Clear Sky Science · en
DMARS_WGO: a deep reinforcement-driven hybrid metaheuristic for intelligent adaptive optimization
Smarter Search for Complex Problems
From designing lighter aircraft parts to tuning machine‑learning models, many modern challenges boil down to the same question: how do we search huge spaces of possibilities to find one really good solution? This paper introduces a new kind of "smart" search engine, called DMARS_WGO, that learns from experience as it explores, helping engineers and scientists reach better designs faster and with greater reliability.
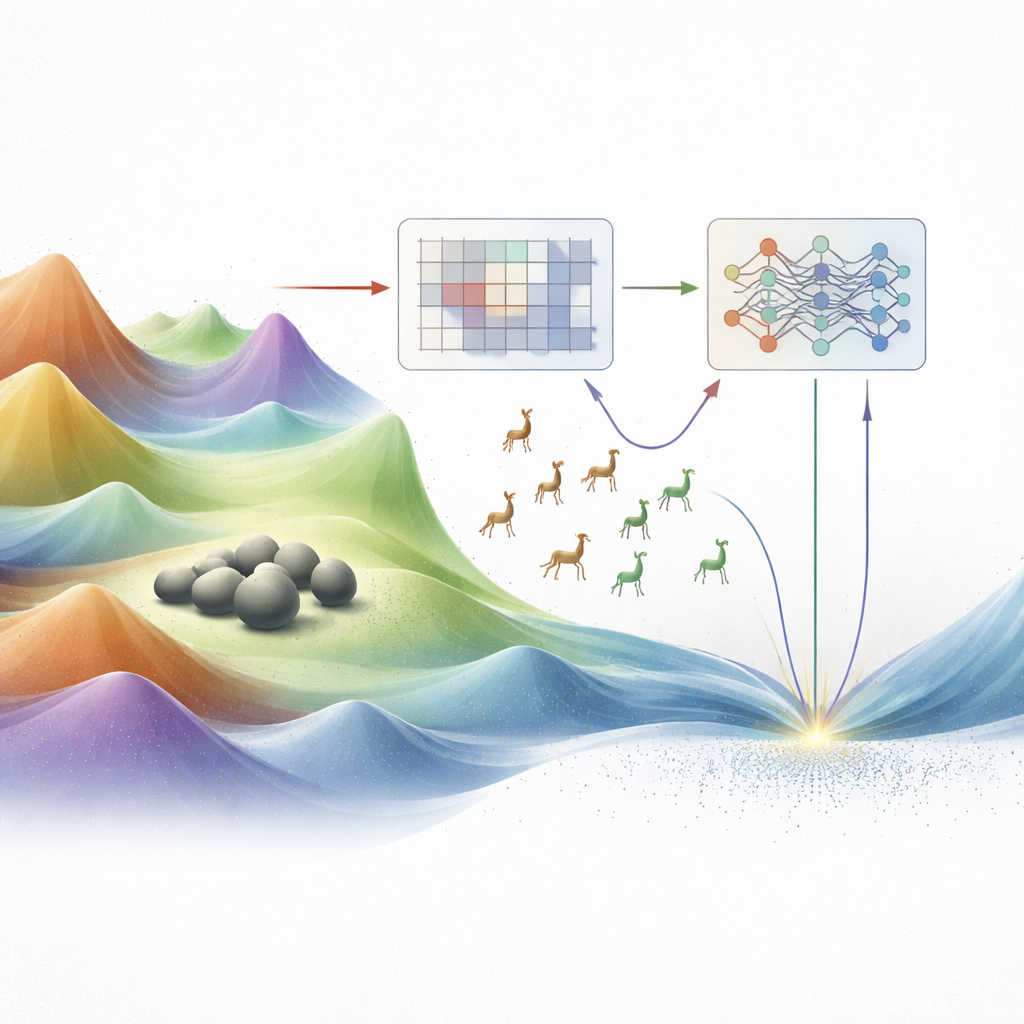
Why Ordinary Methods Fall Short
Traditional optimization techniques, such as gradient descent and linear programming, work well only when the terrain of possibilities is smooth and well behaved. Real engineering problems rarely look like that. They are often riddled with many peaks and valleys, sudden cliffs, and high dimensional twists. In such rugged landscapes, classical methods can easily get stuck on a nearby hill instead of finding the deepest valley—the true best solution. Over the past few decades, researchers have turned to so‑called metaheuristics, algorithms inspired by nature, physics, and human behavior. These methods move swarms of candidate solutions through the landscape, mimicking birds flocking, predators hunting, or materials cooling. While powerful, many of these techniques still struggle to balance two competing needs: broad exploration of new territory and careful exploitation of promising regions.
Two Animal Metaphors, One Core Idea
The authors build on two recent animal‑inspired optimizers: the Walrus Optimizer, which is good at fine‑tuning around attractive spots (exploitation), and the Gazelle Optimization Algorithm, which excels at wide, nimble roaming (exploration). Earlier work had already combined these behaviors into hybrid methods, but the mix was largely hard‑coded: fixed formulas or schedules decided when to roam and when to focus. This rigidity means the algorithm can still either jump to conclusions too early or wander aimlessly for too long, especially on very complex or high‑dimensional problems. The new work reimagines this walrus–gazelle hybrid as a system that does not just move, but also learns how to move based on feedback from the search itself.
Adding Learning to the Swarm
The first proposed method, AIRE_WGO, introduces a learning mechanism called Q‑learning. Instead of following a fixed script, the algorithm observes simple signals from its population of candidate solutions: how spread out they are (diversity) and how quickly the best solution is improving. These observations define the current "state" of the search. For each state, the Q‑learning module gradually discovers whether it is better to favor gazelle‑style exploration or walrus‑style exploitation. Successful decisions—those that lead to better solutions—are rewarded, so the system becomes more likely to repeat them in similar situations. AIRE_WGO further adjusts its internal step sizes and introduces controlled random mutations when progress stalls, helping it escape from dead ends.
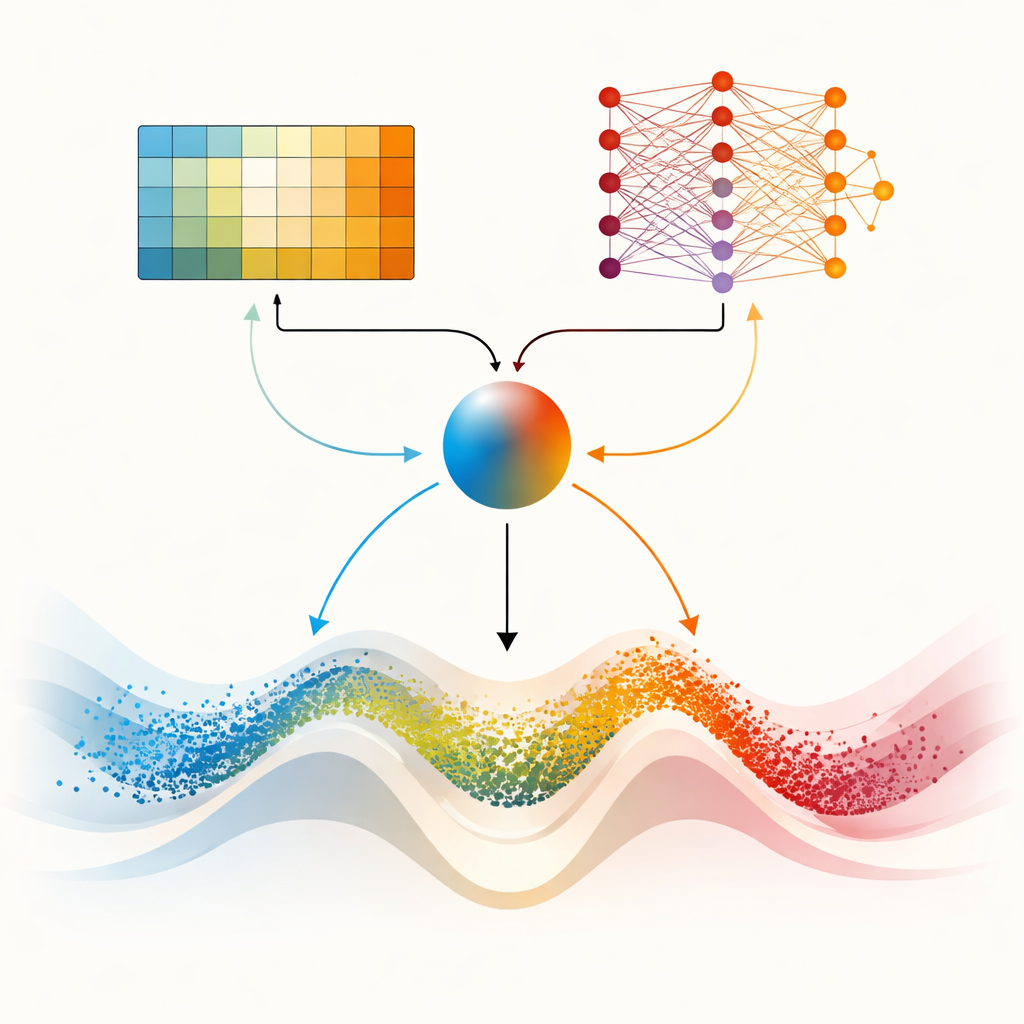
Dual Brains for Tougher Landscapes
The centerpiece of the paper is DMARS_WGO, which goes a step further by giving the optimizer two complementary learning "brains." One is the same tabular Q‑learning used in AIRE_WGO, which is simple and fast when the situation can be summarized in a few coarse categories. The other is a Deep Q‑Network, a small neural network that can capture subtler patterns in how diversity, improvement rate, and stagnation relate to good decisions. At every iteration, both learners propose what to do—lean on gazelle‑like roaming, walrus‑like focusing, or a blend of the two. A blending coefficient, computed from current diversity, recent progress, and signs of getting stuck, smoothly weights their suggestions into a single action. Information also flows both ways: experiences from the simpler learner enrich the neural network’s training data, while distilled knowledge from the network periodically refines the simpler learner’s decision table. This cooperative setup helps the optimizer adapt its behavior continuously rather than switching abruptly.
Putting the Method to the Test
To see whether this extra intelligence really pays off, the authors benchmark DMARS_WGO on two widely used test suites (CEC 2017 and CEC 2022) and on six real engineering design tasks, including springs, pressure vessels, gear trains, and support structures. These problems are deliberately challenging, with many misleading local optima and strict design constraints. Across dozens of test functions, DMARS_WGO most often achieves the best average performance and shows very stable results from run to run. Statistical tests confirm that its advantages over nine other advanced optimizers are unlikely to be due to chance. Importantly, this improved performance does not come with a prohibitive computational cost: although training a neural network adds some overhead, the overall effort is still dominated by evaluating candidate designs, just as in standard swarm methods.
What This Means in Practice
For a non‑specialist, the key outcome is that DMARS_WGO behaves like a search team that learns, on the fly, how best to divide its time between scouting new territory and examining promising finds in detail. By carefully monitoring signs of progress and signs of stagnation, and by letting two different learning modules guide its moves, the algorithm can more reliably home in on high‑quality designs in difficult, high‑dimensional spaces. This makes it an attractive building block for future engineering tools that must automatically tune complex systems—from mechanical components to machine‑learning models—without requiring a human expert to micromanage every search step.
Citation: Yousif, N.R., El-Gendy, E.M. & Haikal, A.Y. DMARS_WGO: a deep reinforcement-driven hybrid metaheuristic for intelligent adaptive optimization. Sci Rep 16, 13156 (2026). https://doi.org/10.1038/s41598-026-46134-4
Keywords: metaheuristic optimization, reinforcement learning, swarm intelligence, engineering design, deep Q networks