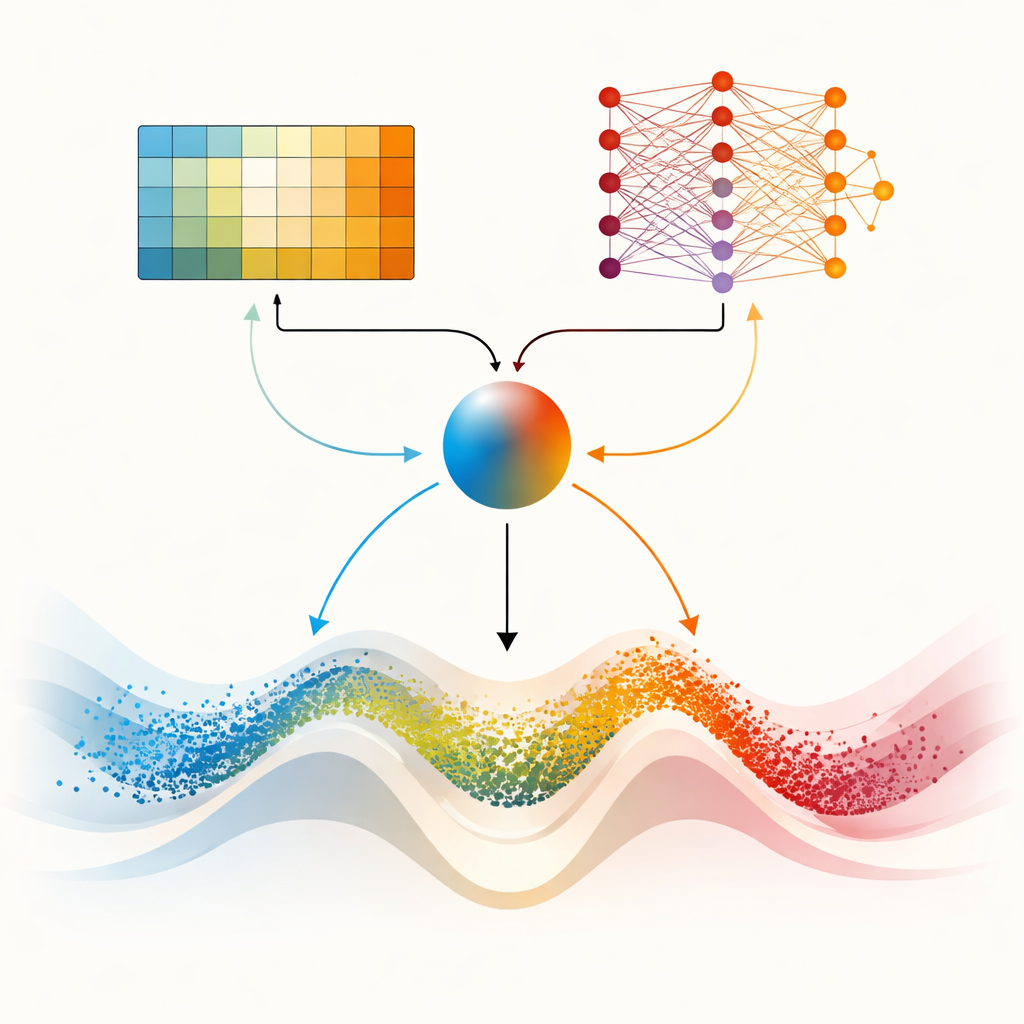
Två hjärnor för tuffare landskap
Artikelns mittpunkt är DMARS_WGO, som går ett steg längre genom att ge optimeraren två kompletterande inlärnings"hjärnor." Den ena är samma tabellbaserade Q‑inlärning som används i AIRE_WGO, enkel och snabb när situationen kan sammanfattas i ett fåtal grova kategorier. Den andra är ett Deep Q‑Network, ett litet neuralt nätverk som kan fånga mer subtila mönster i hur diversitet, förbättringstakt och stagnation relaterar till bra beslut. Vid varje iteration föreslår båda lärarna vad som ska göras—att luta mot gasell‑liknande strövande, valross‑liknande fokus eller en blandning av de två. En blandningskoefficient, beräknad utifrån aktuell diversitet, nyligen gjorda framsteg och tecken på fastkörning, väger smidigt deras förslag till en enda åtgärd. Information flödar också åt båda hållen: erfarenheter från den enklare läraren berikar nätverkets träningsdata, medan destillerad kunskap från nätverket periodvis förfinar den enklare lärarens beslutstabell. Denna samarbetskonfiguration hjälper optimeraren att kontinuerligt anpassa sitt beteende istället för att växla abrupt.
Sätter metoden på prov
För att avgöra om denna extra intelligens verkligen lönar sig, benchmarkar författarna DMARS_WGO mot två vitt använda testsatser (CEC 2017 och CEC 2022) och mot sex verkliga tekniska designuppgifter, inklusive fjädrar, tryckkärl, växellådor och stödkonstruktioner. Dessa problem är avsiktligt utmanande, med många missvisande lokala optimum och strikta konstruktionsbegränsningar. Över dussintals testfunktioner uppnår DMARS_WGO oftast den bästa genomsnittliga prestandan och visar mycket stabila resultat mellan körningar. Statistiska tester bekräftar att dess fördelar gentemot nio andra avancerade optimerare sannolikt inte beror på slumpen. Viktigt är att denna förbättrade prestanda inte kommer med en oöverstiglig beräkningskostnad: även om träning av ett neuralt nätverk lägger till viss overhead, domineras den totala insatsen fortfarande av utvärderingen av kandidatlösningar, precis som i standard svärmmetsoder.
Vad detta innebär i praktiken
För en icke‑specialist är huvudresultatet att DMARS_WGO beter sig som ett sökteam som lär sig i farten hur det bäst ska fördela sin tid mellan att spanare nytt territorium och att granska lovande fynd i detalj. Genom att noggrant övervaka tecken på framsteg och tecken på stagnation, och genom att låta två olika inlärningsmoduler styra dess rörelser, kan algoritmen mer pålitligt inrikta sig på högkvalitativa konstruktioner i svåra, högdimensionella rum. Detta gör den till en attraktiv byggsten för framtida ingenjörsverktyg som måste automatiskt finjustera komplexa system—från mekaniska komponenter till maskininlärningsmodeller—utan att kräva att en mänsklig expert mikrostyr varje söksteg.
Citering: Yousif, N.R., El-Gendy, E.M. & Haikal, A.Y. DMARS_WGO: a deep reinforcement-driven hybrid metaheuristic for intelligent adaptive optimization. Sci Rep 16, 13156 (2026). https://doi.org/10.1038/s41598-026-46134-4
Nyckelord: metaheuristisk optimering, förstärkningsinlärning, svärmintelligens, teknisk design, djupa Q-nätverk