Clear Sky Science · it
DMARS_WGO: un metaeuristico ibrido guidato da deep reinforcement per l’ottimizzazione adattiva intelligente
Ricerca più intelligente per problemi complessi
Dalla progettazione di componenti aeronautici più leggeri alla messa a punto di modelli di machine learning, molte sfide moderne si riducono alla stessa domanda: come esploriamo spazi enormi di possibilità per trovare una soluzione davvero valida? Questo articolo introduce un nuovo tipo di motore di ricerca “intelligente”, chiamato DMARS_WGO, che impara dall’esperienza durante l’esplorazione, aiutando ingegneri e scienziati a raggiungere progetti migliori più rapidamente e con maggiore affidabilità.
Perché i metodi ordinari non bastano
Le tecniche tradizionali di ottimizzazione, come la discesa del gradiente e la programmazione lineare, funzionano bene solo quando il territorio delle possibilità è liscio e ben comportato. I problemi ingegneristici reali raramente sono così. Spesso sono pieni di picchi e valli, scogliere improvvise e intrecci ad alta dimensionalità. In paesaggi così accidentati, i metodi classici possono facilmente restare bloccati su una collina vicina invece di trovare la valle più profonda — la vera soluzione ottimale. Negli ultimi decenni, i ricercatori si sono rivolti alle cosiddette metaeuristiche, algoritmi ispirati alla natura, alla fisica e al comportamento umano. Questi metodi muovono sciami di soluzioni candidate attraverso il paesaggio, imitando stormi di uccelli, predatori in caccia o materiali che si raffreddano. Pur essendo potenti, molte di queste tecniche faticano ancora a bilanciare due esigenze concorrenti: l’esplorazione ampia di nuovo territorio e lo sfruttamento accurato delle regioni promettenti.
Due metafore animali, un’idea centrale
Gli autori partono da due recenti ottimizzatori ispirati ad animali: il Walrus Optimizer, efficace nel mettere a punto soluzioni attorno a punti attraenti (sfruttamento), e il Gazelle Optimization Algorithm, che eccelle nell’esplorazione ampia e agile (esplorazione). Lavori precedenti avevano già combinato questi comportamenti in metodi ibridi, ma la miscela era in gran parte codificata rigidamente: formule o schemi fissi decidevano quando vagare e quando concentrarsi. Questa rigidità può portare l’algoritmo a trarre conclusioni premature o a vagare senza meta troppo a lungo, specialmente su problemi molto complessi o ad alta dimensionalità. Il nuovo lavoro reimmagina questo ibrido walrus–gazelle come un sistema che non si limita a muoversi, ma impara anche come muoversi in base al feedback derivante dalla ricerca stessa.
Aggiungere apprendimento allo sciame
Il primo metodo proposto, AIRE_WGO, introduce un meccanismo di apprendimento chiamato Q‑learning. Invece di seguire uno script fisso, l’algoritmo osserva segnali semplici dalla sua popolazione di soluzioni candidate: quanto sono distribuite (diversità) e quanto rapidamente migliora la migliore soluzione. Queste osservazioni definiscono lo “stato” corrente della ricerca. Per ogni stato, il modulo di Q‑learning scopre gradualmente se è meglio favorire l’esplorazione in stile gazella o lo sfruttamento in stile walrus. Le decisioni di successo — quelle che portano a soluzioni migliori — vengono premiate, così il sistema diventa più propenso a ripeterle in situazioni simili. AIRE_WGO regola inoltre le sue dimensioni di passo interne e introduce mutazioni casuali controllate quando i progressi rallentano, aiutandolo a sfuggire ai vicoli ciechi.
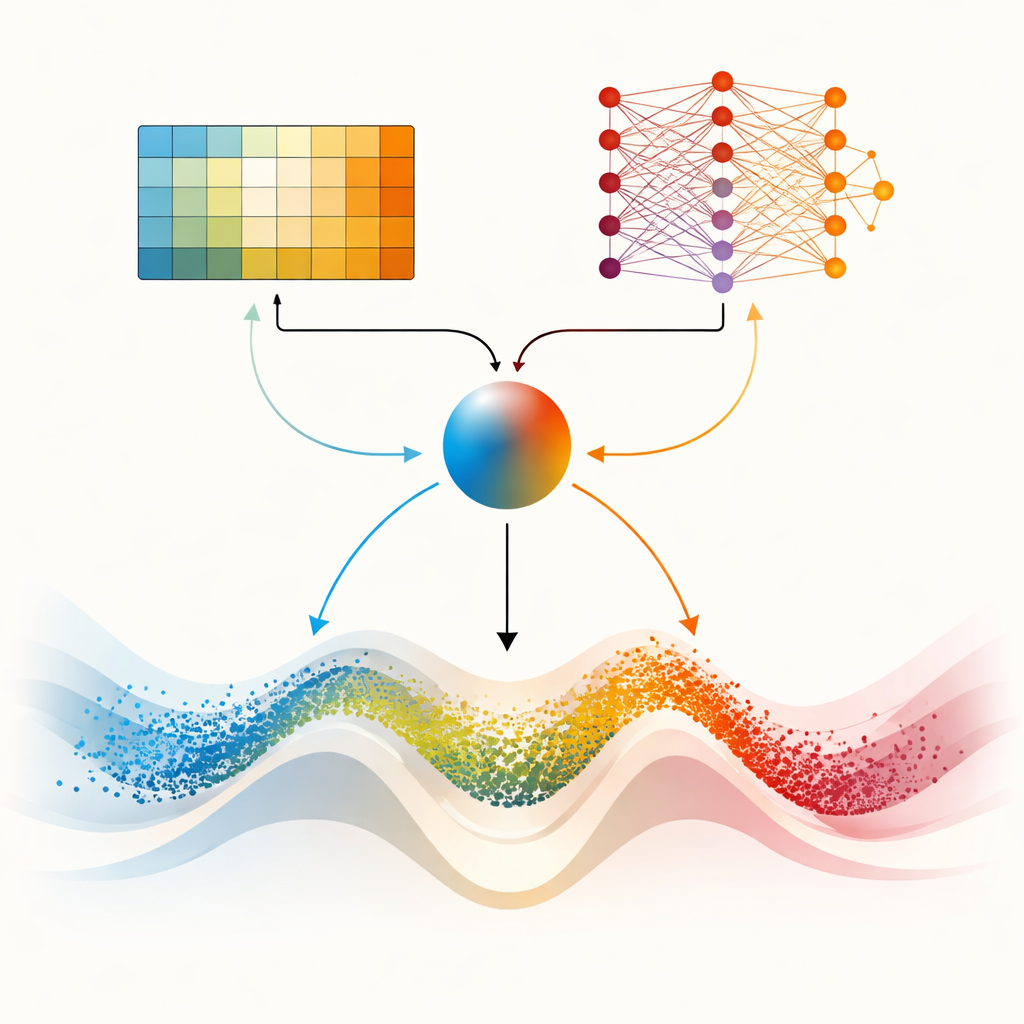
Doppi cervelli per paesaggi più difficili
Il fulcro dell’articolo è DMARS_WGO, che va oltre dotando l’ottimizzatore di due “cervelli” di apprendimento complementari. Uno è lo stesso Q‑learning tabellare usato in AIRE_WGO, semplice e veloce quando la situazione può essere riassunta in poche categorie grossolane. L’altro è una Deep Q‑Network, una piccola rete neurale in grado di catturare pattern più sottili su come diversità, tasso di miglioramento e stasi si relazionano a buone decisioni. A ogni iterazione, entrambi gli apprendenti propongono cosa fare — puntare sull’esplorazione in stile gazella, sullo sfruttamento in stile walrus, o su una miscela dei due. Un coefficiente di fusione, calcolato a partire dalla diversità corrente, dai progressi recenti e dai segnali di stallo, pesa in maniera continua i loro suggerimenti in un’unica azione. L’informazione scorre anche in entrambe le direzioni: le esperienze del learner più semplice arricchiscono i dati di addestramento della rete neurale, mentre conoscenze distillate dalla rete rifiniscono periodicamente la tabella decisionale del learner semplice. Questa configurazione cooperativa aiuta l’ottimizzatore ad adattare il proprio comportamento in modo continuo anziché passare da uno stato all’altro bruscamente.
Mettere il metodo alla prova
Per verificare se questa intelligenza aggiuntiva ripaga davvero, gli autori valutano DMARS_WGO su due suite di test largamente usate (CEC 2017 e CEC 2022) e su sei compiti reali di progettazione ingegneristica, incluse molle, recipienti a pressione, treni di ingranaggi e strutture di supporto. Questi problemi sono deliberatamente impegnativi, con molti ottimi locali fuorvianti e vincoli di progettazione stringenti. Su dozzine di funzioni di test, DMARS_WGO ottiene più spesso la migliore prestazione media e mostra risultati molto stabili da esecuzione a esecuzione. Test statistici confermano che i suoi vantaggi rispetto ad altri nove ottimizzatori avanzati sono improbabili dovuti al caso. È importante sottolineare che questo miglioramento delle prestazioni non comporta un costo computazionale proibitivo: sebbene l’addestramento di una rete neurale aggiunga un sovraccarico, lo sforzo complessivo è ancora dominato dalla valutazione delle soluzioni candidate, proprio come nei metodi swarm standard.
Cosa significa nella pratica
Per un non specialista, il risultato chiave è che DMARS_WGO si comporta come un team di ricerca che impara, sul campo, come dividere al meglio il tempo tra esplorare nuovo territorio e analizzare dettagliatamente le scoperte promettenti. Monitorando con attenzione segnali di progresso e segnali di stasi, e lasciando che due moduli di apprendimento differenti guidino le sue mosse, l’algoritmo può convergere in modo più affidabile su progetti di alta qualità in spazi difficili e ad alta dimensionalità. Questo lo rende un elemento interessante per futuri strumenti ingegneristici che devono sintonizzare automaticamente sistemi complessi — dai componenti meccanici ai modelli di machine learning — senza richiedere a un esperto umano di micromaneggiare ogni passo della ricerca.
Citazione: Yousif, N.R., El-Gendy, E.M. & Haikal, A.Y. DMARS_WGO: a deep reinforcement-driven hybrid metaheuristic for intelligent adaptive optimization. Sci Rep 16, 13156 (2026). https://doi.org/10.1038/s41598-026-46134-4
Parole chiave: ottimizzazione metaeuristica, apprendimento per rinforzo, intelligenza degli sciami, progettazione ingegneristica, deep Q networks