Clear Sky Science · he
DMARS_WGO: מטא-אִי-הרברידי מבוסס חיזוק עמוק לאופטימיזציה אדפטיבית חכמה
חיפוש חכם יותר לבעיות מורכבות
מעיצוב חלקי מטוסים קלים יותר ועד כוונון מודלים של למידת מכונה — הרבה מהאתגרים המודרניים מתמצים בשאלה אחת: איך נחקור מרחבי אפשרויות עצומים כדי למצוא פתרון באמת טוב? המאמר מציג מנוע חיפוש "חכם" חדש, שנקרא DMARS_WGO, שלומד מניסיון בזמן שהוא חוקר, ועוזר למהנדסים ולמדענים להגיע לעיצובים טובים יותר מהר יותר ובאמינות גבוהה יותר.
מדוע השיטות הרגילות לא מספקות
טכניקות אופטימיזציה מסורתיות, כמו ירידת גרדיאנט ותכנות ליניארי, עובדות היטב רק כששטח האפשרויות חלק ומתנהג כצפוי. בעיות הנדסיות אמיתיות נדירות כל כך. הן לרוב מלאות בפסגות ועמקים רבים, מצוקים פתאומיים ועיוותים בממד גבוה. בנוף קשוח כזה, שיטות קלאסיות עלולות להיתקע על גבעה קרובה במקום למצוא את העמק העמוק — הפתרון האמיתי הטוב ביותר. בעשרות השנים האחרונות פנו החוקרים למטא-היוריסטיקות, אלגוריתמים בהשראת טבע, פיזיקה והתנהגות אנושית. שיטות אלה מזיזות להקות של פתרונות מועמדים בנוף, מחקות עופות העפים בקבוצה, טורפים הצדים או תהליכי קירור של חומרים. למרות כוחן, רבות מהטכניקות הללו מתקשות עדיין לאזן בין שתי צרכים מתחרים: חקירה רחבה של תחומים חדשים וניצול זהיר של אזורים מבטיחים.
שני מטפורות חיות, רעיון מרכזי אחד
המחברים בונים על שני מטא-אופטימיזרים בהשראת בעלי חיים: Walrus Optimizer, המצויין בכיוונון עדין סביב נקודות אטרקטיביות (ניצול), ו-Gazelle Optimization Algorithm, שמתבלט בריחוף רחב ומהיר (חקירה). עבודות מוקדמות כבר שילבו התנהגויות אלה לשיטות היברידיות, אך התערובת היתה ברובה מוצקה מראש: נוסחאות או לוחות זמנים קבועים קבעו מתי לנוע ומתי להתמקד. נוקשות זו גורמת לכך שהאלגוריתם עדיין עלול להסיק מסקנות מוקדמות מדי או לשוטט ללא מטרה זמן ממושך, במיוחד בבעיות מורכבות או רב-ממדיות. העבודה החדשה מדמיינת מחדש את ההיבריד של כלבי הים והגזלים כמערכת שלא רק נעה, אלא גם לומדת איך לנוע בהתבסס על משוב מהחיפוש עצמו.
הוספת למידה ללהקה
השיטה הראשונה שהוצעה, AIRE_WGO, מציגה מנגנון למידה בשם Q‑learning. במקום לפעול לפי תסריט קבוע, האלגוריתם צופה באותות פשוטים מאוכלוסיית הפתרונות שלו: עד כמה הם מפוזרים (גיוון) וכמה מהר הפתרון הטוב ביותר משתפר. תצפיות אלה מגדירות את "המדינה" הנוכחית של החיפוש. עבור כל מדינה, מודול ה-Q‑learning מגלף בהדרגה האם עדיף להעדיף חקירה בסגנון גזל או ניצול בסגנון כלב ים. החלטות מוצלחות — אלו שמובילות לפתרונות טובים יותר — זוכות לתגמול, כך שהמערכת הופכת סבירה לחזור עליהן במצבים דומים. AIRE_WGO גם מתאימה גדלי צעד פנימיים ומציגה מוטציות אקראיות מבוקרות כאשר ההתקדמות נעצרת, מה שעוזר לה לצאת ממשברים.
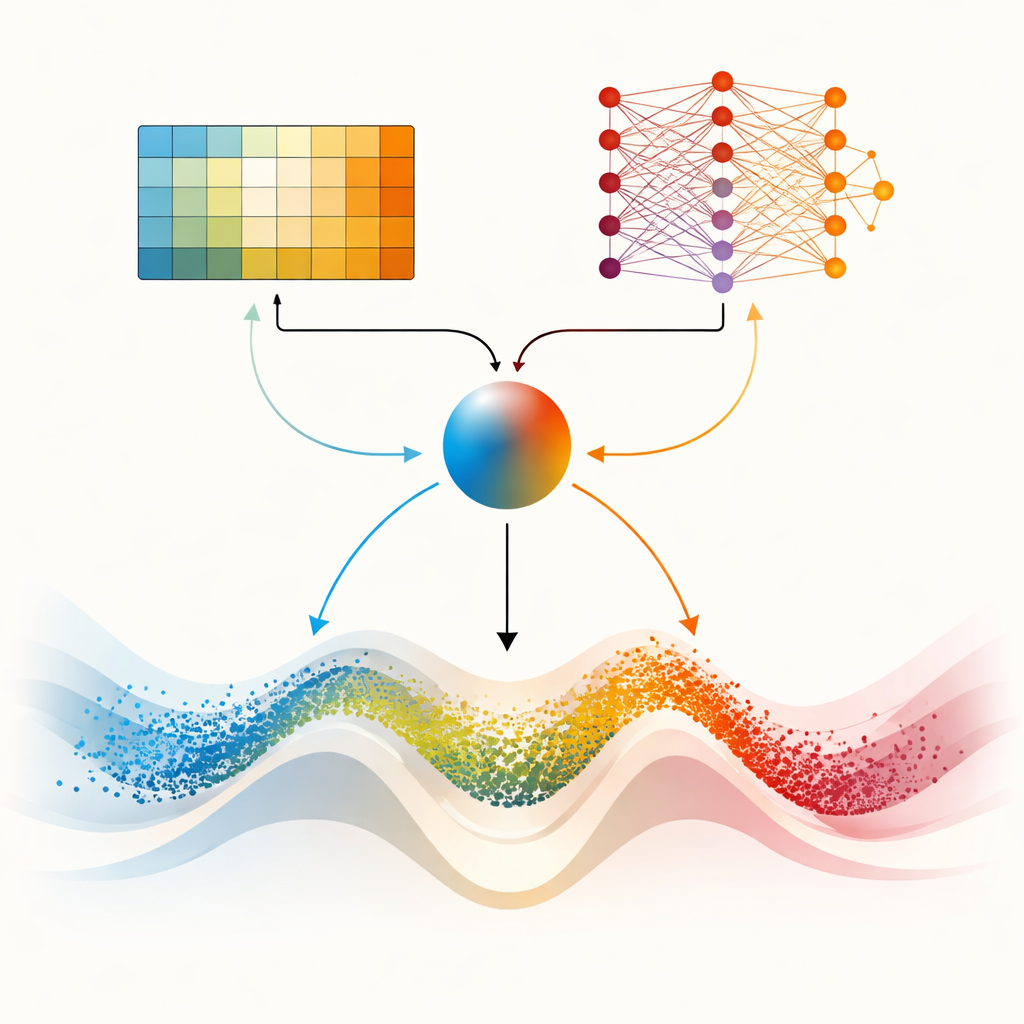
שני מוחות לנופים קשים יותר
החידוש המרכזי במאמר הוא DMARS_WGO, שמקדם את הרעיון על ידי הענקת שני "מוחות" למידה משלימים לאופטימייזר. אחד הוא אותו Q‑learning טבלאי ששומש ב-AIRE_WGO, פשוט ומהיר כאשר המצב ניתן לסיכום בכמה קטגוריות גסות. האחר הוא רשת Q‑עמוקה, רשת עצבית קטנה היכולה לתפוס דפוסים עדינים יותר בקשר בין גיוון, קצב שיפור והיתקעות להחלטות טובות. בכל איטרציה, שני הלומדים מציעים מה לעשות — להעדיף ריחוף בסגנון גזל, מיקוד בסגנון כלב ים, או שילוב של השניים. מקדם מיזוג, המחושב מתוך הגיוון הנוכחי, ההתקדמות האחרונה וסימנים של תקיעות, משקלל בצורה חלקה את ההצעות שלהם לפעולה אחת. המידע זורם גם בכיוון ההפוך: חוויות מהלומד הפשוט מעשירות את נתוני האימון של הרשת, בעוד ידע מזוקק מהרשת מעודן מדי פעם את טבלת ההחלטות של הלומד הפשוט. תצורה שיתופית זו עוזרת לאופטימייזר להסתגל להתנהגותו ברציפות במקום לעבור בין מצבים בקפיצה.
מבחנים לשיטה
כדי לבדוק האם התוספת הזאת של אינטיליגנציה באמת משתלמת, המחברים בוחנים את DMARS_WGO על שתי סוויטות מבחן נפוצות (CEC 2017 ו-CEC 2022) ועל שישה משימות תכנון הנדסיות אמיתיות, כולל קפיצים, מכלי לחץ, מערכות הילוכים ומבני תמיכה. בעיות אלה תוכננו להיות מאתגרות במיוחד, עם רבים של אופטימיזציות מקומיות מטעות ומגבלות עיצוב מחמירות. על פני עשרות פונקציות מבחן, DMARS_WGO בדרך כלל משיג את הביצוע הממוצע הטוב ביותר ומציג תוצאות יציבות מאוד מריצה לריצה. בדיקות סטטיסטיות מאשרות שיתרונותיו על פני תשעת אופימייזרים מתקדמים אחרים אינם סביר שהן תוצאה של מזל. חשוב לציין ששיפור זה בביצועים אינו מגיע במחיר חישובי אסור: אף על פי שאימון רשת עצבית מוסיף עלות מסוימת, המאמץ הכולל נשלט עדיין על ידי הערכת העיצובים המועמדים, בדיוק כמו בשיטות להקה סטנדרטיות.
מה המשמעות בפועל
בעבור מי שאינו מומחה, התוצאה המרכזית היא ש-DMARS_WGO מתנהג כמו צוות חיפוש שלומד בזמן אמת איך לחלק את זמנו בין סיור בשטח חדש ובין בחינה מעמיקה של ממצאים מבטיחים. על ידי מעקב מדוקדק אחר סימני התקדמות וסימני היתקעות, ובהיעזרות בשני מודולי למידה שונים המנחים את תנועותיו, האלגוריתם יכול להתמקד בצורה אמינה יותר בעיצובים איכותיים במרחבים קשים ורב-ממדיים. זה הופך אותו לבניין אטרקטיבי עבור כלים הנדסיים עתידיים שחייבים לכייל אוטומטית מערכות מורכבות — מרכיבים מכניים ועד מודלי למידת מכונה — מבלי להעמיס על מומחה אנושי לשלוט בכל שלב בחיפוש.
ציטוט: Yousif, N.R., El-Gendy, E.M. & Haikal, A.Y. DMARS_WGO: a deep reinforcement-driven hybrid metaheuristic for intelligent adaptive optimization. Sci Rep 16, 13156 (2026). https://doi.org/10.1038/s41598-026-46134-4
מילות מפתח: אופטימיזציה מטא-היוריסטית, למידת חיזוק, אינטליגנציה מושבית, תכנון הנדסי, רשתות Q עמוקות