Clear Sky Science · nl
DMARS_WGO: een door diepe versterkende leren aangedreven hybride metaheuristiek voor intelligente adaptieve optimalisatie
Slimmer zoeken voor complexe problemen
Van het ontwerpen van lichtere vliegtuigonderdelen tot het afstemmen van machine‑learningmodellen: veel moderne uitdagingen komen neer op dezelfde vraag: hoe doorzoeken we enorme mogelijkhedenruimten om één echt goede oplossing te vinden? Dit artikel introduceert een nieuw soort "slimme" zoekmachine, genaamd DMARS_WGO, die leert van ervaring tijdens het verkennen en zo ingenieurs en wetenschappers helpt sneller tot betere ontwerpen te komen en dat met grotere betrouwbaarheid.
Waarom gewone methoden tekortschieten
Traditionele optimalisatietechnieken, zoals gradient descent en lineaire programmering, werken goed alleen wanneer het terrein van mogelijkheden glad en goed gedisciplineerd is. Echte technische problemen zien er zelden zo uit. Ze zitten vaak vol pieken en dalen, abrupte kliffen en ingewikkelde hoge-dimensionale wendingen. In dergelijke grillige landschappen kunnen klassieke methoden gemakkelijk vastlopen op een naburige heuvel in plaats van het diepste dal te vinden—de werkelijke beste oplossing. In de afgelopen decennia zijn onderzoekers daarom uitgeweken naar zogenoemde metaheuristieken, algoritmen geïnspireerd door de natuur, de fysica en menselijk gedrag. Deze methoden verplaatsen zwermen kandidaatoplossingen door het landschap, waarbij ze vogels die in formatie vliegen, jagende roofdieren of afkoelende materialen nabootsen. Hoewel krachtig, vinden veel van deze technieken het nog steeds moeilijk om twee concurrerende behoeften in balans te houden: brede verkenning van nieuw gebied en zorgvuldige uitbuiting van veelbelovende regio’s.
Twee dierenmetaforen, één kernidee
De auteurs bouwen voort op twee recente door dieren geïnspireerde optimizers: de Walrus Optimizer, die goed is in verfijning rond aantrekkelijke plekken (uitbuiting), en het Gazelle Optimization Algorithm, dat uitblinkt in ruim, behendig rondzwerven (verkenning). Eerder werk had deze gedragingen al gecombineerd tot hybride methoden, maar de mix was grotendeels hardgecodeerd: vaste formules of schema’s bepaalden wanneer te zwerven en wanneer te focussen. Die rigiditeit betekent dat het algoritme nog steeds te snel conclusies kan trekken of juist te lang doelloos kan blijven ronddwalen, vooral bij zeer complexe of hoge-dimensionale problemen. Het nieuwe werk herinterpreteert dit walrus–gazelle‑hybride als een systeem dat niet alleen beweegt, maar ook leert hoe het zich moet bewegen op basis van feedback uit de zoekactie zelf.
Leren toevoegen aan de zwerm
De eerste voorgestelde methode, AIRE_WGO, introduceert een leermechanisme genaamd Q‑learning. In plaats van een vast script te volgen, observeert het algoritme eenvoudige signalen van zijn populatie kandidaatoplossingen: hoe verspreid ze zijn (diversiteit) en hoe snel de beste oplossing verbetert. Deze observaties definiëren de huidige "staat" van de zoektocht. Voor elke staat ontdekt de Q‑learningmodule geleidelijk of het beter is om gazelle‑achtige verkenning of walrus‑achtige uitbuiting te prefereren. Succesvolle beslissingen—die leiden tot betere oplossingen—worden beloond, zodat het systeem geneigd raakt die in vergelijkbare situaties te herhalen. AIRE_WGO past bovendien zijn interne stapgroottes aan en introduceert gecontroleerde willekeurige mutaties wanneer de voortgang stagneert, wat helpt om uit doodlopende paden te ontsnappen.
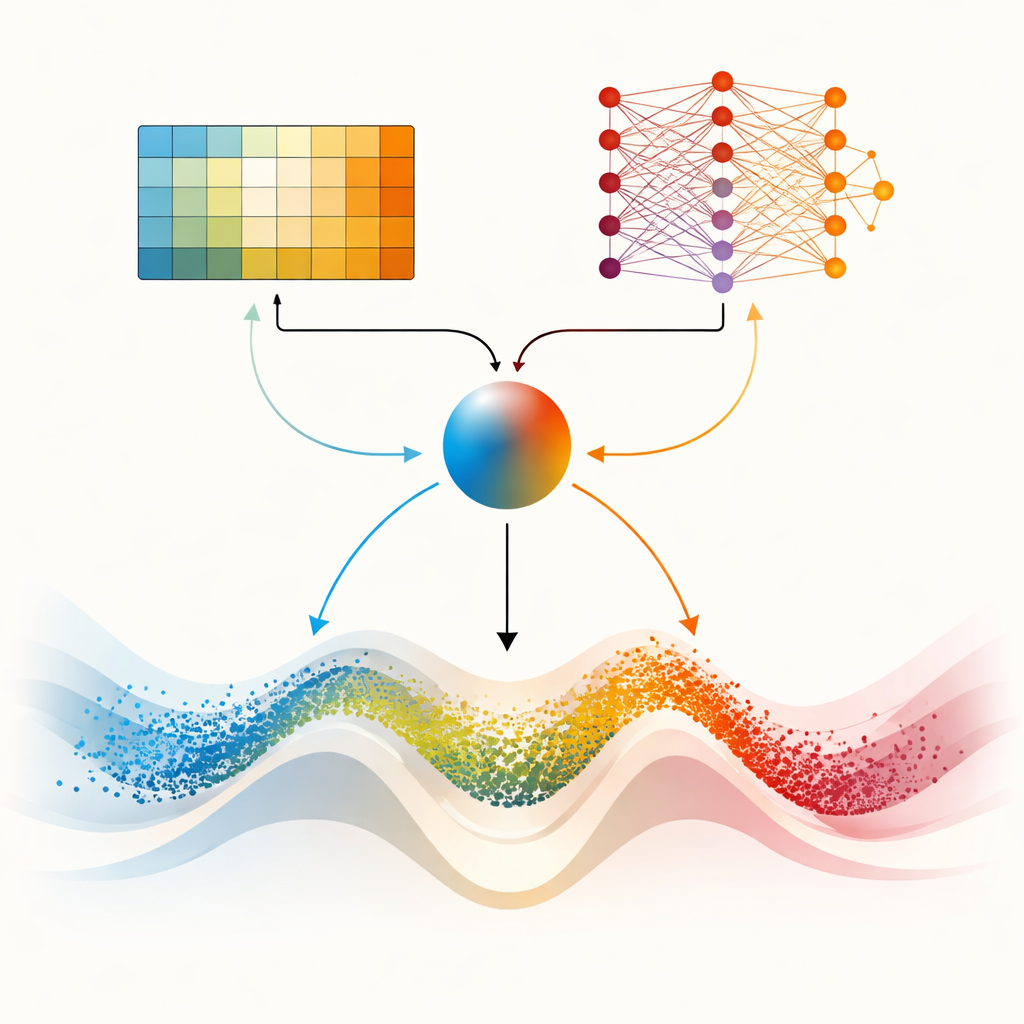
Twee breinen voor zwaardere landschappen
Het middelpunt van het artikel is DMARS_WGO, dat een stap verder gaat door de optimizer twee complementaire leer"breinen" te geven. De ene is dezelfde tabelgebaseerde Q‑learning die in AIRE_WGO wordt gebruikt, eenvoudig en snel wanneer de situatie in een paar ruwe categorieën kan worden samengevat. De andere is een Deep Q‑Network, een klein neuraal netwerk dat subtielere patronen kan vastleggen in hoe diversiteit, verbeteringssnelheid en stagnatie samenhangen met goede beslissingen. Bij elke iteratie doen beide leerlingen een voorstel—neigen naar gazelle‑achtig zwerven, walrus‑achtig focussen of een mengvorm van beide. Een mengcoëfficiënt, berekend uit huidige diversiteit, recente voortgang en tekenen van vastlopen, weegt hun suggesties soepel samen tot één actie. Informatie stroomt ook beide kanten op: ervaringen van de eenvoudigere leerling verrijken de trainingsdata van het neurale netwerk, terwijl gedistilleerde kennis uit het netwerk periodiek de besluitentabel van de eenvoudigere leerling verfijnt. Deze samenwerkende opzet helpt de optimizer zijn gedrag continu aan te passen in plaats van abrupt te schakelen.
De methode op de proef stellen
Om te onderzoeken of deze extra intelligentie echt rendeert, toetsen de auteurs DMARS_WGO op twee veelgebruikte testsuites (CEC 2017 en CEC 2022) en op zes echte technische ontwerptaken, waaronder veren, drukvaten, tandwielkasten en draagstructuren. Deze problemen zijn bewust uitdagend, met veel misleidende lokale optima en strikte ontwerprichtlijnen. Over tientallen testfuncties behaalt DMARS_WGO het vaakst de beste gemiddelde prestaties en laat het zeer stabiele resultaten van run tot run zien. Statistische toetsen bevestigen dat de voordelen ten opzichte van negen andere geavanceerde optimizers waarschijnlijk niet toe te schrijven zijn aan toeval. Belangrijk is dat deze verbeterde prestaties niet komen met een te hoge rekencost: hoewel het trainen van een neuraal netwerk extra overhead met zich meebrengt, wordt de totale inspanning nog steeds vooral bepaald door het evalueren van kandidaatontwerpen, net zoals bij standaard zwermmethoden.
Wat dit in de praktijk betekent
Voor niet‑specialisten is de belangrijkste uitkomst dat DMARS_WGO zich gedraagt als een zoekteam dat ter plekke leert hoe het zijn tijd het beste verdeelt tussen verkennen van nieuw terrein en het nauwgezet onderzoeken van veelbelovende vondsten. Door zorgvuldig voortgangs- en stagnatiesignalen te monitoren, en door twee verschillende leermodules de richting te laten bepalen, kan het algoritme betrouwbaarder op hoge‑kwaliteit ontwerpen uitkomen in moeilijke, hoge-dimensionale ruimtes. Dat maakt het een aantrekkelijke bouwsteen voor toekomstige technische tools die complexe systemen automatisch moeten afstemmen—van mechanische componenten tot machine‑learningmodellen—zonder dat een menselijke expert elke zoekstap hoeft te micromanagen.
Bronvermelding: Yousif, N.R., El-Gendy, E.M. & Haikal, A.Y. DMARS_WGO: a deep reinforcement-driven hybrid metaheuristic for intelligent adaptive optimization. Sci Rep 16, 13156 (2026). https://doi.org/10.1038/s41598-026-46134-4
Trefwoorden: metaheuristische optimalisatie, versterkend leren, zwermintelligentie, technisch ontwerp, deep Q-netwerken