Clear Sky Science · ar
DMARS_WGO: خوارزمية ميتاهيوريستية هجينة مدفوعة بالتعلّم التعزيزي العميق للتحسين التكيفي الذكي
بحث أذكى للمشكلات المعقدة
من تصميم أجزاء طائرات أخفّ إلى تعديل نماذج التعلم الآلي، تتلخّص العديد من التحديات الحديثة في سؤال واحد: كيف نبحث في فضاءات ضخمة من الاحتمالات لإيجاد حل جيد بالفعل؟ تقدّم هذه الورقة نوعًا جديدًا من «محركات البحث الذكية» يُدعى DMARS_WGO، يتعلم من التجربة أثناء استكشافه، مساعدًا المهندسين والعلماء على الوصول إلى تصاميم أفضل بسرعة أكبر وموثوقية أعلى.
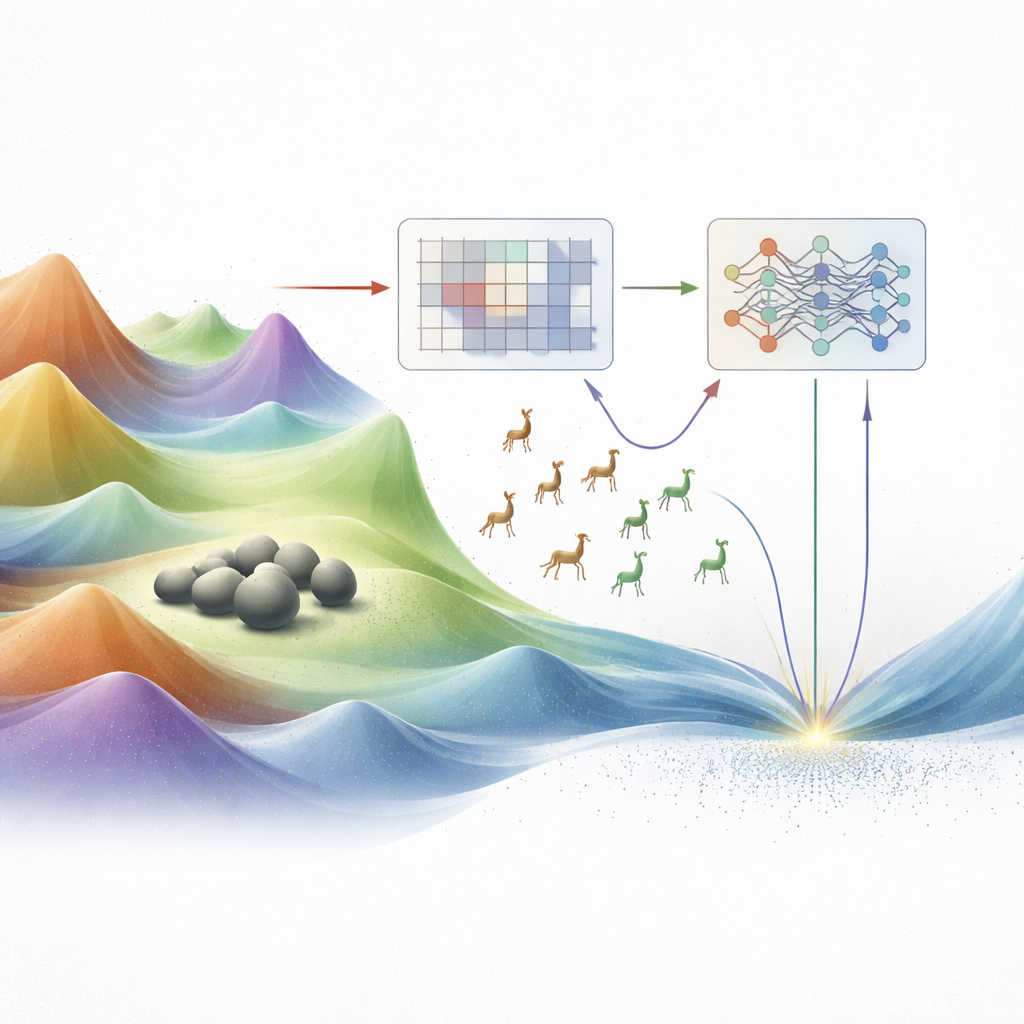
لماذا تفشل الطرق التقليدية
تعمل تقنيات التحسين التقليدية، مثل نزول التدرج والبرمجة الخطية، جيدًا فقط عندما تكون تضاريس الاحتمالات ناعمة وسهلة التصرف. نادرًا ما تبدو مشكلات الهندسة الحقيقية هكذا. ففي كثير من الأحيان تكون مليئة بالقمم والوديان المتعددة، والمنحدرات الحادة، وتعقيدات ذات أبعاد عالية. في مثل هذه المناظِر الوعِرة، قد تعلق الطرق الكلاسيكية على تلة قريبة بدلًا من العثور على الوادي الأعمق — الحل الأفضل الحقيقي. على مدار العقود القليلة الماضية، لجأ الباحثون إلى ما يُسمى بالميتاهيوريستيات، خوارزميات مستوحاة من الطبيعة والفيزياء والسلوك البشري. تحرّك هذه الأساليب أسرابًا من الحلول المحتملة عبر التضاريس، مقلدة تجمع الطيور، أو افتراس الحيوانات، أو تبريد المواد. ومع أنها فعّالة، إلا أن العديد من هذه التقنيات لا تزال تكافح لموازنة حاجتين متنافستين: الاستكشاف الواسع لأراضٍ جديدة والاستغلال الدقيق للمناطق الواعدة.
مجاز حيوانيان، وفكرة أساسية واحدة
يبني المؤلفون على منظّفين مستوحَين من الحيوانين الحديثين: مُحسّن الفظّ، الجيد في التكييف الدقيق حول البقع الجاذبة (استغلال)، وخوارزمية غزالة التحسين، المتفوّقة في التجوال الواسع والرشيق (استكشاف). سبق أن جمعت أعمال سابقة هذين السلوكين في طرق هجينة، لكن المزج كان غالبًا مُرمَّزًا بثبات: صِيَغ أو جداول ثابتة قرّرت متى يتجول النظام ومتى يركز. هذه الصلابة تعني أن الخوارزمية قد تستعجل الاستنتاجات أو تتجول بلا هدف لفترة طويلة، خاصة في مسائل معقّدة أو عالية الأبعاد. تعيد العمل الجديد تصور هذا الهجين الفظ–غزالة كنظام لا يكتفي بالحركة، بل يتعلم كيف يتحرك بناءً على ملاحظات مُستلَمة من البحث نفسه.
إضافة التعلّم إلى السرب
الطريقة المقترحة الأولى، AIRE_WGO، تُدرج آلية تعلم تدعى Q‑learning. بدلًا من اتباع سيناريو ثابت، تراقب الخوارزمية إشارات بسيطة من مجموعتها من الحلول المحتملة: مدى تشتّتها (التنوّع) ومدى سرعة تحسّن أفضل حل. تُعرّف هذه الملاحظات «حالة» البحث الحالية. لكل حالة، يكتشف مُكوّن Q‑learning تدريجيًا ما إذا كان من الأفضل تفضيل استكشاف على طريقة الغزالة أو استغلال على طريقة الفظّ. تُكافأ القرارات الناجحة — تلك التي تؤدي إلى حلول أفضل — فتصبح الخوارزمية أكثر ميلاً لتكرارها في حالات مماثلة. كما يضبط AIRE_WGO أحجام الخطوات الداخلية ويُدخل طفرات عشوائية مُسيطرًا عليها عند توقف التقدّم، مما يساعده على الفرار من الطرق المسدودة.
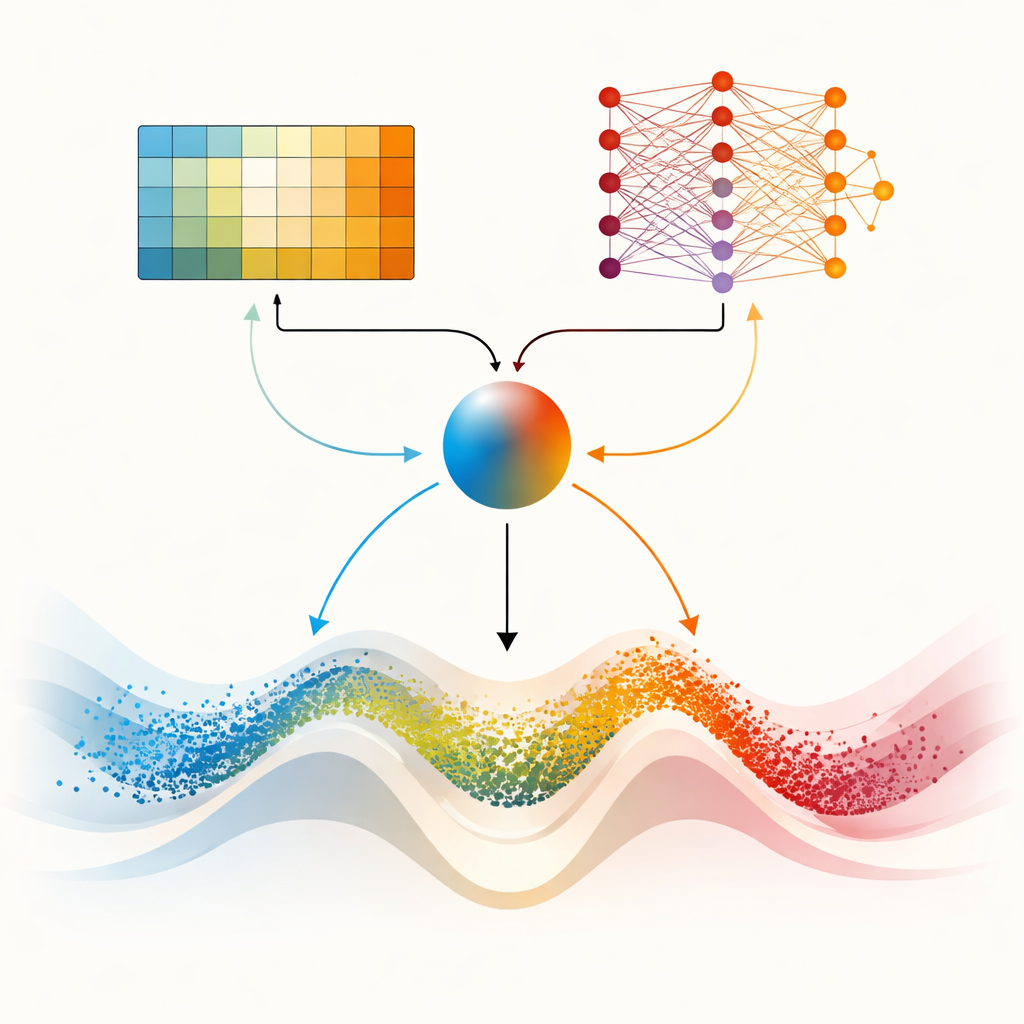
دماغان لواجهات أعقد
القطعة المركزية في الورقة هي DMARS_WGO، التي تأخذ خطوة أبعد بمنح المحسّن «دماغين» تعلّميين مكمّلين. أحدهما هو Q‑learning الجدولي المستخدم في AIRE_WGO، البسيط والسريع عندما يمكن تلخيص الوضع في فئات عامة قليلة. والآخر هو شبكة Q‑عميقة، شبكة عصبية صغيرة قادرة على التقاط أنماط أدق في كيفية ارتباط التنوّع ومعدل التحسّن والركود بقرارات جيدة. في كل تكرار، يقترح المتعلّمان ما يجب فعله — الميل إلى تجوال على نمط الغزالة، أو تركيز على نمط الفظّ، أو مزيج من الاثنين. معامل المزج، المُحتسَب من التنوّع الحالي والتقدّم الأخير ودلائل الركود، يوزِن اقتراحاتهما بسلاسة إلى فعل واحد. كما يتدفّق المعلومات في كلا الاتجاهين: تجارب المتعلّم الأبسط تغني بيانات تدريب الشبكة العصبية، بينما تُكرِر المعرفة المقطّرة من الشبكة جدول قرارات المتعلّم الأبسط دوريًا. هذا الترتيب التعاوني يساعد المحسّن على تعديل سلوكه باستمرار بدلًا من الانتقال المفاجئ.
اختبار الطريقة
للتحقق مما إذا كانت هذه الذكاء الإضافي مفيدًا فعلاً، يقيم المؤلفون DMARS_WGO على مجموعتي اختبارات شائعتين (CEC 2017 وCEC 2022) وعلى ست مهام تصميم هندسي حقيقية، بما في ذلك النوابض، أوعية الضغط، مجموعات الترس، والهياكل الحاملة. هذه المسائل صُمِّمت لتكون تحديًا متعمدًا، مع العديد من الأمثل المحلية المضلِّلة وقيود تصميم صارمة. عبر عشرات وظائف الاختبار، يحقق DMARS_WGO غالبًا أفضل أداء متوسط ويُظهر نتائج مستقرة جدًا من تشغيل لآخر. تؤكد الاختبارات الإحصائية أن تفوقه على تسعة محسنين متقدّمين آخرين من غير المحتمل أن يكون مصادفة. والأهم من ذلك، أن هذا التحسّن في الأداء لا يأتي بتكلفة حسابية باهظة: رغم أن تدريب الشبكة العصبية يضيف بعض العبء، فإن الجهد الكلّي لا يزال مُهيمنًا بتقييم التصاميم المرشّحة، كما هو الحال في أساليب السرب القياسية.
ما يعنيه هذا عمليًا
بالنسبة للقارئ غير المتخصّص، النتيجة الرئيسية أن DMARS_WGO يتصرّف مثل فريق بحث يتعلم أثناء العمل كيف يوزّع وقته بين الاستطلاع عن أراضٍ جديدة وفحص الاكتشافات الواعدة بتفصيل أكبر. من خلال مراقبة دلائل التقدّم والركود بدقة، والسماح لوحدتي تعلم مختلفتين بتوجيه حركاته، تستطيع الخوارزمية الاقتراب بثبات أكبر من تصاميم عالية الجودة في فضاءات صعبة وعالية الأبعاد. هذا يجعلها عنصرًا جذابًا لأدوات هندسية مستقبلية يجب أن تضبط أنظمة معقّدة تلقائيًا — من مكوّنات ميكانيكية إلى نماذج تعلّم آلي — دون الحاجة إلى خبير بشري يدير كل خطوة من خطوات البحث بدقة.
الاستشهاد: Yousif, N.R., El-Gendy, E.M. & Haikal, A.Y. DMARS_WGO: a deep reinforcement-driven hybrid metaheuristic for intelligent adaptive optimization. Sci Rep 16, 13156 (2026). https://doi.org/10.1038/s41598-026-46134-4
الكلمات المفتاحية: تحسين ميتاهيوريستي, التعلّم التعزيزي, ذكاء السرب, تصميم هندسي, شبكات Q العميقة