Clear Sky Science · pl
Klasyfikacja złośliwych aplikacji Android w warunkach few-shot z wykorzystaniem kwantowo-wzmocnionego uczenia prototypowego i wykrywania dryfu
Powstrzymywanie złych aplikacji, zanim się rozprzestrzenią
Większość z nas nosi w kieszeni potężny komputer, a ta wygoda wiąże się z ukrytą rywalizacją: zespoły bezpieczeństwa starają się wykrywać nowe złośliwe aplikacje Android tak szybko, jak tylko przestępcy je wymyślą. Tradycyjne zabezpieczenia potrzebują tysięcy znanych złośliwych aplikacji, by nauczyć się, co blokować, co jest zbyt wolne, gdy co tydzień pojawiają się zupełnie nowe rodziny malware. W artykule zaproponowano inteligentniejszy detektor, który potrafi uczyć się na podstawie zaledwie kilku przykładów, nadążać za ewoluującymi atakami i jednocześnie wyjaśniać, dlaczego oznaczył daną aplikację — dając projekt bardziej odpornej ochrony na codziennych telefonach.
Dlaczego nowe zagrożenia są tak trudne do wykrycia
Android dominuje teraz na światowym rynku telefonów, co czyni go atrakcyjnym celem dla autorów malware, którzy generują setki tysięcy nowych próbek dziennie. Zbiory danych z rzeczywistości są zniekształcone: kilka rodzin malware zawiera ogromne liczby aplikacji, podczas gdy wiele pojawiających się rodzin ma mniej niż dziesięć znanych próbek. Dodatkowo napastnicy nieustannie zmieniają taktykę, powodując, że statystyczny „kształt” danych dryfuje w ciągu miesięcy i lat. Klasyczne systemy uczenia maszynowego trenowane jednokrotnie na wysokowymiarowych cechach technicznych mają w takim środowisku problemy: potrzebują wielu oznaczonych przykładów każdej rodziny, stają się kruche, gdy krajobraz zagrożeń się zmienia, a ponowne trenowanie od zera jest kosztowne i powolne.
Uczenie się na zaledwie kilku złych przykładach
Autorzy proponują ramy, które traktują wykrywanie malware bardziej jak naukę „podobieństwa” niż zapamiętywanie etykiet. Po zredukowaniu surowych cech Androida o około 95–99% przy użyciu techniki zwanej CatBoost, system wprowadza te skompaktowane opisy do sieci prototypowej. Podczas trenowania sieć wielokrotnie rozwiązuje małe zadania praktyczne, w których musi rozróżnić kilka klas, mając tylko po kilka przykładów każdej z nich. Z czasem uczy się wewnętrznej mapy, na której aplikacje z tej samej rodziny znajdują się blisko siebie, a różne rodziny tworzą dobrze rozdzielone klastry. W wdrożeniu analitycy bezpieczeństwa potrzebują jedynie około pięciu potwierdzonych próbek nowej rodziny malware: system uśrednia ich pozycje, tworząc prototyp, i klasyfikuje nowe aplikacje, sprawdzając, do którego prototypu są najbliżej, przekształcając problem wymagający dużej ilości danych w zadanie few-shot. 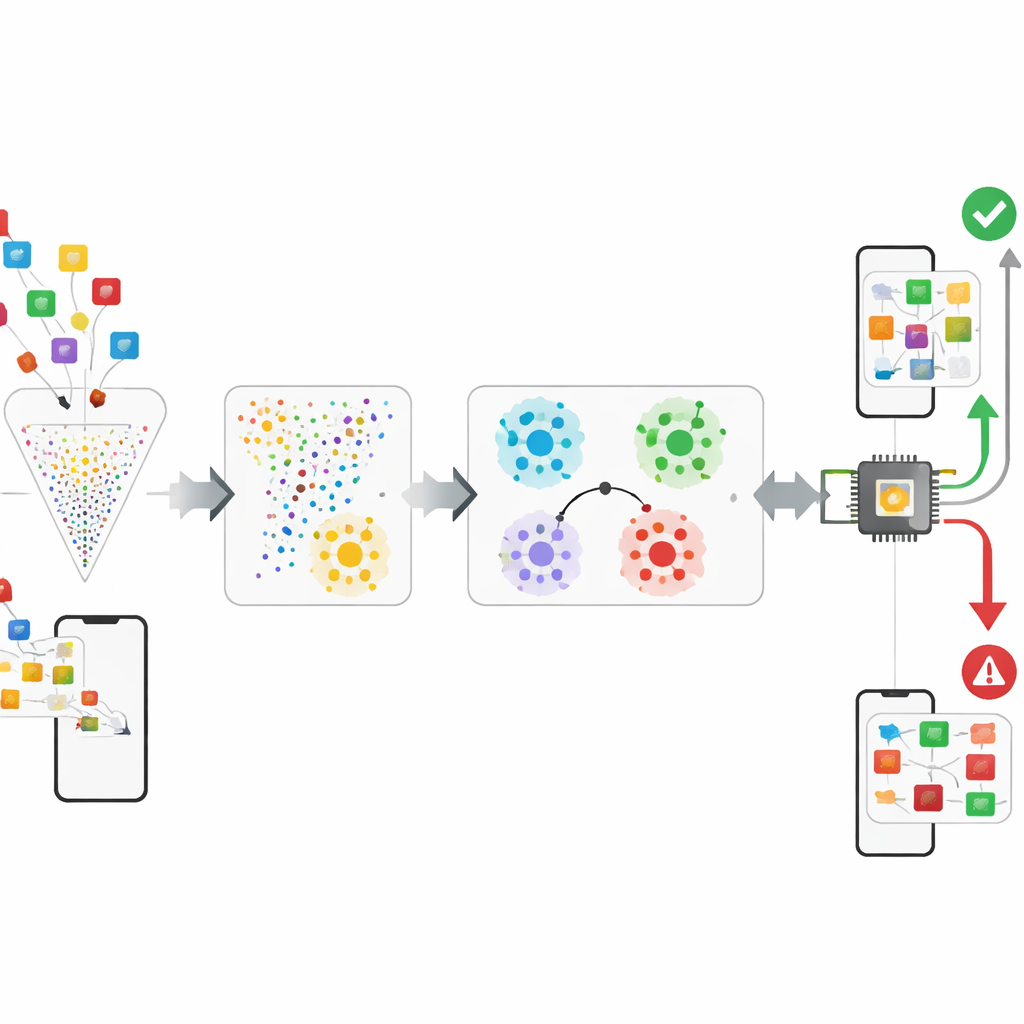
Dodanie kwantowego niuansu i monitorowanie zmian
Aby wydobyć więcej informacji z już skompresowanych cech, ramy eksperymentują z małą warstwą klasyfikacyjną inspirowaną kwantowo. Obwód czterech kubitów koduje niewielki wektor cech do stanu kwantowego, splątuje kubity, a następnie mierzy je; prosta warstwa klasyczna przekształca te pomiary w decyzję. W symulacji ten hybrydowy krok daje umiarkowany, lecz statystycznie istotny wzrost dokładności, sugerując, że urządzenia kwantowe mogą kiedyś pomóc wychwycić subtelne zależności między zachowaniami w aplikacji. Równocześnie system explicite monitoruje swoją wydajność w kolejnych przekrojach czasowych pochodzących ze znaczkowanego czasowo zestawu danych Android. Trenując na wcześniejszych przekrojach i testując na późniejszych, można zmierzyć, jak bardzo dokładność spada w miarę dryfu zachowań malware i wskazać moment, gdy konieczne staje się ponowne trenowanie.
Przetestowanie podejścia
Badacze ocenili swoje ramy na dwóch dużych publicznych zestawach danych. Jeden, CCCS-CIC-AndMal-2020, zawiera setki tysięcy aplikacji Android z wielu rodzin malware i programów nieszkodliwych, z których każda opisana jest ponad 9 000 cechami kodu i zachowania. Drugi, KronoDroid, oferuje mniej cech, ale zawiera znaczniki czasu od 2008 do 2020 roku, co czyni go idealnym do śledzenia zmian w czasie. Po selekcji cech system używał odpowiednio tylko 51 i 29 cech na tych zestawach danych, a mimo to osiągał około 99–100% dokładności, z bardzo niskimi wskaźnikami fałszywych alarmów i pominięć. Pokazał też, że potrafi klasyfikować całkowicie wydzielone rodziny malware z niewielkim spadkiem wydajności oraz że jego dokładność słabnie tylko nieznacznie w symulowanych okresach czasowych, gdy dopuszcza się okresowe ponowne trenowanie. 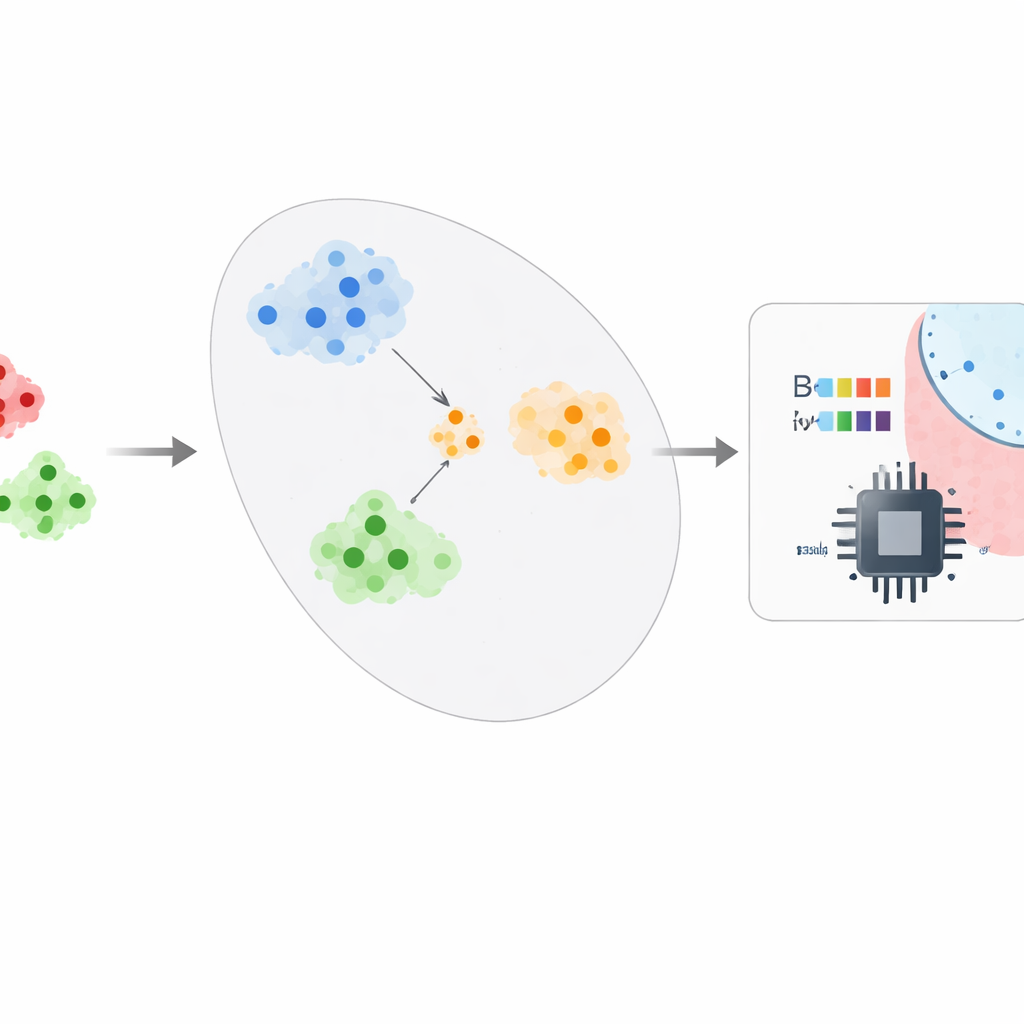
Zaglądanie do wnętrza czarnej skrzynki
Ponad surowymi wynikami, autorzy wykorzystują nowoczesne narzędzia wyjaśniające, by zobaczyć, które zachowania najsilniej wpływają na decyzje. Stwierdzili, że sygnały niskiego poziomu związane z operacjami na plikach — takie jak sposób, w jaki aplikacje manipulują deskryptorami plików czy tworzą i zmieniają nazwy katalogów — są szczególnie wymowne jako oznaki złośliwości. Poprzez wskazanie, dla każdej oznaczonej aplikacji, które zachowania przesunęły predykcję w stronę „malware” lub „nieszkodliwe”, system daje analitykom możliwość audytu i zaufania wobec jego ocen oraz zrozumienia, gdzie podstępne próbki wciąż się przeciskają. Ta analiza ujawnia też przypadki brzegowe: na przykład niektóre legalne menedżery plików przypominają malware, ponieważ wykonują intensywne operacje na plikach.
Co to oznacza dla codziennego bezpieczeństwa
Mówiąc prosto, praca ta pokazuje, że możliwe jest zbudowanie detektora malware dla Androida, który uczy się ogólnego „poczucia” złośliwego zachowania, może być szybko aktualizowany przy pomocy tylko kilku potwierdzonych próbek nowego zagrożenia i pozostaje niezawodny, nawet gdy napastnicy stopniowo zmieniają swoje sztuczki. Choć część kwantowa jest wciąż badawcza, a testy opierają się na wyselekcjonowanych zestawach danych, ogólne ramy wskazują na przyszłe narzędzia zabezpieczające telefony, które będą lżejsze, szybciej adaptowalne i bardziej transparentne w kwestii swojego rozumowania — pomagając obrońcom dotrzymać kroku szybko ewoluującemu krajobrazowi zagrożeń mobilnych.
Cytowanie: Tawfik, M., Tarazi, H., Dalalah, A. et al. Few-shot android malware classification with quantum-enhanced prototypical learning and drift detection. Sci Rep 16, 10744 (2026). https://doi.org/10.1038/s41598-026-45738-0
Słowa kluczowe: Złośliwe oprogramowanie Android, uczenie few-shot, kwantowe uczenie maszynowe, dryf pojęciowy, cyberbezpieczeństwo