Clear Sky Science · pl
DMARS_WGO: hybrydowa metaheurystyka napędzana głębokim wzmacnianiem do inteligentnej adaptacyjnej optymalizacji
Bystrzejsze poszukiwania dla złożonych problemów
Od projektowania lżejszych elementów samolotów po strojenie modeli uczenia maszynowego — wiele współczesnych wyzwań sprowadza się do jednego pytania: jak przeszukiwać ogromne przestrzenie możliwości, by znaleźć naprawdę dobre rozwiązanie? W artykule przedstawiono nowy rodzaj „inteligentnej” wyszukiwarki, nazwaną DMARS_WGO, która uczy się na podstawie doświadczeń podczas eksploracji, pomagając inżynierom i naukowcom szybciej osiągać lepsze projekty i robić to bardziej niezawodnie.
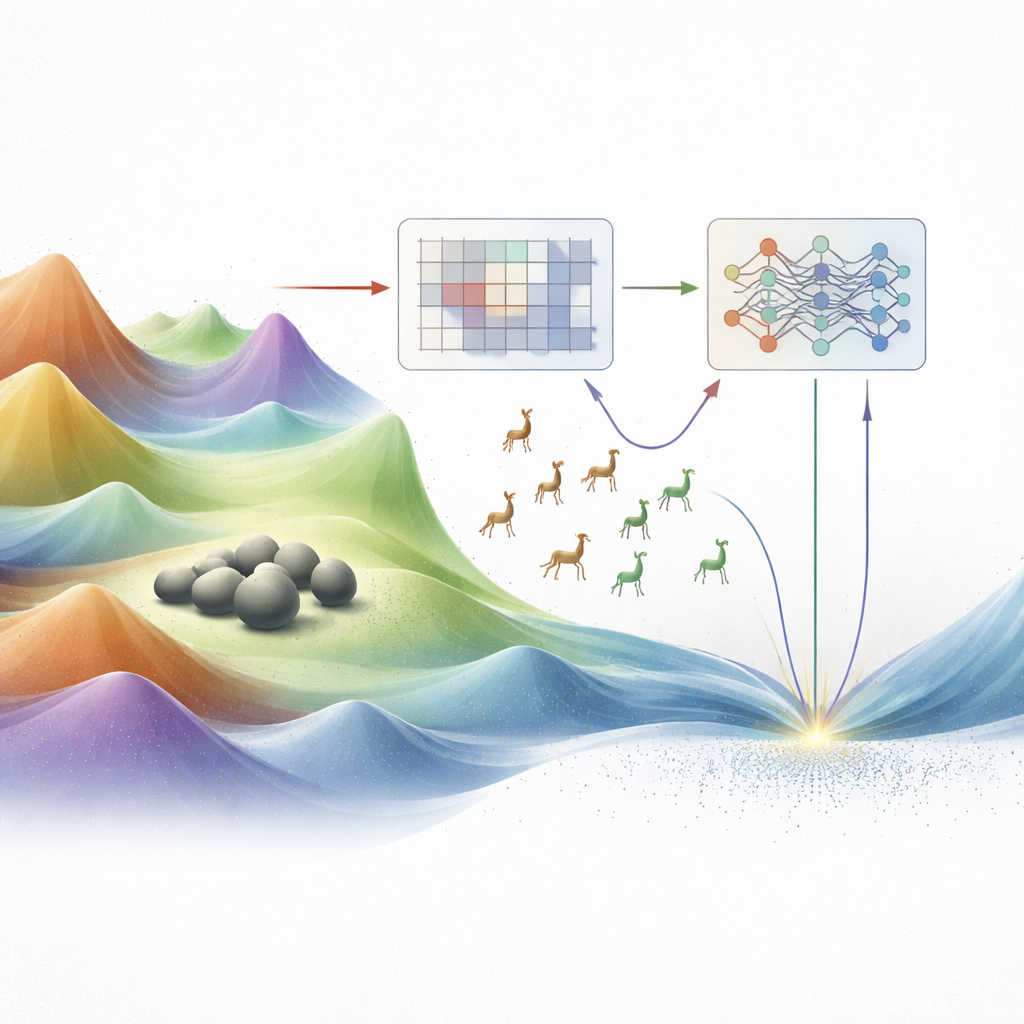
Dlaczego zwykłe metody zawodzą
Tradycyjne techniki optymalizacji, takie jak spadek gradientu czy programowanie liniowe, sprawdzają się tylko wtedy, gdy krajobraz możliwości jest gładki i dobrze ustrukturyzowany. Rzeczywiste problemy inżynierskie rzadko tak wyglądają. Często są naznaczone wieloma szczytami i dolinami, nagłymi urwiskami oraz zawiłymi, wysokowymiarowymi cechami. W takich „surowych” przestrzeniach klasyczne metody łatwo utkną na pobliskim pagórku zamiast znaleźć najgłębszą dolinę — prawdziwie optymalne rozwiązanie. W ciągu ostatnich dekad badacze zwrócili się ku tzw. metaheurystykom, algorytmom inspirowanym naturą, fizyką i zachowaniami społecznymi. Metody te poruszają roje kandydatów rozwiązań po krajobrazie, naśladując stada ptaków, polowanie drapieżników czy stygnące materiały. Mimo swojej siły, wiele z tych technik wciąż ma trudności z wyważeniem dwóch sprzecznych potrzeb: szerokiej eksploracji nowych obszarów i starannego eksploatowania obiecujących regionów.
Dwa zwierzęce metafory, jedna główna idea
Autorzy opierają się na dwóch niedawnych optymalizatorach inspirowanych zwierzętami: Walrus Optimizer, który dobrze radzi sobie z precyzyjnym dopracowywaniem wokół atrakcyjnych punktów (eksploatacja), oraz Gazelle Optimization Algorithm, który wyróżnia się szerokim, zwinym przemieszczaniem się (eksploracja). Wcześniejsze prace łączyły już te zachowania w hybrydowe metody, ale mieszanka była w dużej mierze zakodowana na stałe: stałe formuły lub harmonogramy decydowały, kiedy wędrować, a kiedy się skupić. Ta sztywność oznacza, że algorytm nadal może zbyt szybko wyciągać wnioski lub bezcelowo błądzić zbyt długo, zwłaszcza przy bardzo złożonych lub wysokowymiarowych problemach. Nowa praca przekształca tę hybrydę morsy–gazeli w system, który nie tylko się porusza, ale uczy się, jak się poruszać w oparciu o informacje zwrotne z samego procesu poszukiwania.
Dodanie uczenia do roju
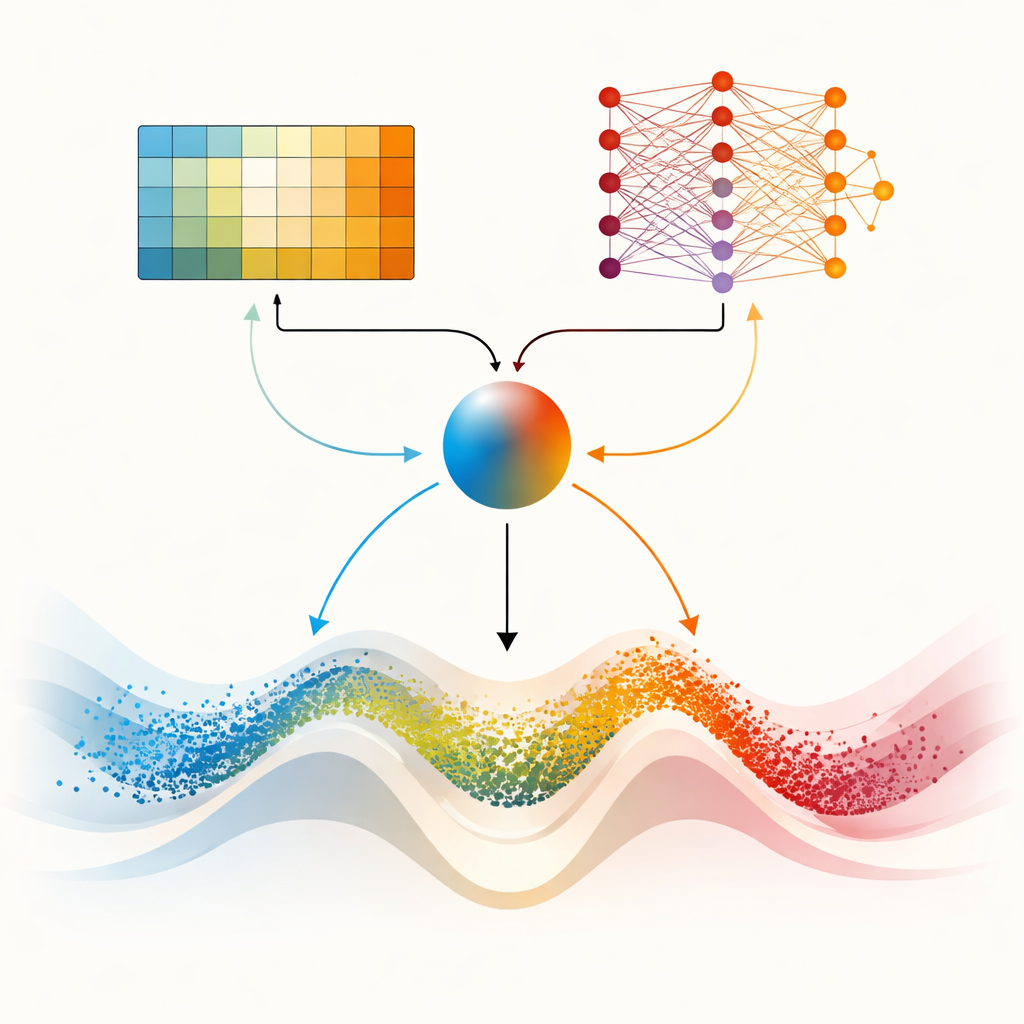
Pierwsza proponowana metoda, AIRE_WGO, wprowadza mechanizm uczenia zwany Q‑learningiem. Zamiast podążać za stałym scenariuszem, algorytm obserwuje proste sygnały z populacji kandydatów: jak bardzo są rozproszeni (różnorodność) i jak szybko poprawia się najlepsze rozwiązanie. Te obserwacje definiują bieżący „stan” poszukiwania. Dla każdego stanu moduł Q‑learning stopniowo odkrywa, czy lepiej faworyzować eksplorację w stylu gazeli, czy eksploatację w stylu morsy. Udane decyzje — te prowadzące do lepszych rozwiązań — są nagradzane, więc system staje się bardziej skłonny je powtarzać w podobnych sytuacjach. AIRE_WGO dodatkowo dopasowuje swoje wewnętrzne kroki i wprowadza kontrolowane losowe mutacje, gdy postęp ustaje, pomagając wydostać się z martwych punktów.
Podwójne mózgi dla trudniejszych krajobrazów
Głównym punktem artykułu jest DMARS_WGO, który idzie o krok dalej, nadając optymalizatorowi dwa komplementarne „mózgi” uczące się. Jeden to ten sam tablicowy Q‑learning użyty w AIRE_WGO, prosty i szybki, gdy sytuację można podsumować kilkoma grubymi kategoriami. Drugi to Deep Q‑Network, mała sieć neuronowa, która potrafi wychwycić subtelniejsze wzorce w zależnościach między różnorodnością, tempem poprawy a stagnacją a dobrymi decyzjami. Przy każdej iteracji obaj uczący się proponują, co zrobić — skłonić się ku wędrowaniu w stylu gazeli, skupieniu jak morsy, czy mieszaninie obu. Współczynnik mieszania, obliczany na podstawie bieżącej różnorodności, ostatnich postępów i sygnałów utknięcia, płynnie łączy ich sugestie w jedną akcję. Informacje płyną też w obie strony: doświadczenia z prostszego ucznia wzbogacają dane treningowe sieci neuronowej, podczas gdy zdestylowana wiedza z sieci okresowo ulepsza tablicę decyzyjną prostszego ucznia. Taka współpraca pomaga optymalizatorowi dostosowywać zachowanie ciągle, zamiast przełączać się nagle.
Testy metody
Aby sprawdzić, czy ta dodatkowa inteligencja rzeczywiście się opłaca, autorzy ocenili DMARS_WGO na dwóch powszechnie używanych zestawach testowych (CEC 2017 i CEC 2022) oraz na sześciu rzeczywistych zadaniach projektowania inżynierskiego, w tym sprężynach, zbiornikach ciśnieniowych, przekładniach i strukturach nośnych. Problemy te są celowo trudne, z wieloma mylącymi lokalnymi optimum i surowymi ograniczeniami projektowymi. Na dziesiątkach funkcji testowych DMARS_WGO najczęściej osiągał najlepszą średnią wydajność i wykazywał bardzo stabilne wyniki między uruchomieniami. Testy statystyczne potwierdzają, że jego przewaga nad dziewięcioma innymi zaawansowanymi optymalizatorami jest mało prawdopodobna do przypisania przypadkowi. Co ważne, poprawa wydajności nie wiąże się z zabójczym kosztem obliczeniowym: choć trening sieci neuronowej dodaje pewien narzut, ogólny wysiłek wciąż dominuje ocena kandydatów rozwiązań, tak jak w standardowych metodach rojowych.
Co to oznacza w praktyce
Dla osoby niespecjalizującej się kluczowy wniosek jest taki, że DMARS_WGO zachowuje się jak zespół poszukiwawczy, który w locie uczy się, jak najlepiej dzielić czas między zwiad nowych terenów a szczegółowe badanie obiecujących znalezisk. Poprzez uważne monitorowanie sygnałów postępu i stagnacji oraz pozwalając dwóm różnym modułom uczącym kierować ruchami, algorytm może bardziej niezawodnie zbliżać się do rozwiązań wysokiej jakości w trudnych, wysokowymiarowych przestrzeniach. Czyni to z niego atrakcyjny element budulcowy dla przyszłych narzędzi inżynierskich, które muszą automatycznie stroić złożone systemy — od komponentów mechanicznych po modele uczenia maszynowego — bez konieczności ręcznego sterowania każdym krokiem poszukiwania przez eksperta.
Cytowanie: Yousif, N.R., El-Gendy, E.M. & Haikal, A.Y. DMARS_WGO: a deep reinforcement-driven hybrid metaheuristic for intelligent adaptive optimization. Sci Rep 16, 13156 (2026). https://doi.org/10.1038/s41598-026-46134-4
Słowa kluczowe: optymalizacja metaheurystyczna, uczenie przez wzmacnianie, inteligencja rojowa, projektowanie inżynierskie, głębokie sieci Q