Clear Sky Science · sv
Få-exempel-klassificering av Android-mjukvara med kvantförstärkt prototypinlärning och driftupptäckt
Stoppa skadliga appar innan de sprids
De flesta av oss bär en kraftfull dator i fickan, och den bekvämligheten medför en dold kapplöpning: säkerhetsteam som försöker upptäcka ny Android-mjukvara så snabbt brottslingar hittar på den. Traditionella försvar behöver tusentals kända skadliga appar för att lära sig vad som ska blockeras, vilket är alltför långsamt när helt nya malwarefamiljer dyker upp varje vecka. Denna artikel presenterar en smartare detektor som kan lära sig från bara ett fåtal exempel, hänga med när attacker utvecklas över tid och ändå förklara varför den flaggar en viss app — ett mönster för mer motståndskraftigt skydd på vanliga telefoner.
Varför nya hot är så svåra att fånga
Android dominerar nu den globala telefonmarknaden, vilket gör det till ett lukrativt mål för malwareförfattare som producerar hundratusentals nya prover dagligen. Verkliga dataset är skeva: ett fåtal malwarefamiljer innehåller stora mängder appar, medan många framväxande familjer har färre än tio kända prover. Dessutom ändrar angripare ständigt sina taktiker, vilket får datans statistiska ”form” att driva över månader och år. Klassiska maskininlärningssystem som tränas en gång på högdimensionella tekniska egenskaper har svårt i detta läge: de behöver många etiketterade exempel av varje familj, blir sköra när hotlandskapet skiftar och omträning från grunden är kostsam och tidskrävande.
Lära sig från bara några få skadliga exempel
Författarna föreslår ett ramverk som behandlar malwareupptäckt mer som att lära sig en känsla för ”likhet” än att memorera etiketter. Efter att ha förkortat de råa Android-egenskaperna med ungefär 95–99 % med en teknik kallad CatBoost, matar systemet dessa kompakta beskrivningar in i ett ”prototypiskt” nätverk. Under träningen löser nätverket upprepade gånger små övningsuppgifter där det måste särskilja ett par klasser med bara några exempel av varje. Med tiden lär det sig en intern karta där appar från samma familj hamnar nära varandra och olika familjer bildar välavgränsade kluster. Vid driftsättning behöver säkerhetsanalytiker bara omkring fem bekräftade prover av en ny malwarefamilj: systemet genomsnittar deras positioner för att bilda en prototyp och klassificerar nya appar genom att kontrollera vilken prototyp de ligger närmast, vilket förvandlar ett datahungrigt problem till ett få-exempel-problem. 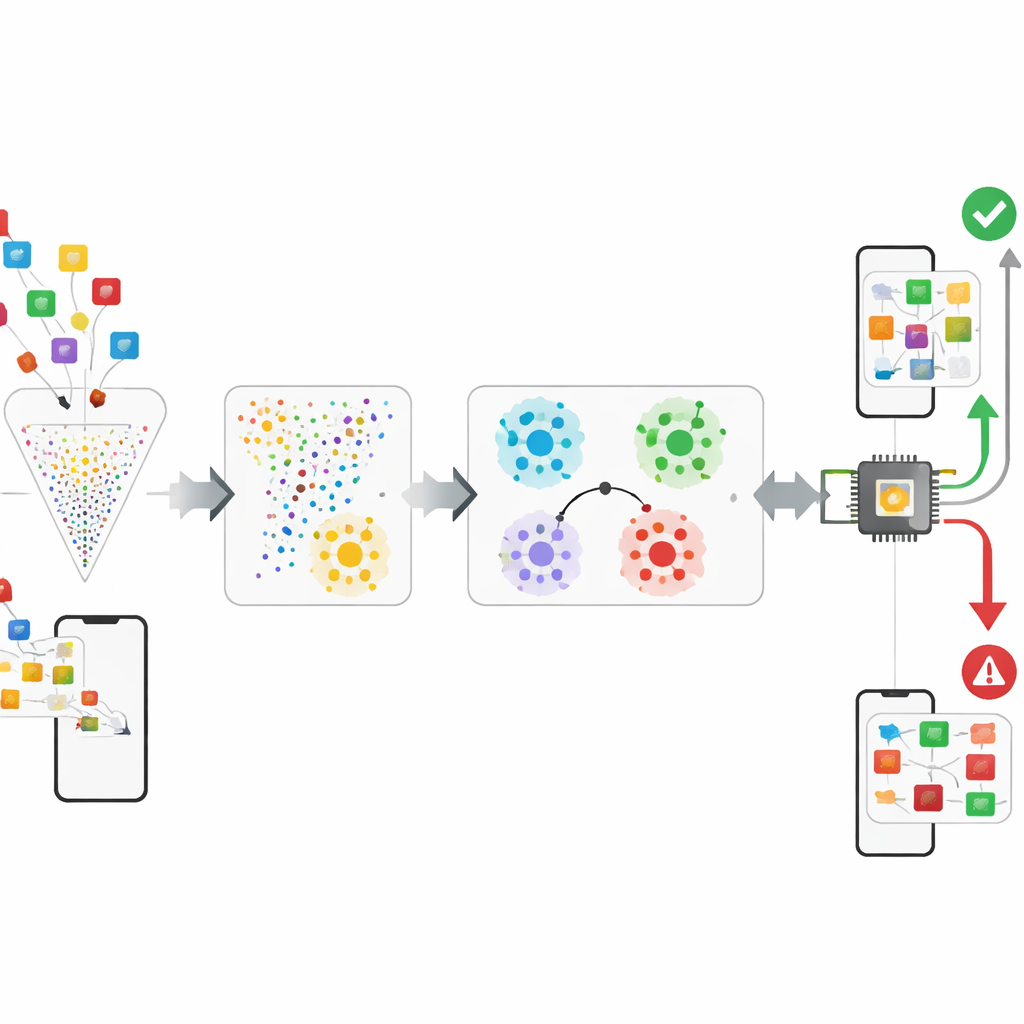
Lägga till kvantnyans och bevaka förändring
För att pressa fram mer insikt ur de redan komprimerade egenskaperna experimenterar ramverket med ett litet kvantinspirerat klassificeringslager. En fyr-kubits krets kodar en liten funktionsvektor till ett kvanttillstånd, sammanflätar kubitarna och mäter dem; ett enkelt klassiskt lager omvandlar sedan dessa mätningar till ett beslut. I simulering lägger detta hybridsteg till en måttlig men statistiskt signifikant förbättring i noggrannhet, vilket antyder att kvantenheter en dag kan hjälpa till att fånga subtila relationer mellan beteenden i en app. Samtidigt övervakar systemet uttryckligen hur väl det presterar över kronologiska snitt av data hämtade från ett tidsstämplat Android-dataset. Genom att träna på tidigare snitt och testa på senare kan det mäta hur mycket noggrannheten försämras när malwarens beteende drivit och flagga när omträning blir nödvändig.
Sätta metoden på prov
Forskarna utvärderar sitt ramverk på två stora publika dataset. Det ena, CCCS-CIC-AndMal-2020, innehåller hundratusentals Android-appar över många malwarefamiljer och godartade program, var och en beskriven av över 9 000 kod- och beteendefunktioner. Det andra, KronoDroid, erbjuder färre funktioner men innehåller tidsstämplar från 2008 till 2020, vilket gör det idealiskt för att följa förändring över tid. Efter funktionsval använder systemet endast 51 respektive 29 funktioner på dessa dataset, men når ändå omkring 99–100 % noggrannhet, med mycket låga falska larm- och missningsgrader. Det visar också att det kan klassificera helt undantagna malwarefamiljer med bara en liten prestandaavmattning, och att dess noggrannhet bara försämras marginellt över simulerade tidsperioder när periodisk omträning tillåts. 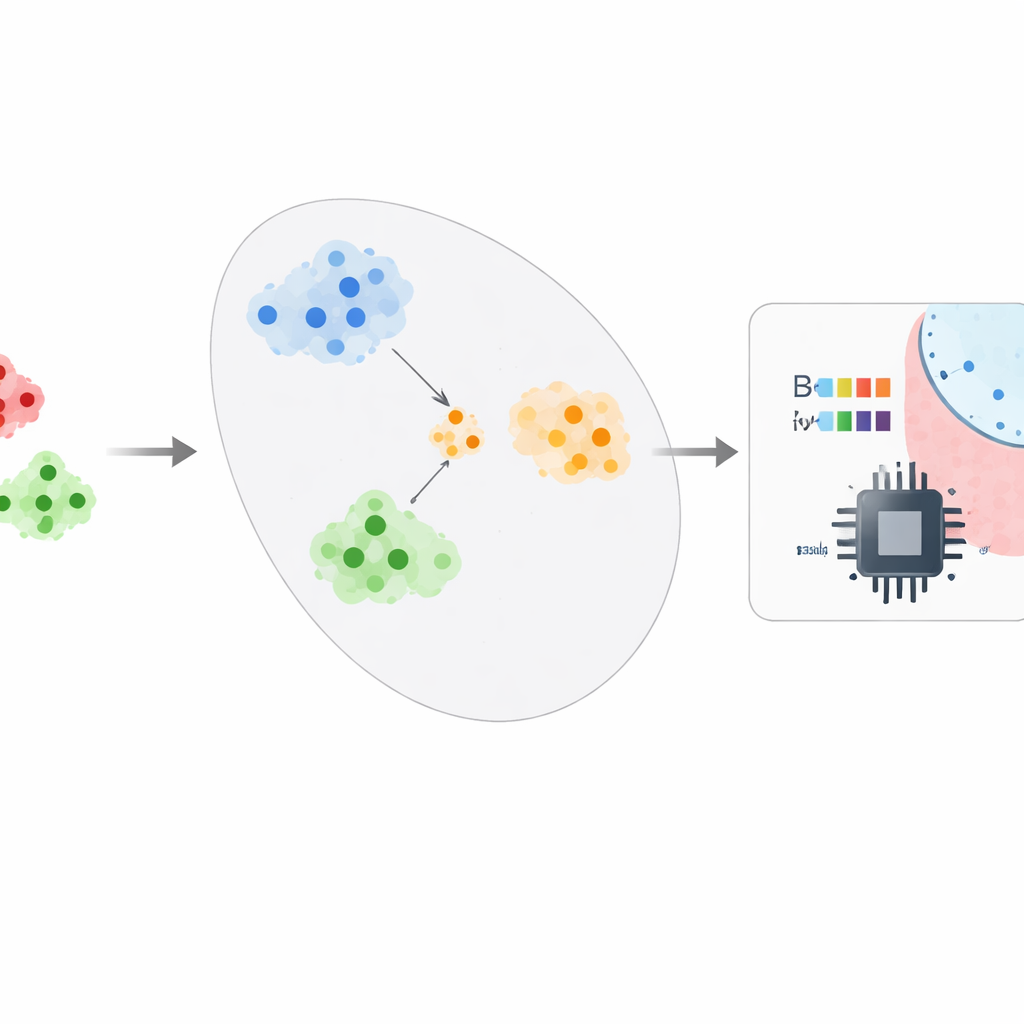
Se in i den svarta lådan
Utöver rena poäng använder författarna moderna förklaringsverktyg för att se vilka beteenden som mest påverkar besluten. De finner att lågnivåaktioner på filer — såsom hur appar manipulerar filbeskrivare eller skapar och byter namn på kataloger — är särskilt talande signaler för illvillig avsikt. Genom att markera, för varje flaggad app, vilka beteenden som drev prediktionen mot ”malware” eller ”godartad” ger systemet mänskliga analytiker ett sätt att granska och lita på dess bedömningar, och att förstå var smygande prover fortfarande slippar igenom. Denna analys blottlägger också kantfall: till exempel liknar vissa legitima filhanterare malware eftersom de utför intensiva filoperationer.
Vad detta betyder för vardaglig säkerhet
Enkelt uttryckt visar detta arbete att det är möjligt att bygga en Android-malwaredetektor som lär sig en generell ”känsla” för skadligt beteende, kan uppdateras snabbt med bara ett fåtal bekräftade prover av ett nytt hot och förblir pålitlig även när angripare gradvis ändrar sina metoder. Även om den kvantdel fortfarande är explorativ och testerna förlitar sig på kurerade dataset, pekar det övergripande ramverket mot framtida säkerhetsverktyg för telefoner som är lättare, snabbare att anpassa och mer transparenta i sitt resonemang — vilket hjälper försvarare att hålla takt med ett snabbt förändrande mobilt hotlandskap.
Citering: Tawfik, M., Tarazi, H., Dalalah, A. et al. Few-shot android malware classification with quantum-enhanced prototypical learning and drift detection. Sci Rep 16, 10744 (2026). https://doi.org/10.1038/s41598-026-45738-0
Nyckelord: Android-mjukvara, få-exempel-inlärning, kvantmaskininlärning, konceptdrift, cybersäkerhet