Clear Sky Science · fr
DMARS_WGO : une méta‑heuristique hybride pilotée par apprentissage par renforcement profond pour une optimisation adaptative intelligente
Une recherche plus intelligente pour des problèmes complexes
De la conception de pièces d’avion plus légères à l’ajustement de modèles d’apprentissage automatique, de nombreux défis actuels reviennent à la même question : comment explorer d’immenses espaces de possibilités pour trouver une solution réellement performante ? Cet article présente un nouveau type de moteur de recherche « intelligent », appelé DMARS_WGO, qui apprend de l’expérience pendant qu’il explore, aidant ingénieurs et scientifiques à obtenir de meilleurs designs plus rapidement et de manière plus fiable.
Pourquoi les méthodes ordinaires montrent leurs limites
Les techniques d’optimisation traditionnelles, comme la descente de gradient ou la programmation linéaire, fonctionnent bien seulement quand le paysage des possibilités est lisse et bien comporté. Les problèmes d’ingénierie réels ressemblent rarement à cela. Ils sont souvent semés de nombreux sommets et vallées, de falaises abruptes et de torsions en haute dimension. Dans de tels paysages accidentés, les méthodes classiques peuvent facilement se coincer sur une colline voisine au lieu de trouver la vallée la plus profonde — la véritable meilleure solution. Au cours des dernières décennies, les chercheurs se sont tournés vers les méta‑heuristiques, des algorithmes inspirés par la nature, la physique et le comportement humain. Ces méthodes déplacent des essaims de solutions candidates à travers le paysage, imitant des vols d’oiseaux, des prédateurs en chasse ou le refroidissement de matériaux. Bien que puissantes, beaucoup de ces techniques peinent encore à équilibrer deux besoins contradictoires : une exploration large de territoires nouveaux et une exploitation prudente des régions prometteuses.
Deux métaphores animales, une idée centrale
Les auteurs s’appuient sur deux optimiseurs récents inspirés du monde animal : le Walrus Optimizer, performant pour l’affinage autour de zones attractives (exploitation), et l’algorithme Gazelle Optimization, qui excelle dans les déplacements larges et agiles (exploration). Des travaux antérieurs avaient déjà combiné ces comportements en méthodes hybrides, mais le mélange était largement codé en dur : des formules ou des calendriers fixes décidaient quand parcourir ou quand se concentrer. Cette rigidité fait que l’algorithme peut encore tirer des conclusions trop hâtives ou errer indéfiniment, surtout sur des problèmes très complexes ou à haute dimension. Le nouvel effort réinvente cet hybride morse–gazelle comme un système qui ne se contente pas de bouger, mais apprend aussi à se déplacer en fonction des retours fournis par la recherche elle‑même.
Ajouter de l’apprentissage à l’essaim
La première méthode proposée, AIRE_WGO, introduit un mécanisme d’apprentissage appelé Q‑learning. Plutôt que de suivre un script fixe, l’algorithme observe des signaux simples issus de sa population de solutions candidates : leur dispersion (diversité) et la rapidité d’amélioration de la meilleure solution. Ces observations définissent l’« état » courant de la recherche. Pour chaque état, le module de Q‑learning découvre progressivement s’il est préférable de favoriser l’exploration de type gazelle ou l’exploitation de type morse. Les décisions réussies — celles qui conduisent à de meilleures solutions — sont récompensées, de sorte que le système tend à les reproduire dans des situations similaires. AIRE_WGO ajuste en outre ses tailles de pas internes et introduit des mutations aléatoires contrôlées lorsque le progrès stagne, ce qui l’aide à s’extraire des impasses.
Deux cerveaux pour des paysages plus rudes
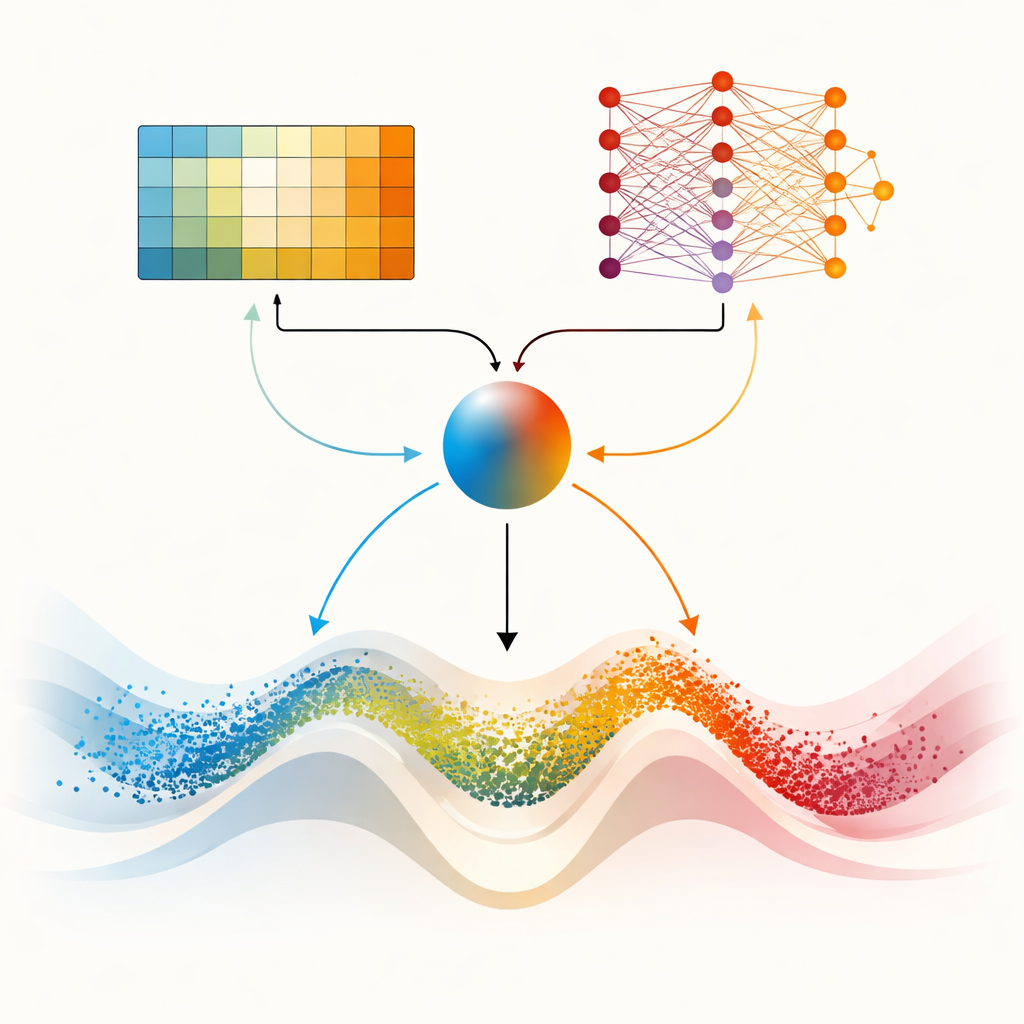
Le point central de l’article est DMARS_WGO, qui va plus loin en dotant l’optimiseur de deux « cerveaux » d’apprentissage complémentaires. L’un est le Q‑learning tabulaire déjà utilisé dans AIRE_WGO, simple et rapide lorsque la situation peut être résumée en quelques catégories grossières. L’autre est un Deep Q‑Network, un petit réseau neuronal capable de capturer des motifs plus subtils quant à la relation entre diversité, rythme d’amélioration et stagnation pour prendre de bonnes décisions. À chaque itération, les deux apprentissages proposent une action : privilégier la mobilité de type gazelle, la focalisation de type morse, ou un mélange des deux. Un coefficient de mélange, calculé à partir de la diversité courante, des progrès récents et des signes de blocage, pondère harmonieusement leurs suggestions en une seule action. L’information circule aussi dans les deux sens : les expériences du simple apprenant enrichissent les données d’entraînement du réseau neuronal, tandis que le savoir distillé du réseau affine périodiquement la table de décision du simple apprenant. Cette coopération aide l’optimiseur à adapter son comportement en continu plutôt qu’à basculer de façon abrupte.
Mettre la méthode à l’épreuve
Pour vérifier si cette intelligence additionnelle apporte un réel bénéfice, les auteurs évaluent DMARS_WGO sur deux suites de test largement utilisées (CEC 2017 et CEC 2022) et sur six tâches concrètes de conception en ingénierie, incluant ressorts, récipients sous pression, trains d’engrenages et structures de support. Ces problèmes sont délibérément difficiles, avec de nombreux optima locaux trompeurs et des contraintes de conception strictes. Sur des dizaines de fonctions test, DMARS_WGO obtient le plus souvent la meilleure performance moyenne et affiche des résultats très stables d’une exécution à l’autre. Des tests statistiques confirment que ses avantages par rapport à neuf autres optimiseurs avancés sont peu susceptibles d’être dus au hasard. Fait important, cette amélioration des performances n’entraîne pas un coût computationnel prohibitif : bien que l’entraînement d’un réseau neuronal ajoute une surcharge, l’effort global demeure dominé par l’évaluation des solutions candidates, comme dans les méthodes d’essaim classiques.
Ce que cela signifie en pratique
Pour un non‑spécialiste, le résultat clé est que DMARS_WGO se comporte comme une équipe de recherche qui apprend, en temps réel, comment répartir au mieux son temps entre la prospection de nouveaux territoires et l’examen détaillé des trouvailles prometteuses. En surveillant attentivement les signes de progrès et de stagnation, et en laissant deux modules d’apprentissage différents guider ses mouvements, l’algorithme peut converger plus fiablement vers des designs de haute qualité dans des espaces difficiles et de haute dimension. Cela en fait un bloc de construction attractif pour des outils d’ingénierie futurs qui doivent paramétrer automatiquement des systèmes complexes — des composants mécaniques aux modèles d’apprentissage automatique — sans exiger qu’un expert humain micro‑gère chaque étape de la recherche.
Citation: Yousif, N.R., El-Gendy, E.M. & Haikal, A.Y. DMARS_WGO: a deep reinforcement-driven hybrid metaheuristic for intelligent adaptive optimization. Sci Rep 16, 13156 (2026). https://doi.org/10.1038/s41598-026-46134-4
Mots-clés: optimisation métaheuristique, apprentissage par renforcement, intelligence par essaim, conception en ingénierie, réseaux Q profonds