Clear Sky Science · es
DMARS_WGO: una metaheurística híbrida impulsada por refuerzo profundo para optimización adaptativa e inteligente
Búsqueda más inteligente para problemas complejos
Desde diseñar piezas de aeronaves más ligeras hasta ajustar modelos de aprendizaje automático, muchos desafíos modernos se reducen a la misma pregunta: ¿cómo buscar en enormes espacios de posibilidades para encontrar una solución realmente buena? Este artículo presenta un nuevo tipo de motor de búsqueda "inteligente", llamado DMARS_WGO, que aprende de la experiencia mientras explora, ayudando a ingenieros y científicos a alcanzar mejores diseños más rápido y con mayor fiabilidad.
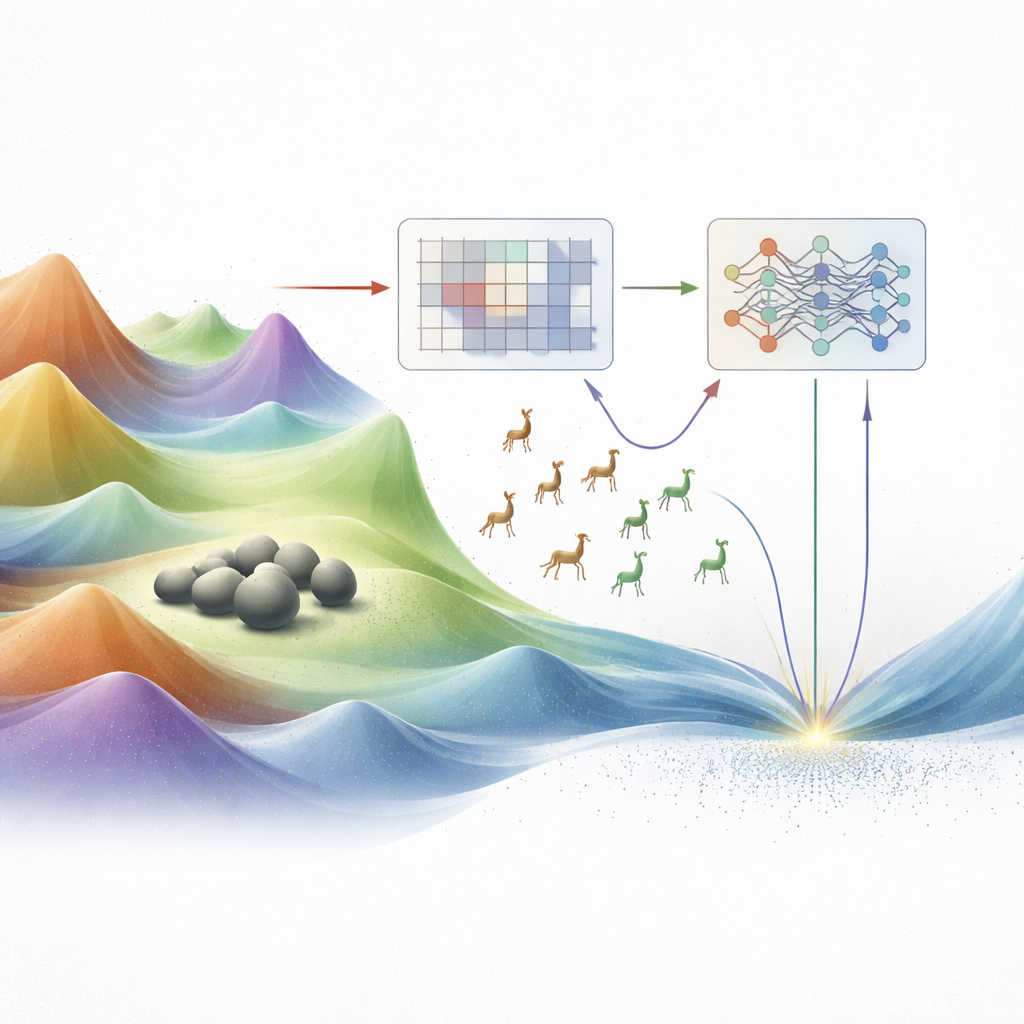
Por qué los métodos habituales se quedan cortos
Las técnicas tradicionales de optimización, como el descenso por gradiente y la programación lineal, funcionan bien solo cuando el terreno de posibilidades es suave y está bien comportado. Los problemas reales de ingeniería rara vez son así. A menudo están salpicados de picos y valles, acantilados repentinos y giros en alta dimensión. En paisajes tan accidentados, los métodos clásicos pueden atascarse fácilmente en una colina cercana en lugar de encontrar el valle más profundo, la verdadera mejor solución. En las últimas décadas, los investigadores han recurrido a las llamadas metaheurísticas, algoritmos inspirados en la naturaleza, la física y el comportamiento humano. Estos métodos mueven enjambres de soluciones candidatas por el paisaje, imitando bandadas de aves, depredadores cazando o el enfriamiento de materiales. Aunque poderosos, muchos de estos enfoques siguen teniendo dificultades para equilibrar dos necesidades opuestas: la exploración amplia de nuevo territorio y la explotación cuidadosa de regiones prometedoras.
Dos metáforas animales, una idea central
Los autores se basan en dos optimizadores recientes inspirados en animales: el Walrus Optimizer, que es bueno afinando alrededor de puntos atractivos (explotación), y el Gazelle Optimization Algorithm, que sobresale en el recorrido amplio y ágil (exploración). Trabajos anteriores ya habían combinado estos comportamientos en métodos híbridos, pero la mezcla era en gran medida codificada rígidamente: fórmulas o calendarios fijos decidían cuándo deambular y cuándo concentrarse. Esa rigidez hace que el algoritmo todavía pueda sacar conclusiones demasiado pronto o vagar sin rumbo durante demasiado tiempo, especialmente en problemas muy complejos o de alta dimensión. El nuevo trabajo reimagina este híbrido morsa–gacela como un sistema que no solo se mueve, sino que además aprende cómo moverse en función de la retroalimentación de la propia búsqueda.
Añadiendo aprendizaje al enjambre
El primer método propuesto, AIRE_WGO, introduce un mecanismo de aprendizaje llamado Q‑learning. En lugar de seguir un guion fijo, el algoritmo observa señales simples de su población de soluciones candidatas: cuánto están dispersas (diversidad) y qué tan rápido mejora la mejor solución. Estas observaciones definen el "estado" actual de la búsqueda. Para cada estado, el módulo de Q‑learning descubre gradualmente si es mejor favorecer la exploración al estilo gacela o la explotación al estilo morsa. Las decisiones exitosas—las que conducen a mejores soluciones—se recompensan, de modo que el sistema tiende a repetirlas en situaciones similares. AIRE_WGO además ajusta sus tamaños de paso internos e introduce mutaciones aleatorias controladas cuando el progreso se estanca, ayudándole a escapar de callejones sin salida.
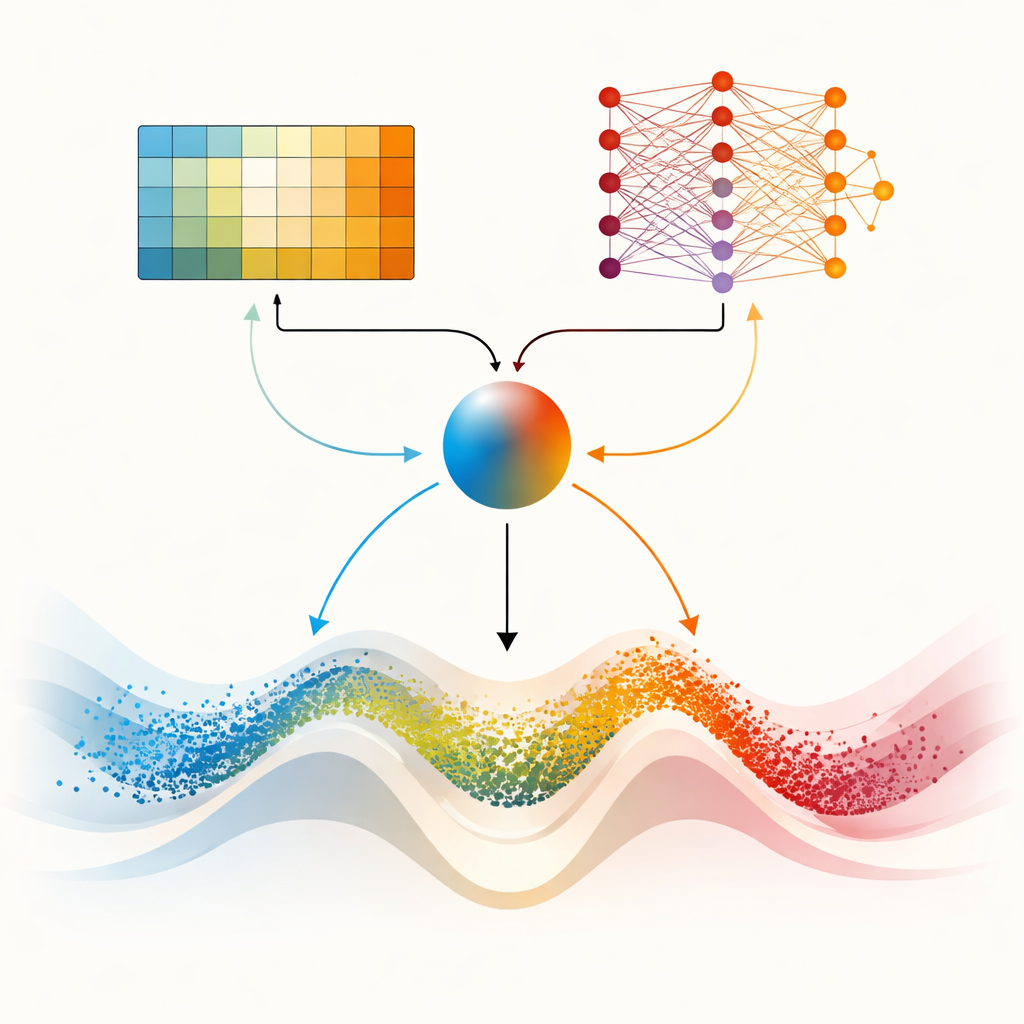
Dos cerebros para paisajes más difíciles
La pieza central del artículo es DMARS_WGO, que va un paso más allá al dotar al optimizador de dos "cerebros" de aprendizaje complementarios. Uno es el mismo Q‑learning tabular usado en AIRE_WGO, simple y rápido cuando la situación puede resumirse en unas pocas categorías toscas. El otro es una Deep Q‑Network, una pequeña red neuronal capaz de capturar patrones más sutiles en cómo la diversidad, la tasa de mejora y la estasis se relacionan con buenas decisiones. En cada iteración, ambos aprendices proponen qué hacer—inclinarse por el vagar tipo gacela, el enfoque tipo morsa o una mezcla de ambos. Un coeficiente de mezcla, calculado a partir de la diversidad actual, el progreso reciente y señales de estancamiento, pondera suavemente sus sugerencias en una sola acción. La información también fluye en ambas direcciones: las experiencias del aprendiz más simple enriquecen los datos de entrenamiento de la red neuronal, mientras que el conocimiento destilado de la red refina periódicamente la tabla de decisiones del aprendiz sencillo. Esta configuración cooperativa ayuda al optimizador a adaptar su comportamiento de forma continua en lugar de cambiar bruscamente.
Poniendo el método a prueba
Para comprobar si esta inteligencia adicional realmente compensa, los autores evalúan DMARS_WGO en dos conjuntos de pruebas ampliamente usados (CEC 2017 y CEC 2022) y en seis tareas reales de diseño en ingeniería, incluidas muelles, recipientes a presión, trenes de engranajes y estructuras de soporte. Estos problemas son deliberadamente desafiantes, con muchos óptimos locales engañosos y restricciones estrictas de diseño. En docenas de funciones de prueba, DMARS_WGO con frecuencia logra el mejor rendimiento medio y muestra resultados muy estables de una ejecución a otra. Pruebas estadísticas confirman que sus ventajas frente a otros nueve optimizadores avanzados probablemente no se deben al azar. Es importante destacar que esta mejora en el rendimiento no viene con un coste computacional prohibitivo: aunque entrenar una red neuronal añade cierta sobrecarga, el esfuerzo global sigue estando dominado por la evaluación de diseños candidatos, como ocurre en los métodos de enjambre estándar.
Qué significa esto en la práctica
Para un público no especialista, el resultado clave es que DMARS_WGO se comporta como un equipo de búsqueda que aprende, sobre la marcha, cómo repartir mejor su tiempo entre explorar nuevo territorio y examinar en detalle hallazgos prometedores. Al monitorizar cuidadosamente señales de progreso y de estancamiento, y al permitir que dos módulos de aprendizaje distintos guíen sus movimientos, el algoritmo puede acercarse con mayor fiabilidad a diseños de alta calidad en espacios difíciles y de alta dimensión. Esto lo convierte en un componente atractivo para futuras herramientas de ingeniería que deban ajustar automáticamente sistemas complejos—desde componentes mecánicos hasta modelos de aprendizaje automático—sin exigir a un experto humano que microgestione cada paso de la búsqueda.
Cita: Yousif, N.R., El-Gendy, E.M. & Haikal, A.Y. DMARS_WGO: a deep reinforcement-driven hybrid metaheuristic for intelligent adaptive optimization. Sci Rep 16, 13156 (2026). https://doi.org/10.1038/s41598-026-46134-4
Palabras clave: optimización metaheurística, aprendizaje por refuerzo, inteligencia de enjambre, diseño en ingeniería, redes Q profundas