Clear Sky Science · ja
DMARS_WGO: インテリジェントな適応最適化のための深層強化学習駆動ハイブリッドメタヒューリスティック
複雑な問題に対するより賢い探索
航空機部品の軽量化から機械学習モデルのチューニングまで、多くの現代的課題は結局同じ問いに行き着きます:膨大な可能性の空間をどう探索して本当に優れた解を見つけるか。本稿はDMARS_WGOと呼ばれる新しいタイプの「賢い」探索エンジンを提示します。これは探索の過程で経験から学習し、設計者や科学者がより良い設計により速く、より確実に到達するのを助けます。
従来手法が及ばない理由
勾配降下法や線形計画法のような従来の最適化手法は、可能性の地形が滑らかで扱いやすい場合には有効です。しかし現実の工学問題はめったにそのような形をしていません。多くの山や谷、突然の崖、高次元ならではの複雑さに満ちています。こうしたでこぼこしたランドスケープでは、古典的手法は近傍の小さな丘に捕らわれてしまい、本当の最良解(最深の谷)を見逃しがちです。ここ数十年で研究者は自然や物理、人間行動に着想を得たメタヒューリスティックに目を向けてきました。これらは候補解の群れを動かして、鳥の群れや捕食者の狩り、物質の冷却のような振る舞いを模します。強力ではあるものの、多くの手法は新しい領域の広範な探索と、有望領域の慎重な活用という二つの相反する要求のバランスに苦労します。
二つの動物メタファー、一つの核心アイデア
著者らは二つの動物に着想を得た最近の最適化法を基にしています。ウォラス最適化(Walrus Optimizer)は有望な箇所の微調整(活用)が得意で、ガゼル最適化アルゴリズム(Gazelle Optimization Algorithm)は広く俊敏に移動して探索することに長けています。以前の研究ではこれらの振る舞いをハイブリッド化した手法が提案されましたが、その組み合わせは主にハードコーディングされており、いつ探索に傾けいつ集中するかは固定の式やスケジュールに任されていました。この硬直性のため、アルゴリズムは非常に複雑または高次元の問題で早合点したり、逆に長時間さまよってしまったりすることがあります。本研究はウォラス—ガゼルのハイブリッドを、ただ移動するだけでなく探索からのフィードバックに基づいて「どのように動くか」を学ぶシステムとして再構想します。
群れに学習を導入する
最初に提案される手法AIRE_WGOは、Q学習と呼ばれる学習メカニズムを導入します。固定された台本に従う代わりに、アルゴリズムは候補解の集団からの単純な信号を観測します:どれだけ分散しているか(多様性)や最良解の改善速度など。これらの観測が探索の現在の「状態」を定義します。各状態に対してQ学習モジュールは、ガゼル風の探索を優先すべきかウォラス風の活用を優先すべきかを徐々に学びます。より良い解につながる決定は報酬として強化され、類似の状況で繰り返されやすくなります。AIRE_WGOはさらに内部のステップサイズを調整し、進展が停滞した際には制御されたランダム変異を導入して行き詰まりから脱出するのを助けます。
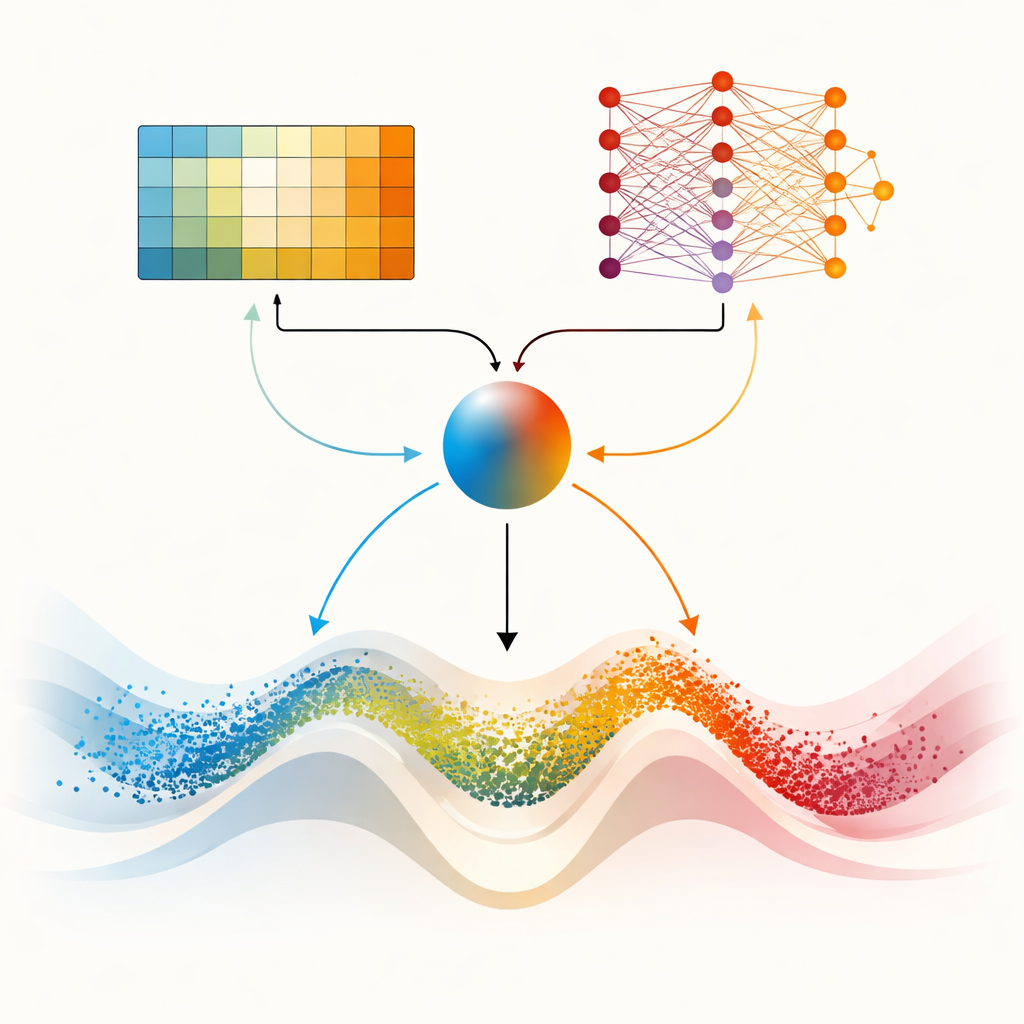
より厳しい地形のための二つのブレイン
論文の中心はDMARS_WGOで、ここでは最適化器に二つの補完的な学習「ブレイン」を与えます。一つはAIRE_WGOと同じ表形式のQ学習で、状況を粗いカテゴリ数で要約できる場合に単純かつ高速に動作します。他方はディープQネットワーク(DQN)と呼ばれる小さなニューラルネットワークで、多様性、改善率、停滞の指標が良い判断にどう結びつくかといった微妙なパターンを捉えられます。各反復で両方の学習者が行動提案を出し、ガゼル型の広域探索、ウォラス型の局所活用、あるいはその混合を勧めます。混合係数は現在の多様性、最近の進捗、行き詰まりの兆候から算出され、両者の提案を滑らかに重み付けして単一の行動にまとめます。情報は双方向に流れます:単純な学習者の経験はネットワークの訓練データを豊かにし、ネットワークから蒸留された知識は定期的に単純学習者の意思決定表を洗練します。この協調的な仕組みは行動を途切れなく適応させ、急激に切り替えるのを防ぎます。
手法の試験
この追加された知性が本当に有効かを確かめるため、著者らはDMARS_WGOを二つの広く用いられるテストスイート(CEC 2017およびCEC 2022)と、ばね、圧力容器、歯車列、支持構造など六つの実際の工学設計課題でベンチマークしました。これらの問題は誤誘導する局所最適や厳しい設計制約が多く、わざと難しく設定されています。多数のテスト関数において、DMARS_WGOは平均性能で最良を達成することが最も多く、試行間の結果も非常に安定していました。統計検定は、九つの他の先進的最適化手法に対する優位性が偶然によるものとは考えにくいことを示しています。重要なのは、この改善が圧倒的な計算コストを伴っていない点です:ニューラルネットの訓練はある程度のオーバーヘッドを追加しますが、全体の計算負荷は従来の群最適化と同様に候補設計の評価が支配的です。
実務上の意味
非専門家にとっての重要な結論は、DMARS_WGOは現場で学習しながら、偵察(新領域の探索)と吟味(有望箇所の詳細検討)に時間をどう割くかを最適に判断できる探索チームのように振る舞う、ということです。進捗の兆候と停滞の兆候を注意深く監視し、二種類の学習モジュールの指示を組み合わせることで、このアルゴリズムは難しく高次元の空間でもより確実に高品質な設計へと収束できます。これにより、機械部品から機械学習モデルまで、複雑なシステムを自動的にチューニングする将来の工学ツールの魅力的な構成要素となります。人間の専門家が探索の各段階を細かく指示する必要が少なくなります。
引用: Yousif, N.R., El-Gendy, E.M. & Haikal, A.Y. DMARS_WGO: a deep reinforcement-driven hybrid metaheuristic for intelligent adaptive optimization. Sci Rep 16, 13156 (2026). https://doi.org/10.1038/s41598-026-46134-4
キーワード: メタヒューリスティック最適化, 強化学習, 群知能, 工学設計, ディープQネットワーク