Clear Sky Science · ru
DMARS_WGO: гибридная метаэвристика с глубоким подкреплением для интеллектуальной адаптивной оптимизации
Более умный поиск для сложных задач
От проектирования более лёгких авиационных деталей до настройки моделей машинного обучения — многие современные задачи сводятся к одному: как искать в огромном пространстве вариантов, чтобы найти действительно хорошее решение? В этой работе представлен новый тип «умного» поискового движка, названный DMARS_WGO, который обучается на опыте в процессе исследования, помогая инженерам и учёным быстрее и надёжнее достигать лучших решений.
Почему обычные методы не справляются
Традиционные методы оптимизации, такие как градиентный спуск и линейное программирование, хорошо работают только когда ландшафт вариантов гладкий и корректно себя ведёт. Реальные инженерные задачи редко такие. Они часто усеяны множеством пиков и впадин, резкими обрывами и высокоразмерными изгибами. В таких «рваных» пространствах классические методы легко застревают на ближайшем холме вместо того, чтобы найти самую глубокую впадину — истинно лучшее решение. В последние десятилетия исследователи обращаются к так называемым метаэвристикам — алгоритмам, вдохновлённым природой, физикой и поведением живых систем. Эти методы перемещают рои кандидатов по ландшафту, имитируя стаи птиц, охотников или охлаждение материалов. Хотя они мощны, многие из этих техник по‑прежнему испытывают трудности при балансировке двух конкурирующих потребностей: широкого исследования новой территории и тщательной эксплуатации перспективных областей.
Две звериные метафоры — одна основная идея
Авторы опираются на два недавних оптимизатора, вдохновлённых животными: Walrus Optimizer, хорошо подходящий для тонкой настройки вокруг привлекательных точек (эксплуатация), и Gazelle Optimization Algorithm, умеющий быстро и широко перемещаться (исследование). Ранее уже комбинировали эти поведения в гибридных методах, но сочетание было в основном жёстко запрограммировано: фиксированные формулы или расписания решали, когда бродить, а когда фокусироваться. Такая жёсткость означает, что алгоритм может преждевременно делать выводы или бесцельно блуждать слишком долго, особенно на очень сложных или высокоразмерных задачах. Новая работа переосмысливает этот гибрид моржа и газели как систему, которая не просто двигается, но и учится двигаться на основе обратной связи от самого поиска.
Добавление обучения в рой
Первый предложенный метод, AIRE_WGO, вводит механизм обучения, называемый Q‑обучением. Вместо того чтобы следовать фиксированному сценарию, алгоритм наблюдает простые сигналы от популяции кандидатов: насколько они разбросаны (разнообразие) и насколько быстро улучшается лучшее решение. Эти наблюдения определяют текущее «состояние» поиска. Для каждого состояния модуль Q‑обучения постепенно выясняет, что лучше — отдавать приоритет исследованию в стиле газели или эксплуатации в стиле моржа. Успешные решения — те, что приводят к улучшению — вознаграждаются, поэтому система с большей вероятностью повторит их в похожих ситуациях. AIRE_WGO дополнительно подстраивает внутренние размеры шагов и вводит контролируемые случайные мутации при застое, помогая выбираться из тупиков.
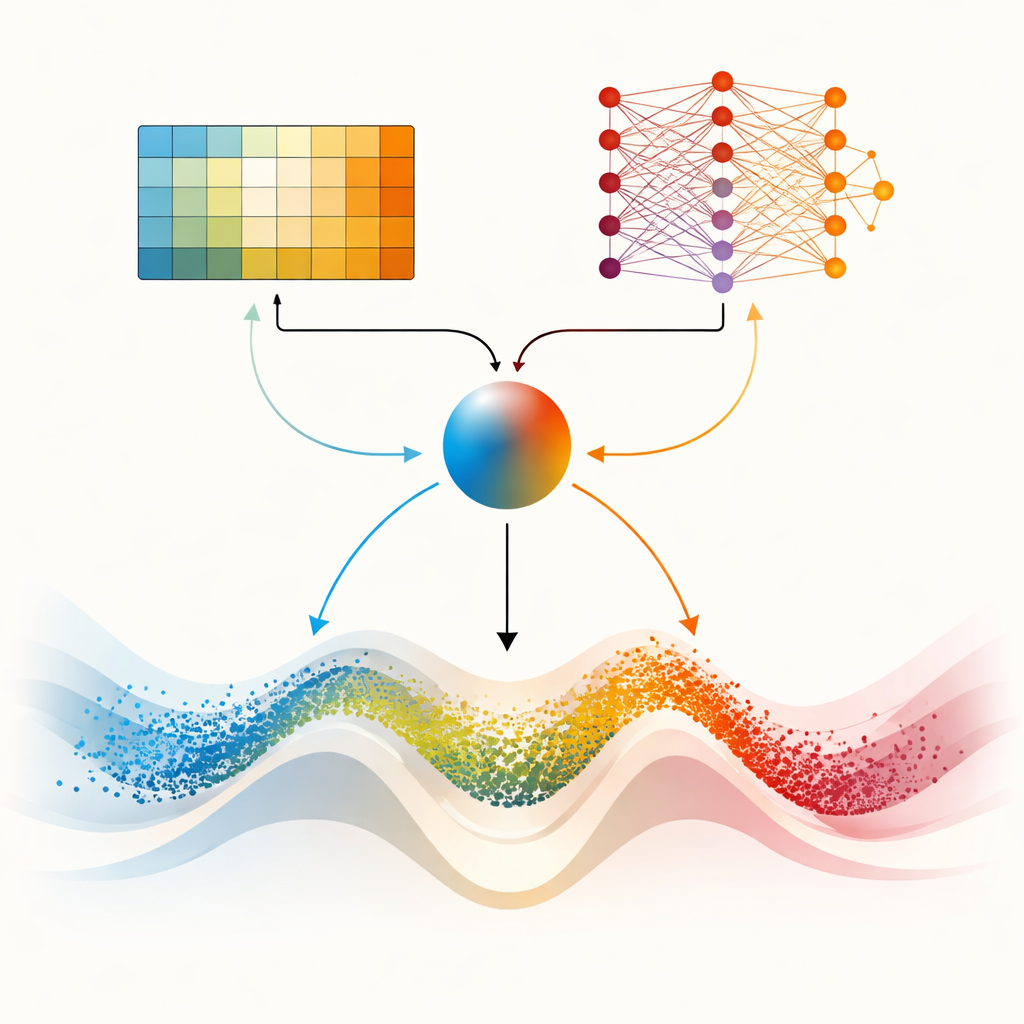
Два «мозга» для более сложных ландшафтов
Центральная часть статьи — DMARS_WGO, который идёт дальше, наделяя оптимизатор двумя дополняющимися обучающими «мозгами». Один — тот самый табличный Q‑алгоритм из AIRE_WGO, простой и быстрый, когда ситуацию можно описать несколькими грубыми категориями. Второй — Deep Q‑Network, небольшая нейронная сеть, способная улавливать более тонкие закономерности в том, как разнообразие, скорость улучшения и застой связаны с хорошими решениями. На каждой итерации оба обучателя предлагают, что делать — склоняться к роению в духе газели, фокусировке в духе моржа или к их смешению. Коэффициент смешения, вычисляемый по текущему разнообразию, недавнему прогрессу и признакам застоя, плавно объединяет их предложения в единое действие. Информация течёт в обе стороны: опыт простого обучателя обогащает обучающую выборку нейросети, а дистиллированные знания из сети периодически уточняют таблицу простого обучателя. Такое кооперативное устройство помогает оптимизатору адаптироваться непрерывно, а не переключаться резко.
Тестирование метода
Чтобы проверить, действительно ли эта дополнительная «интеллектуальность» оправдана, авторы протестировали DMARS_WGO на двух широко используемых наборах тестов (CEC 2017 и CEC 2022) и на шести реальных инженерных задачах, включая пружины, сосуды под давлением, зубчатые передачи и опорные конструкции. Эти задачи намеренно сложные, с множеством вводящих в заблуждение локальных оптимумов и строгими ограничениями проектирования. На десятках тест‑функций DMARS_WGO чаще всего достигает наилучшего среднего результата и демонстрирует высокую стабильность от запуска к запуску. Статистические тесты подтверждают, что его преимущества над девятью другими современными оптимизаторами вряд ли случайны. Важно, что улучшение производительности не сопровождается неприемлемыми вычислительными затратами: хотя обучение нейросети добавляет некоторый оверхед, общая стоимость по‑прежнему определяется оценкой кандидатных решений, как и в стандартных ройных методах.
Что это значит на практике
Для неспециалиста ключевой итог таков: DMARS_WGO ведёт себя как поисковая команда, которая учится в реальном времени, как лучше распределять время между разведкой новой территории и тщательным изучением перспективных находок. Тщательно отслеживая признаки прогресса и признаки застоя и позволяя двум разным обучающим модулям направлять свои шаги, алгоритм может надёжнее находить высококачественные решения в трудных высокоразмерных пространствах. Это делает его привлекательным компонентом для будущих инженерных инструментов, которые должны автоматически настраивать сложные системы — от механических компонентов до моделей машинного обучения — без необходимости постоянного микроменеджмента со стороны эксперта.
Цитирование: Yousif, N.R., El-Gendy, E.M. & Haikal, A.Y. DMARS_WGO: a deep reinforcement-driven hybrid metaheuristic for intelligent adaptive optimization. Sci Rep 16, 13156 (2026). https://doi.org/10.1038/s41598-026-46134-4
Ключевые слова: метаэвристическая оптимизация, обучение с подкреплением, роевая интеллигенция, инженерное проектирование, глубокие Q‑сети