Clear Sky Science · pt
DMARS_WGO: um metaheurístico híbrido impulsionado por aprendizado por reforço profundo para otimização adaptativa inteligente
Busca mais inteligente para problemas complexos
De projetar peças de aeronaves mais leves a ajustar modelos de aprendizado de máquina, muitos desafios modernos se reduzem à mesma pergunta: como explorar enormes espaços de possibilidades para encontrar uma solução realmente boa? Este artigo apresenta um novo tipo de motor de busca “inteligente”, chamado DMARS_WGO, que aprende com a experiência durante a exploração, ajudando engenheiros e cientistas a alcançar projetos melhores mais rápido e com maior confiabilidade.
Por que métodos comuns ficam aquém
Técnicas tradicionais de otimização, como gradiente descendente e programação linear, funcionam bem apenas quando o terreno de possibilidades é suave e bem comportado. Problemas reais de engenharia raramente são assim. Eles costumam estar repletos de muitos picos e vales, penhascos súbitos e dobras em alta dimensionalidade. Em paisagens tão acidentadas, métodos clássicos podem facilmente ficar presos em uma colina próxima em vez de encontrar o vale mais profundo — a verdadeira melhor solução. Nas últimas décadas, pesquisadores recorreram às chamadas metaheurísticas, algoritmos inspirados na natureza, na física e no comportamento humano. Esses métodos movem enxames de soluções candidatas pelo espaço, imitando bandos de pássaros, predadores caçando ou materiais resfriando. Embora poderosos, muitos desses procedimentos ainda têm dificuldade em equilibrar duas necessidades concorrentes: ampla exploração de novo território e exploração cuidadosa de regiões promissoras.
Duas metáforas animais, uma ideia central
Os autores se baseiam em dois otimizadores inspirados em animais: o Walrus Optimizer, eficiente em ajuste fino ao redor de pontos atraentes (exploração local), e o Gazelle Optimization Algorithm, que se destaca na exploração ampla e ágil (exploração global). Trabalhos anteriores já tinham combinado esses comportamentos em métodos híbridos, mas a mistura era amplamente codificada rigidamente: fórmulas ou cronogramas fixos decidiam quando vagar e quando focar. Essa rigidez faz com que o algoritmo ainda possa tirar conclusões precipitadas ou vagar sem rumo por tempo demais, especialmente em problemas muito complexos ou de alta dimensionalidade. O novo trabalho reimagina esse híbrido morsa–gazela como um sistema que não apenas se move, mas também aprende como se mover com base no feedback da própria busca.
Adicionando aprendizado ao enxame
O primeiro método proposto, AIRE_WGO, introduz um mecanismo de aprendizado chamado Q‑learning. Em vez de seguir um roteiro fixo, o algoritmo observa sinais simples de sua população de soluções candidatas: quão dispersas elas estão (diversidade) e quão rapidamente a melhor solução está melhorando. Essas observações definem o “estado” atual da busca. Para cada estado, o módulo de Q‑learning descobre gradualmente se é melhor favorecer a exploração ao estilo da gazela ou a exploração local ao estilo da morsa. Decisões bem‑sucedidas — aquelas que levam a melhores soluções — são recompensadas, fazendo com que o sistema seja mais propenso a repeti‑las em situações semelhantes. O AIRE_WGO ajusta ainda seus tamanhos de passo internos e introduz mutações randômicas controladas quando o progresso estagna, ajudando a escapar de becos sem saída.
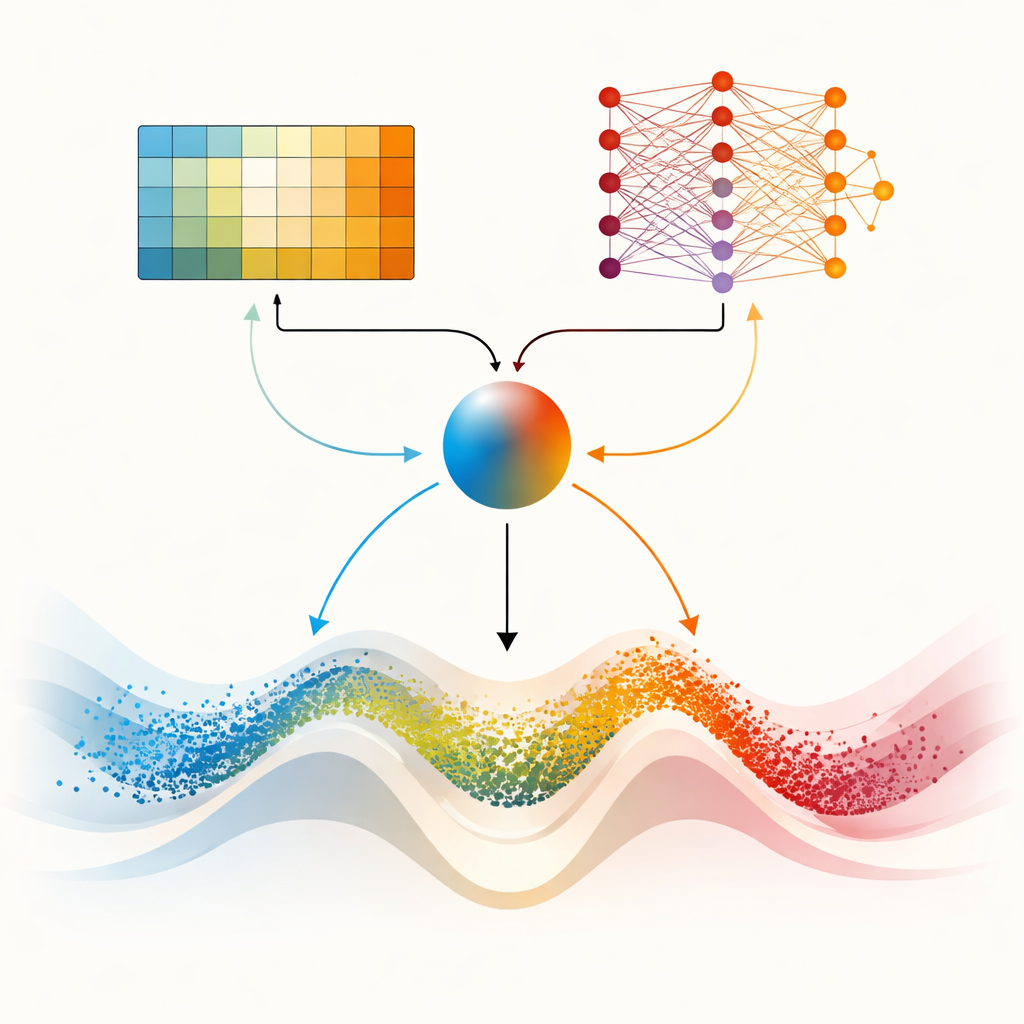
Dois cérebros para paisagens mais difíceis
O centro do artigo é o DMARS_WGO, que vai além ao dotar o otimizador de dois “cérebros” de aprendizado complementares. Um é o mesmo Q‑learning tabular usado no AIRE_WGO, simples e rápido quando a situação pode ser resumida em poucas categorias grosseiras. O outro é uma Deep Q‑Network, uma pequena rede neural capaz de capturar padrões mais sutis sobre como diversidade, taxa de melhoria e estagnação se relacionam com boas decisões. A cada iteração, ambos os aprendizes propõem o que fazer — favorecer o roaming ao estilo da gazela, o foco ao estilo da morsa, ou uma mistura dos dois. Um coeficiente de mistura, calculado a partir da diversidade atual, do progresso recente e de sinais de atolamento, pondera suavemente suas sugestões em uma única ação. A informação também flui nos dois sentidos: experiências do aprendiz mais simples enriquecem os dados de treinamento da rede neural, enquanto o conhecimento destilado da rede periodicamente refina a tabela de decisão do aprendiz simples. Essa configuração cooperativa ajuda o otimizador a adaptar seu comportamento continuamente em vez de alternar abruptamente.
Colocando o método à prova
Para verificar se essa inteligência adicional realmente compensa, os autores avaliaram o DMARS_WGO em duas suítes de teste amplamente usadas (CEC 2017 e CEC 2022) e em seis tarefas reais de projeto de engenharia, incluindo molas, vasos de pressão, trens de engrenagens e estruturas de suporte. Esses problemas são deliberadamente desafiadores, com muitos ótimos locais enganosos e restrições rígidas de projeto. Em dezenas de funções de teste, o DMARS_WGO frequentemente alcança o melhor desempenho médio e mostra resultados muito estáveis de execução para execução. Testes estatísticos confirmam que suas vantagens sobre nove outros otimizadores avançados dificilmente são devidas ao acaso. Importante: essa melhoria de desempenho não vem com um custo computacional proibitivo — embora treinar uma rede neural acrescente alguma sobrecarga, o esforço total ainda é dominado pela avaliação de designs candidatos, assim como em métodos de enxame padrão.
O que isso significa na prática
Para um público não especializado, o resultado-chave é que o DMARS_WGO se comporta como uma equipe de busca que aprende, em tempo real, como dividir melhor seu tempo entre explorar novos territórios e examinar em detalhe descobertas promissoras. Ao monitorar cuidadosamente sinais de progresso e de estagnação, e ao deixar dois módulos de aprendizado diferentes guiarem seus movimentos, o algoritmo pode convergir de forma mais confiável para projetos de alta qualidade em espaços difíceis e de alta dimensionalidade. Isso o torna um bloco de construção atraente para futuras ferramentas de engenharia que precisem ajustar automaticamente sistemas complexos — de componentes mecânicos a modelos de aprendizado de máquina — sem exigir que um especialista humano microgerencie cada etapa da busca.
Citação: Yousif, N.R., El-Gendy, E.M. & Haikal, A.Y. DMARS_WGO: a deep reinforcement-driven hybrid metaheuristic for intelligent adaptive optimization. Sci Rep 16, 13156 (2026). https://doi.org/10.1038/s41598-026-46134-4
Palavras-chave: otimização por metaheurística, aprendizado por reforço, inteligência de enxames, projeto de engenharia, redes Q profundas