Clear Sky Science · fr
Classification de malwares Android en few-shot avec apprentissage prototypique amélioré par le quantique et détection de dérive
Arrêter les mauvaises applis avant leur propagation
La plupart d’entre nous transportent un ordinateur puissant dans leur poche, et cette commodité s’accompagne d’une course invisible : les équipes de sécurité doivent repérer les nouveaux malwares Android aussi vite que les cybercriminels les inventent. Les défenses traditionnelles ont besoin de milliers d’applications malveillantes connues pour apprendre ce qu’il faut bloquer, ce qui est bien trop lent lorsque de nouvelles familles de malwares apparaissent chaque semaine. Cet article présente un détecteur plus intelligent capable d’apprendre à partir de seulement quelques exemples, de suivre l’évolution des attaques dans le temps, et d’expliquer pourquoi il signale une application — offrant une feuille de route pour une protection plus résiliente sur les téléphones du quotidien.
Pourquoi les nouvelles menaces sont si difficiles à détecter
Android domine désormais le marché mondial des téléphones, ce qui en fait une cible lucrative pour les auteurs de malwares qui produisent des centaines de milliers de nouveaux échantillons chaque jour. Les jeux de données réels sont déséquilibrés : quelques familles de malwares contiennent un nombre énorme d’applications, tandis que de nombreuses familles émergentes comptent moins de dix échantillons connus. De plus, les attaquants modifient constamment leurs tactiques, provoquant une « forme » statistique des données qui dérive sur plusieurs mois et années. Les systèmes classiques d’apprentissage automatique entraînés une fois sur des caractéristiques techniques de haute dimension peinent dans ce contexte : ils exigent de nombreux exemples étiquetés pour chaque famille, deviennent fragiles quand le paysage des menaces change, et leur réentraînement complet est coûteux et lent.
Apprendre à partir de seulement quelques exemples malveillants
Les auteurs proposent un cadre qui traite la détection de malwares davantage comme l’apprentissage d’un sens de la « similarité » que comme la mémorisation d’étiquettes. Après avoir réduit les caractéristiques brutes Android d’environ 95 à 99 % à l’aide d’une technique appelée CatBoost, le système injecte ces descriptions compactes dans un réseau « prototypique ». Pendant l’entraînement, le réseau résout à répétition de petites tâches d’entraînement où il doit distinguer quelques classes en n’utilisant que quelques exemples de chacune. Avec le temps, il apprend une carte interne où les applications d’une même famille se retrouvent proches les unes des autres et où les familles différentes forment des grappes bien séparées. Au déploiement, les analystes de sécurité n’ont besoin que d’environ cinq échantillons confirmés d’une nouvelle famille de malwares : le système moyenne leurs positions pour former un prototype et classe les nouvelles applications en vérifiant le prototype le plus proche, transformant un problème gourmand en données en un problème few-shot. 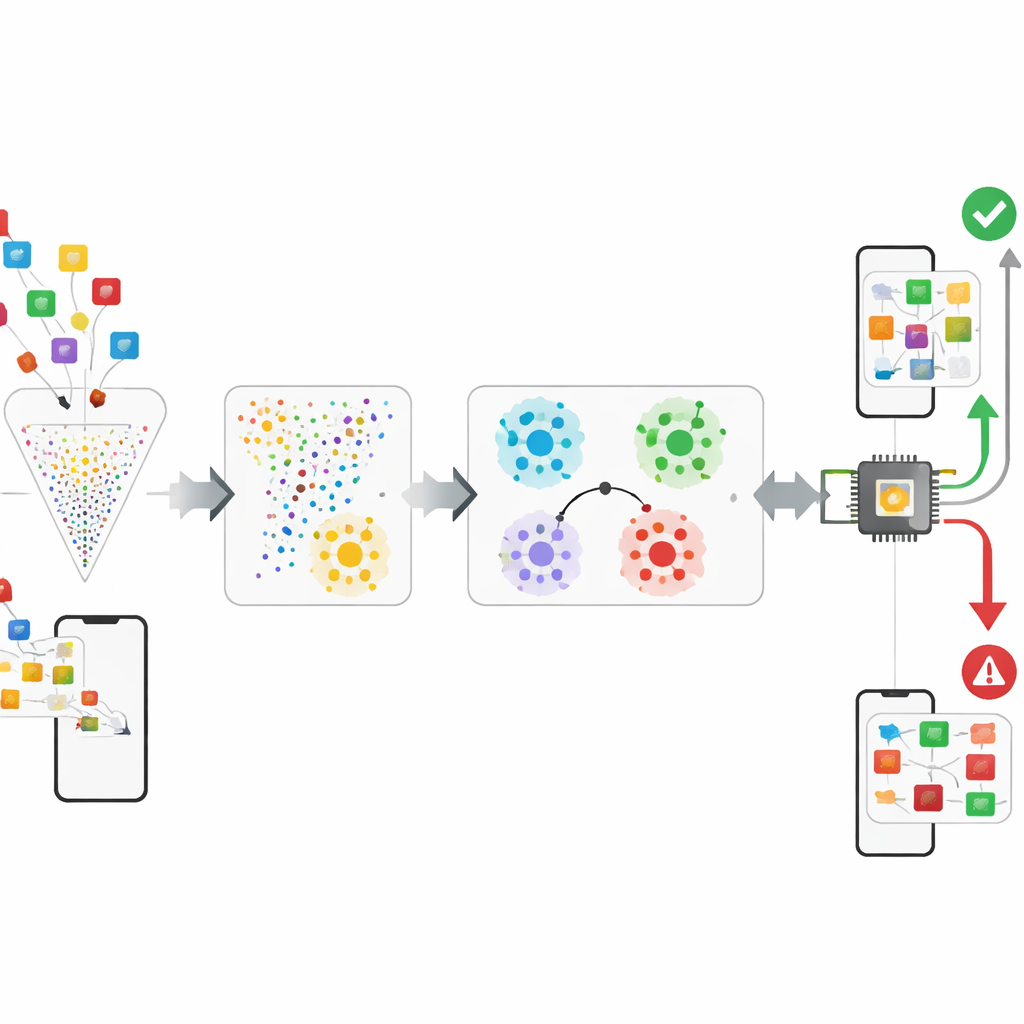
Ajouter une nuance quantique et surveiller le changement
Pour extraire plus d’information des caractéristiques déjà compressées, le cadre expérimente une petite couche de classification inspirée du quantique. Un circuit à quatre qubits encode un petit vecteur de caractéristiques en un état quantique, enchevêtre les qubits, puis les mesure ; une simple couche classique transforme ensuite ces mesures en décision. En simulation, cette étape hybride apporte un gain modeste mais statistiquement significatif en précision, laissant entendre que les dispositifs quantiques pourront un jour aider à capturer des relations subtiles entre les comportements d’une application. Parallèlement, le système surveille explicitement ses performances sur des tranches chronologiques de données extraites d’un jeu de données Android horodaté. En entraînant sur des tranches antérieures et en testant sur des tranches ultérieures, il peut mesurer combien la précision se détériore à mesure que le comportement des malwares dérive et signaler quand un réentraînement devient nécessaire.
Mettre l’approche à l’épreuve
Les chercheurs évaluent leur cadre sur deux grands jeux de données publics. Le premier, CCCS-CIC-AndMal-2020, contient des centaines de milliers d’applications Android couvrant de nombreuses familles de malwares et programmes bénins, chacune décrite par plus de 9 000 caractéristiques de code et de comportement. Le second, KronoDroid, propose moins de caractéristiques mais inclut des horodatages de 2008 à 2020, ce qui le rend idéal pour suivre l’évolution dans le temps. Après sélection des caractéristiques, le système n’utilise respectivement que 51 et 29 caractéristiques sur ces jeux de données, tout en atteignant encore environ 99–100 % de précision, avec des taux de fausses alertes et de détection manquée très faibles. Il montre également qu’il peut classer des familles de malwares entièrement tenues à l’écart avec seulement une petite baisse de performance, et que sa précision se dégrade très légèrement sur des périodes temporelles simulées lorsque des réentraînements périodiques sont autorisés. 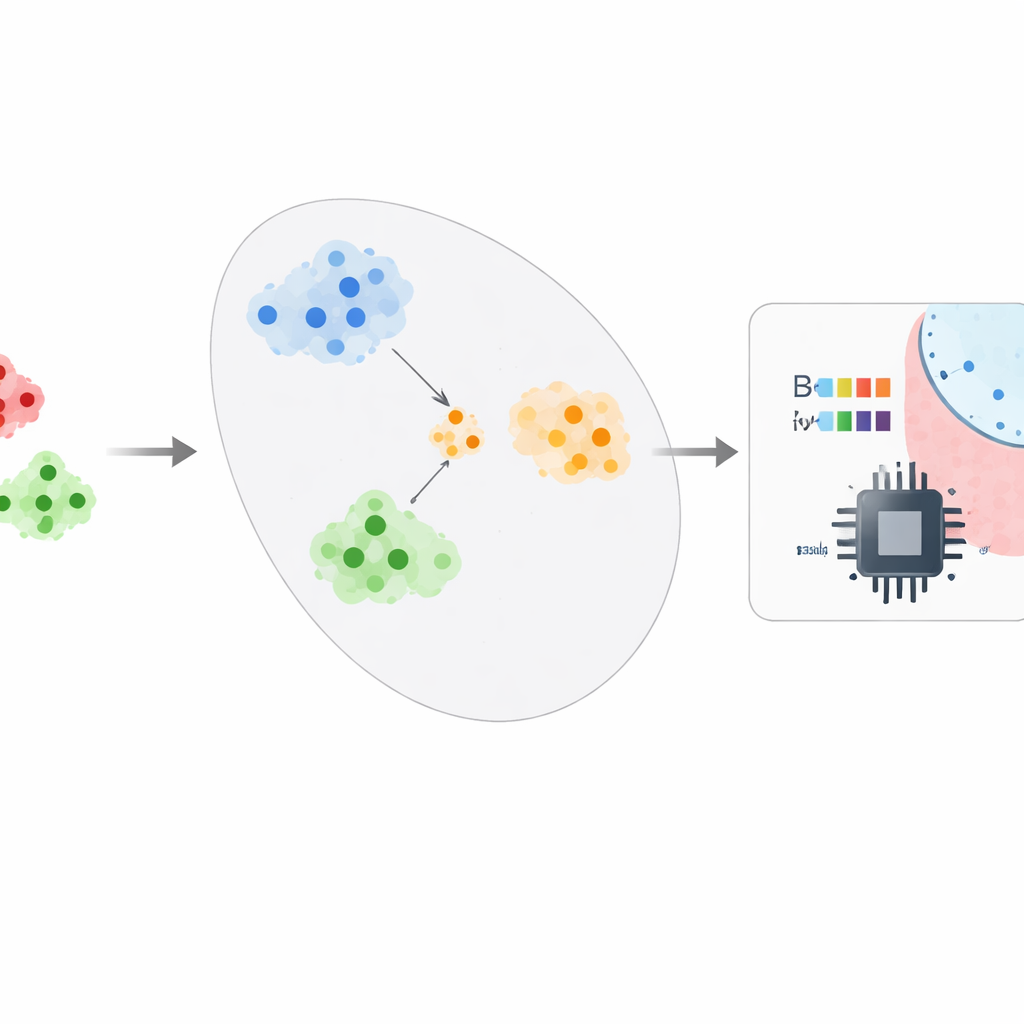
Regarder à l’intérieur de la boîte noire
Au-delà des scores bruts, les auteurs utilisent des outils modernes d’explicabilité pour voir quels comportements influencent le plus les décisions. Ils constatent que les actions bas niveau sur les fichiers — comme la façon dont les applications manipulent les descripteurs de fichiers ou créent et renomment des répertoires — sont des signaux particulièrement révélateurs d’une intention malveillante. En mettant en évidence, pour chaque application signalée, quels comportements ont poussé la prédiction vers « malware » ou « bénin », le système offre aux analystes humains un moyen d’auditer et de faire confiance à ses jugements, et de comprendre où des échantillons furtifs passent encore entre les mailles du filet. Cette analyse met aussi en lumière des cas limites : par exemple, certains gestionnaires de fichiers légitimes ressemblent à des malwares parce qu’ils effectuent des opérations intensives sur les fichiers.
Ce que cela signifie pour la sécurité au quotidien
En termes simples, ce travail montre qu’il est possible de construire un détecteur de malwares Android qui apprend une « sensation » générale du mauvais comportement, peut être mis à jour rapidement avec seulement quelques échantillons confirmés d’une nouvelle menace, et reste fiable même si les attaquants modifient progressivement leurs méthodes. Bien que la partie quantique soit encore exploratoire et que les tests reposent sur des jeux de données préparés, le cadre global indique la voie vers des outils de sécurité pour téléphones plus légers, plus rapides à adapter et plus transparents dans leur raisonnement — aidant les défenseurs à suivre le rythme d’un paysage de menaces mobiles en rapide évolution.
Citation: Tawfik, M., Tarazi, H., Dalalah, A. et al. Few-shot android malware classification with quantum-enhanced prototypical learning and drift detection. Sci Rep 16, 10744 (2026). https://doi.org/10.1038/s41598-026-45738-0
Mots-clés: Malware Android, apprentissage few-shot, apprentissage automatique quantique, dérive de concept, cybersécurité