Clear Sky Science · de
DMARS_WGO: eine tief verstärkungsgetriebene hybride Metaheuristik für intelligente adaptive Optimierung
Intelligenteres Suchen bei komplexen Problemen
Ob es darum geht, leichtere Flugzeugteile zu entwerfen oder Machine‑Learning‑Modelle abzustimmen: Viele moderne Herausforderungen lassen sich auf dieselbe Frage zurückführen — wie durchsucht man riesige Möglichkeitsräume, um eine wirklich gute Lösung zu finden? Dieses Papier stellt eine neue Art von „intelligenter“ Suchmaschine vor, genannt DMARS_WGO, die beim Erkunden aus Erfahrung lernt und so Ingenieurinnen und Ingenieure sowie Wissenschaftlerinnen und Wissenschaftler dabei unterstützt, schneller und verlässlicher zu besseren Entwürfen zu gelangen.
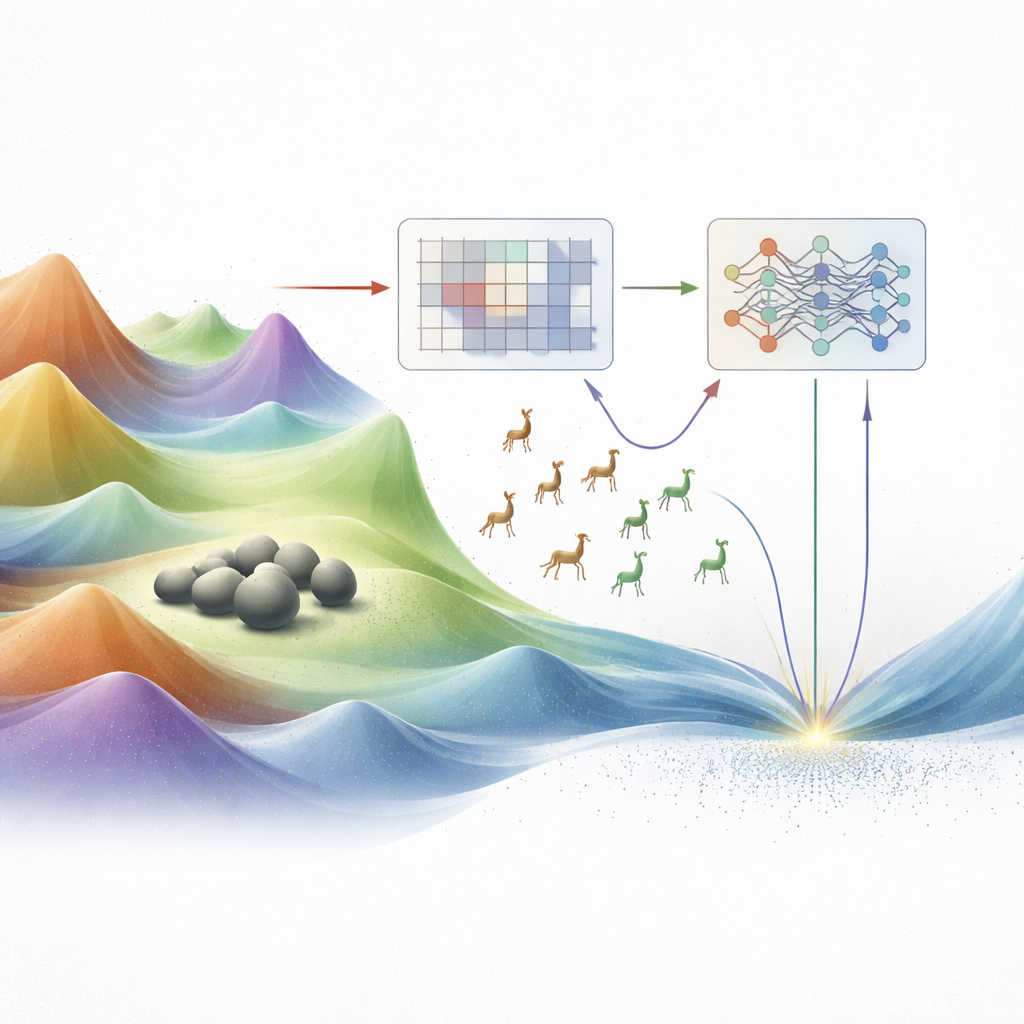
Warum herkömmliche Methoden versagen
Traditionelle Optimierungstechniken wie Gradientenabstieg und lineare Programmierung funktionieren gut, wenn die Lösungslandschaft glatt und wohlwollend ist. Reale Ingenieursprobleme sehen selten so aus. Sie sind oft mit vielen Gipfeln und Tälern, steilen Klippen und hochdimensionalen Windungen durchsetzt. In solchen zerklüfteten Landschaften können klassische Methoden leicht auf einem nahen Hügel stecken bleiben, statt das tiefste Tal — die wirklich beste Lösung — zu finden. In den vergangenen Jahrzehnten wandten sich Forschende daher sogenannten Metaheuristiken zu, von der Natur, der Physik und menschlichem Verhalten inspirierte Algorithmen. Diese bewegen Schwärme von Kandidatenlösungen durch die Landschaft, ahmen Vogelzüge, Jägerverhalten oder das Abkühlen von Materialien nach. Trotz ihrer Leistungsfähigkeit haben viele dieser Verfahren weiterhin Schwierigkeiten, zwei konkurrierende Bedürfnisse auszubalancieren: weite Erkundung neuen Terrains und sorgfältige Ausnutzung vielversprechender Regionen.
Zwei Tiermetaphern, eine Kernidee
Die Autorinnen und Autoren bauen auf zwei jüngeren, tierinspirierten Optimierern auf: dem Walrus Optimizer, der gut darin ist, um attraktive Stellen feinzujustieren (Exploitation), und dem Gazelle Optimization Algorithm, der sich durch weite, flinke Erkundung auszeichnet (Exploration). Frühere Arbeiten kombinierten diese Verhaltensweisen bereits in Hybridmethoden, doch die Mischung war weitgehend fest verdrahtet: feste Formeln oder Zeitpläne entschieden, wann man umherstreift und wann man sich fokussiert. Diese Starrheit kann dazu führen, dass der Algorithmus zu früh voreilige Schlüsse zieht oder zu lange ziellos umherwandert, besonders bei sehr komplexen oder hochdimensionalen Problemen. Die neue Arbeit stellt dieses Walross–Gazelle‑Hybrid als ein System dar, das sich nicht nur bewegt, sondern auf Basis von Rückmeldungen aus der Suche lernt, wie es sich bewegen soll.
Lernen für den Schwarm hinzufügen
Die erste vorgeschlagene Methode, AIRE_WGO, führt einen Lernmechanismus ein, der als Q‑Learning bekannt ist. Anstatt einem festen Drehbuch zu folgen, beobachtet der Algorithmus einfache Signale aus seiner Population von Kandidatenlösungen: wie weit sie verteilt sind (Diversität) und wie schnell sich die beste Lösung verbessert. Diese Beobachtungen definieren den aktuellen „Zustand“ der Suche. Für jeden Zustand entdeckt das Q‑Learning‑Modul allmählich, ob es besser ist, gazellenähnliche Erkundung oder walrossähnliche Ausnutzung zu bevorzugen. Erfolgreiche Entscheidungen — die zu besseren Lösungen führen — werden belohnt, sodass das System in ähnlichen Situationen eher dazu neigt, sie zu wiederholen. AIRE_WGO passt außerdem seine internen Schrittweiten an und führt kontrollierte zufällige Mutationen ein, wenn der Fortschritt ins Stocken gerät, um aus Sackgassen zu entkommen.
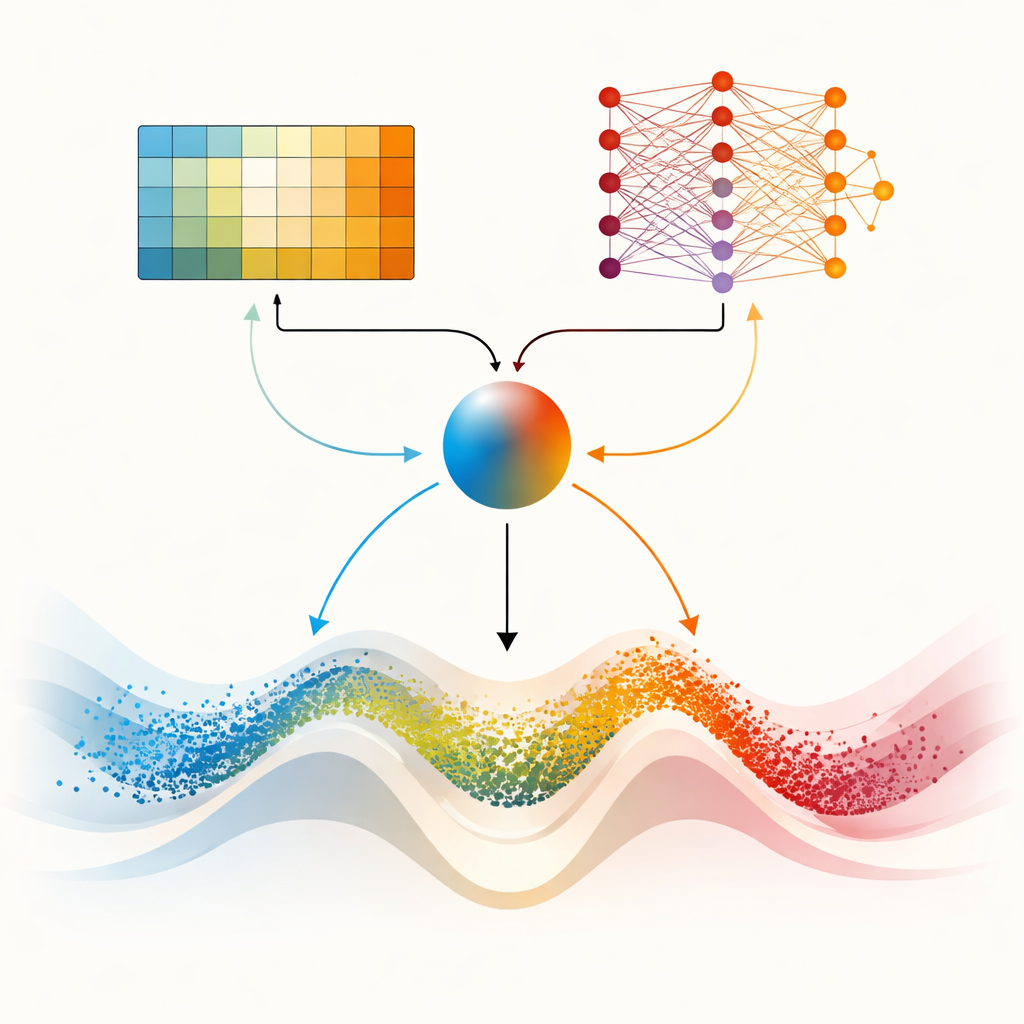
Doppelte Gehirne für schwierigere Landschaften
Der Kernbeitrag des Papiers ist DMARS_WGO, das einen Schritt weitergeht, indem es dem Optimierer zwei komplementäre Lern‑„Gehirne“ gibt. Das eine ist dasselbe tabellarische Q‑Learning wie in AIRE_WGO, das einfach und schnell ist, wenn sich die Situation in wenigen groben Kategorien zusammenfassen lässt. Das andere ist ein Deep‑Q‑Network, ein kleines neuronales Netz, das subtilere Muster erfassen kann, wie Diversität, Verbesserungsrate und Stagnation mit guten Entscheidungen zusammenhängen. Bei jeder Iteration schlagen beide Lerner vor, was zu tun ist — mehr gazellenartiges Umherstreifen, walrossartiges Fokussieren oder eine Mischung aus beidem. Ein Mischkoeffizient, berechnet aus aktueller Diversität, jüngstem Fortschritt und Anzeichen von Stocken, gewichtet ihre Vorschläge zu einer einzigen Aktion. Informationen fließen auch in beide Richtungen: Erfahrungen des simplereren Lerners bereichern die Trainingsdaten des neuronalen Netzes, während destilliertes Wissen aus dem Netz periodisch die Entscheidungstabelle des einfachen Lerners verfeinert. Dieses kooperative Setup hilft dem Optimierer, sein Verhalten kontinuierlich anzupassen, statt abrupt umzuschalten.
Das Verfahren im Praxistest
Um zu prüfen, ob diese zusätzliche Intelligenz wirklich etwas bringt, testen die Autorinnen und Autoren DMARS_WGO an zwei weit verbreiteten Test‑Suiten (CEC 2017 und CEC 2022) sowie an sechs realen Ingenieursentwurfsaufgaben, darunter Federn, Druckbehälter, Zahnradgetriebe und Tragwerke. Diese Probleme sind bewusst herausfordernd, mit vielen irreführenden lokalen Optima und strengen Konstruktionsbeschränkungen. Über Dutzende Testfunktionen erreicht DMARS_WGO am häufigsten die beste mittlere Leistung und zeigt sehr stabile Ergebnisse von Lauf zu Lauf. Statistische Tests bestätigen, dass seine Vorteile gegenüber neun anderen fortgeschrittenen Optimierern wahrscheinlich nicht zufällig sind. Wichtig ist, dass diese verbesserte Leistung nicht mit prohibitivem Rechenaufwand erkauft wird: Obwohl das Training eines neuronalen Netzes zusätzlichen Overhead verursacht, wird der Gesamtaufwand immer noch größtenteils von der Bewertung der Kandidatenentwürfe dominiert, wie bei standardmäßigen Schwarmverfahren.
Was das in der Praxis bedeutet
Für Nicht‑Spezialistinnen und Nicht‑Spezialisten ist das wichtigste Ergebnis, dass DMARS_WGO sich verhält wie ein Suchteam, das in Echtzeit lernt, wie es seine Zeit am besten zwischen Ausschauhalten nach neuem Terrain und genauer Untersuchung vielversprechender Funde aufteilt. Indem es sorgfältig Fortschritts‑ und Stagnationszeichen überwacht und zwei verschiedene Lernmodule seine Schritte leiten lässt, kann der Algorithmus zuverlässiger hochwertige Entwürfe in schwierigen, hochdimensionalen Räumen anvisieren. Das macht ihn zu einem attraktiven Baustein für künftige Ingenieurwerkzeuge, die komplexe Systeme — von mechanischen Komponenten bis zu Machine‑Learning‑Modellen — automatisch abstimmen müssen, ohne dass ein menschlicher Experte jeden Suchschritt mikromanagen muss.
Zitation: Yousif, N.R., El-Gendy, E.M. & Haikal, A.Y. DMARS_WGO: a deep reinforcement-driven hybrid metaheuristic for intelligent adaptive optimization. Sci Rep 16, 13156 (2026). https://doi.org/10.1038/s41598-026-46134-4
Schlüsselwörter: metaheuristische Optimierung, verstärkendes Lernen, Schwarmintelligenz, Ingenieursdesign, Deep-Q-Netzwerke